


























Google interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
Google
3 rounds | 7 Coding
problems

 Selected
Selected Interview preparation journey

Journey
In my second year, I did the course of competitive programming from Coding Ninjas, which helped me to dive deep into DSA, and then I started practicing problems on Codeforces, Codechef, and leetcode.
Application story
I applied through college or university. The process took multiple day. The event had three rounds mainly consisting of coding questions.
Why selected/rejected for the role?
They gave me two DSA questions which I solved and answered all Cs fundamental question they asked.
They also checks your OOPS skills
Preparation
Duration: 5 months
Topics: Data Structures - Trie, HashMap, Sets, Priority Queue, Stack, Advanced Topics like Fenwick Tree, Segment Trees, Game Theory, Dynamic Programming, Union Find, Graph Algorithms, Bitmasks
Tip 1 : Reading other’s interview experiences is one of the best ways to get yourselves ready for the next job interview. Practice daily atleast 5 questions.
Tip 2 : Most commonly asked topics in Google Interviews ( as per the mail I received from my recruiter ) :
BFS/DFS/Flood fill, Binary Search, Tree traversals, Hash tables, Linked list, stacks, queues, two pointers/sliding window
Binary heaps, Ad hoc/string manipulations.
Tip 3 : Highly recommended sites for practicing questions ( usually practice medium and hard level questions) -
Leetcode (highly encouraged)
Geeksforgeeks (highly encouraged)
CodeZen( highly encouraged)
Codeforces
Application process
Where: Campus
Eligibility: No Criteria
Tip 1 : Mention past working experience in detail as how you were important to your previous company.
Tip 2 : Try to keep your resume to 1 page if work experience < 5 years
Tip 3 : Update your resume according to role you are applying for and never put false things on resume.
Interview rounds
01
Round
Medium
Online Coding Test
Duration60 minutes
Interview date4 Dec 2020
Coding problem2
This round was held on Hackerearth from 2:00 PM to 3:00 PM
This round had 2 questions of easy/medium difficulty. Both were based on concepts of DP.
The use of offline IDE was prohibited so we were supposed to code it on Hackerearth IDE itself.
1. Min Steps to one using DP
Easy
15m average time
90% success

0/40
Asked in companies
You are given a positive integer 'N’. Your task is to find and return the minimum number of steps that 'N' has to take to get reduced to 1.
You can perform any one of the following 3 steps:
1) Subtract 1 from it. (n = n - 1) ,
2) If n is divisible by 2, divide by 2.( if n % 2 == 0, then n = n / 2 ) ,
3) If n is divisible by 3, divide by 3. (if n % 3 == 0, then n = n / 3 ).
For example:
Given:
‘N’ = 4, it will take 2 steps to reduce it to 1, i.e., first divide it by 2 giving 2 and then subtract 1, giving 1.
2. Longest Palindromic Substring
Moderate
20m average time
80% success
0/80
Asked in companies

You are given a string 'str' of length 'N'.
Your task is to return the longest palindromic substring. If there are multiple strings, return any.
A substring is a contiguous segment of a string.
For example :
str = "ababc"
The longest palindromic substring of "ababc" is "aba", since "aba" is a palindrome and it is the longest substring of length 3 which is a palindrome.
There is another palindromic substring of length 3 is "bab". Since starting index of "aba" is less than "bab", so "aba" is the answer.
02
Round
Medium
Video Call
Duration45 minutes
Interview date11 Dec 2020
Coding problem2
The round was held on Google Meet and I was given 2 coding problems for which first I had to explain my approach and then I had to write code in Shared Google Docs and dry run on sample test cases and discuss Time and Space Complexity.
There were 2 interviewers and both were very friendly and helpful and tried to bring us to our comfort level first.
1. Boyer Moore Algorithm for Pattern Searching
Moderate
30m average time
70% success
0/80
Asked in companies
You are given a string ‘text’ and a string ‘pattern’, your task is to find all occurrences of pattern in the string ‘text’ and return an array of indexes of all those occurrences. You may assume that the length of ‘text’ is always greater than the length of ‘pattern’.
For example :
Let text = “this is a good place to have a good start”, pattern = “good” so you have to return {10, 31} because at 10 and 31 index pattern is present in the text.
Note :
If there is no such index in the text then just return an array containing -1.
2. Median in a stream
Hard
50m average time
50% success
0/120
Asked in companies

Given that integers are read from a data stream. Your task is to find the median of the elements read so far.
Median is the middle value in an ordered integer list. If the size of the list is even there is no middle value. So the median is the floor of the average of the two middle values.
For example :
[2,3,4] - median is 3.
[2,3] - median is floor((2+3)/2) = 2.
03
Round
Hard
Online Coding Test
Duration90 minutes
Interview date17 Dec 2020
Coding problem3
This round was also virtual. It has some difficult questions when compared to the previous rounds.
This was also held on Google Meet with shared docs for writing code.
There were 2 interviewers and both were helpful.
1. Shortest alternate colored path
Moderate
20m average time
80% success
0/80
Asked in companies
Consider a directed graph of ‘N’ nodes where each node is labeled from ‘0’ to ‘N - 1’. Each edge of the graph is either ‘red’ or ‘blue’ colored. The graph may contain self-edges or parallel edges. You are given two arrays, ‘redEdges’ and ‘blueEdges’, whose each element is of the form [i, j], denoting an edge from node ‘i’ to node ‘j’ of the respective color.
Your task is to compute an array ‘answer’ of size ‘N’, where ‘answer[i]’ stores the length of the shortest path from node ‘0’ to node ‘i’ such that the edges along the path have alternate colors. If there is no such path from node ‘0’ to ‘i’, then ‘answer[i] = -1’.
Example:
N = 4, redEdges = [[0, 1], [2, 3]], blueEdges = [[1, 2], [1, 3]]
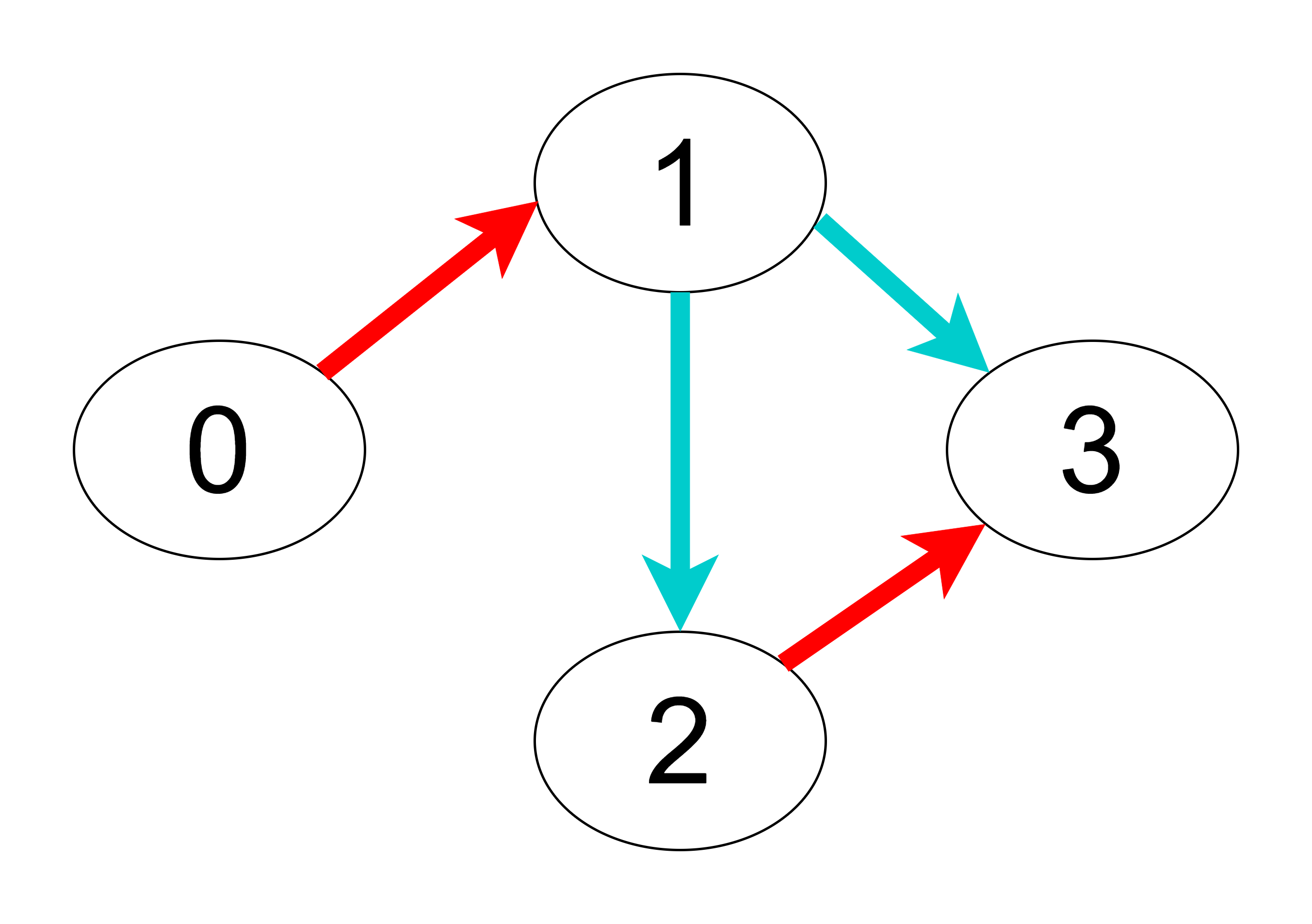
The shortest paths for each node from node ‘0’ are:
1: 0->1 Length: 1
2: 0->1->2 Length: 2
3: 0->1->3 Length: 2
So, the ‘answer’ array will be: [0, 1, 2, 2].
Note:
1. The given graph could be a disconnected graph.
2. Any two nodes ‘i’ and ‘j’ can have at most one red edge from ‘i’ to ‘j’ and at most one blue edge from ‘i’ to ‘j’.
2. Spell Checker
Hard
50m average time
50% success
0/120
Asked in companies
You are given a list of strings, ‘DICTIONARY[]’ that represents the correct spelling of words and a query string ‘QUERY’ that may have incorrect spelling. You have to check whether the spelling of the string ‘QUERY’ is correct or not. If not, then return the list of suggestions from the list ‘DICTIONARY’. Otherwise, return an empty list which will be internally interpreted as the correct string.
Note:
1) The suggested correct strings for the string ‘QUERY’ will be all those strings present in the ‘DICTIONARY[]’ that have the prefix same as the longest prefix of string ‘QUERY’.
2) The ‘DICTIONARY[]’ contains only distinct strings.
For example:
Given 'DICTIONARY[]' = {“ninja”, “ninjas”, “nineteen”, “ninny”} and query = “ninjk”. Since “ninjk” is not present in the ‘DICTIONARY[]’, it is an incorrect string. The suggested current spellings for “ninjk” are “ninja” and “ninjas”. It is because “ninj” is the longest prefix of “ninjk” which is present as the prefix in ‘DICTIONARY’.
3. The Skyline Problem
Hard
15m average time
85% success
0/120
Asked in companies
You are given 'N' rectangular buildings in a 2-dimensional city. Your task is to compute the skyline of these buildings, eliminating hidden lines return the skyline formed by these buildings collectively. A city's skyline is the outer contour of the silhouette formed by all the buildings in that city when viewed from a distance. The geometric information of each building is given in the array of buildings where BUILDINGS[i] = [LEFT_i, RIGHT_i, HEIGHT_i]:
-> LEFT_i is the x coordinate of the left edge of the ith building.
-> RIGHT_i is the x coordinate of the right edge of the ith building.
-> HEIGHT_i is the height of the ith building.
You may assume all buildings are perfect rectangles grounded on an absolutely flat surface at height 0.
The skyline should be represented as a list of "key points" sorted by their x-coordinate in the form [[x1, y1], [x2, y2], ...]. Each key point is the left endpoint of some horizontal segment in the skyline except the last point in the list, which always has a y-coordinate 0 and is used to mark the skyline's termination where the rightmost building ends. Any ground between the leftmost and rightmost buildings should be part of the skyline's contour.
Note:
There must be no consecutive horizontal lines of equal height in the output skyline. For instance, [...,[2 3], [4 5], [7 5], [11 5], [12 7],...] is not acceptable; the three lines of height 5 should be merged into one in the final output.
As such: [..., [2 3], [4 5], [12 7],...].
Also, the buildings are sorted by a non-decreasing order.
For more clarification see sample case 1.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
Which SQL clause is used to specify the conditions in a query?
Choose another skill to practice
Similar interview experiences
SDE - 1
1 rounds | 2 problems
Interviewed by Google

Rejected
3541 views
1 comments
0 upvotes
SDE - 1
1 rounds | 1 problems
Interviewed by Google
Rejected
1997 views
1 comments
0 upvotes
SDE - 1
4 rounds | 5 problems
Interviewed by Google
Selected 4290 views
0 comments
0 upvotes
SDE - 1
3 rounds | 5 problems
Interviewed by Google
 Selected
Selected 1931 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
5 rounds | 12 problems
Interviewed by Amazon
 Selected
Selected 113893 views
24 comments
0 upvotes
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 57274 views
5 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by Amazon
 Selected
Selected 34685 views
6 comments
0 upvotes