


























Cvent interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
Cvent
4 rounds | 5 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 8 months
Topics: OOPS, DBMS, OS, Data Structures, System Design, Algorithms
Tip 1 : Revise everything you have written on your resume, Specially projects and skills.
Tip 2 : Do not rush into the optimal solution (unless directly asked) if you have already solved
the question, always give a quick brute force approach followed by optimizations.
Tip 3 : While coding, use meaningful variable names and write modular code.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Mention only those things which you actually know and have worked on the same.
Tip 2 : Mention project links in the resume.

Interview rounds
01
Round
Easy
Online Coding Interview
Duration60 Minutes
Interview date8 Oct 2020
Coding problem1
It was an Aptitude Round, conducted in the morning.
The time given was more than enough. Most of the questions were easy, just basic knowledge
is enough. There was no negative marking in this round.
1. MCQ Question
A system has 3 processes sharing 4 resources. If each process needs a maximum of 2 units then
a. deadlock can never occur
b. deadlock may occur
c. deadlock has to occur
d. None of these
Problem approach
Tip 1 : Do a thorough practice of the topics like OS, DBMS, System Design and DSA.
Tip 2 : Practice questions from the internet.
02
Round
Hard
Online Coding Interview
Duration60 Minutes
Interview date9 Oct 2020
Coding problem1
1. Smallest Window
Moderate
10m average time
90% success

0/80
Asked in companies
You are given two strings S and X containing random characters. Your task is to find the smallest substring in S which contains all the characters present in X.
Example:
Let S = “abdd” and X = “bd”.
The windows in S which contain all the characters in X are: 'abdd', 'abd', 'bdd', 'bd'.
Out of these, the smallest substring in S which contains all the characters present in X is 'bd'.
All the other substring have a length larger than 'bd'.
Problem approach
Step 1 : I had first taken two pointers, left and right initially pointing to the first element of the string s.
Step 2 : Then I used the right pointer to expand the window until I got a desirable window i.e. a window that contained all of the characters of t.
Step 3 : Once I had a window with all the characters, I moved the left pointer ahead one by one. If the window was still a desirable one, I kept on updating the minimum window size.
Step 4 : If the window was not desirable any more, I repeated step2 onwards.
This is how I was able to solve this problem.
03
Round
Medium
Online Coding Interview
Duration60 Minutes
Interview date10 Oct 2020
Coding problem1
1. LCA Of Binary Tree
Moderate
10m average time
90% success
0/80
Asked in companies

You have been given a Binary Tree of distinct integers and two nodes ‘X’ and ‘Y’. You are supposed to return the LCA (Lowest Common Ancestor) of ‘X’ and ‘Y’.
The LCA of ‘X’ and ‘Y’ in the binary tree is the shared ancestor of ‘X’ and ‘Y’ that is located farthest from the root.
Note :
You may assume that given ‘X’ and ‘Y’ definitely exist in the given binary tree.
For example :
For the given binary tree
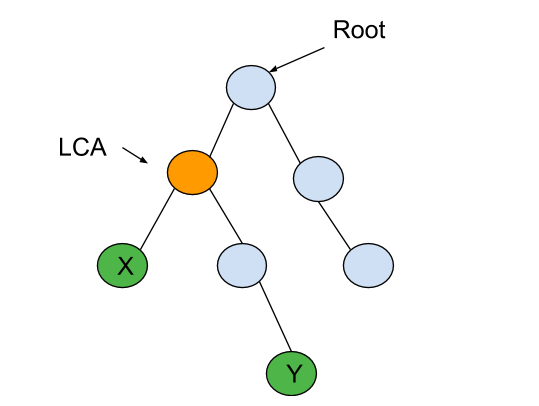
LCA of ‘X’ and ‘Y’ is highlighted in yellow colour.
Problem approach
Step 1 : I started with brute force and then gave him the optimal approach. Time and space complexities
were discussed for each solution. He asked me to code the optimal one.
Step 2 : So here is the algorithm I used to solve the question.
1. I started traversing the tree from the root node.
2. If the current node itself was one of p or q, I marked a variable mid as True and continued the search for the other node in the left and right branches.
3. If either of the left or the right branch returned True, this meant one of the two nodes was found below.
4. If at any point in the traversal, any two of the three flags left, right or mid became True, this meant I had found the lowest common ancestor for the nodes p and q.
So this was the approach I used to solve this problem.
04
Round
Easy
Online Coding Interview
Duration45 minutes
Interview date13 Oct 2020
Coding problem2
1. Set Matrix Zeros
Easy
30m average time
65% success
0/40
Asked in companies
You are given an N x M integer matrix. Your task is to modify this matrix in place so that if any cell contains the value 0, then all cells in the same row and column as that cell should also be set to 0.
Requirements:
- If a cell in the matrix has the value 0, set all other cells in that cell's row and column to 0.
- You should perform this modification in place (without using additional matrices).
You must do it in place.
For Example:
If the given grid is this:
[7, 19, 3]
[4, 21, 0]
Then the modified grid will be:
[7, 19, 0]
[0, 0, 0]
Problem approach
Step 1 : I used the intuition that if any cell of the matrix has a zero we can record its row and column number. All the cells of this recorded row and column can be marked zero in the next iteration.
Step 2 : Then I applied this intuition to find the index of all the zeros present in the matrix and stored them in an array. Then converted all the required elements to zero accordingly.
Step 3 : I was also asked the space and time complexity of the solution.
2. Duplicate Characters
Easy
25m average time
70% success
0/40
Asked in companies


You are given a string ‘S’ of length ‘N’. You have to return all the characters in the string that are duplicated and their frequency.
Example:-
N = 5
S = ‘GEEK’
ANSWER:- The answer should be [(‘E’,2)] because ‘E’ is the only character that is duplicated and has frequency 2.
Problem approach
Step 1 : Firstly I approached by brute force. I ran 2 loops with variables i and j. Compared str[i] and str[j]. If they became equal at any point, returned false. The time complexity of this approach was O(n2) (i.e. n squared).
Step 2 : Then I optimized it using sorting. In this I sorted the string with respect to the ASCII values of the characters. The time complexity in this case came out to be O(nlogn).


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
Which collection class forbids duplicates?
Choose another skill to practice
Similar interview experiences
SDE - 1
3 rounds | 10 problems
Interviewed by Cvent
Selected 1450 views
0 comments
0 upvotes
SDE - 1
3 rounds | 6 problems
Interviewed by Cvent
 Selected
Selected 1097 views
0 comments
0 upvotes
SDE - 1
3 rounds | 4 problems
Interviewed by Cvent
Selected 1053 views
0 comments
0 upvotes
SDE - 1
4 rounds | 7 problems
Interviewed by Cvent
Rejected
1313 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
5 rounds | 12 problems
Interviewed by Amazon
 Selected
Selected 116551 views
24 comments
0 upvotes
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 59304 views
5 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by Amazon
 Selected
Selected 35700 views
7 comments
0 upvotes