


























IBM interview experience Real time questions & tips from candidates to crack your interview
Associate Software Engineer
IBM
3 rounds | 11 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 3 months
Topics: Data Structures, Algorithms, System Design, Aptitude, OOPS
Tip 1 : Must do Previously asked Interview as well as Online Test Questions.
Tip 2 : Go through all the previous interview experiences from Codestudio and Leetcode.
Tip 3 : Do at-least 2 good projects and you must know every bit of them.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Have at-least 2 good projects explained in short with all important points covered.
Tip 2 : Every skill must be mentioned.
Tip 3 : Focus on skills, projects and experiences more.

Interview rounds
01
Round
Medium
Online Coding Interview
Duration90 Minutes
Interview date14 Jun 2021
Coding problem2
It was an Aptitude test and Technical objective test of 30 minutes followed by a Coding test of 60 minutes.
1. Minimum number of swaps required to sort an array
Easy
10m average time
90% success

0/40
Asked in companies

You have been given an array 'ARR' of 'N' distinct elements.
Your task is to find the minimum no. of swaps required to sort the array.
For example:
For the given input array [4, 3, 2, 1], the minimum no. of swaps required to sort the array is 2, i.e. swap index 0 with 3 and 1 with 2 to form the sorted array [1, 2, 3, 4].
Problem approach
Approach :
1) The basic idea is to make a new array (called temp), which is a sorted form of the input array.
2) Make a map that stores the elements and their corresponding index, of the input array. So at each i starting from 0 to N is in the given array, where N is the size of the array:
3) If i is not in its correct position according to the sorted array, then
4) We will fill this position with the correct element from the hashmap we built earlier. We know the correct element which should come here is temp[i], so we look up the index of this element from the hashmap.
5) After swapping the required elements, we update the content of the hashmap accordingly, as temp[i] to the ith position, and arr[i] to where temp[i] was earlier.
TC : O(N * Log(N)), where N=size of the given array.
SC : O(N)
2. Evaluate Division
Moderate
15m average time
85% success
0/80
Asked in companies
You are given an array of pairs of strings 'EQUATIONS', and an array of real numbers 'VALUES'. Each element of the 'EQUATIONS' array denotes a fraction where the first string denotes the numerator variable and the second string denotes the denominator variable, and the corresponding element in 'VALUES' denotes the value this fraction is equal to.
You are given ‘Q’ queries, and each query consists of two strings representing the numerator and the denominator of a fraction. You have to return the value of the given fraction for each query. Return -1 if the value cannot be determined.
Example :
'EQUATIONS' = { {“a”, ”s”} , {“s”, “r”} }
'VALUES' = { 1.5, 2 }
queries = { {“a”, “r” } }
For the above example (a / s) = 1.5 and (s / r) = 2 therefore (a / r) = 1.5 * 2 = 3.
Problem approach
Approach :
1) Iterate through the ‘EQUATIONS’ array; let’s say we are currently at index ‘i’.
1.1) Insert an edge from the numerator variable to the denominator variable with weight equal to ‘VALUES[i]'.
1.2) Also, insert an edge from the denominator variable to the numerator variable with a weight equal to 1 / ‘VALUES[i]’.
2) Iterate through the queries; let’s say the numerator and denominator for the current query are ‘NUM' and ‘DEN’.
2.1) Traverse the graph to find a path from ‘NUM' and ‘DEN’ using the Breadth-First Search Algorithm.
2.2) If there is no such path, then the value cannot be determined. Hence the result for this query will be -1.
2.3) Otherwise, the answer for this query will be the product of all values on the path from ‘NUM' to ‘DEN’.
TC : O(N * Q), Where N is the number of equations and Q is the number of queries.
SC : O(N)
02
Round
Medium
Video Call
Duration60 Minutes
Interview date14 Jun 2021
Coding problem4
This round had 1 question related to Graphs and then the rest of the questions were from OOPS.
1. Negative Cycle in a Directed Graph
Moderate
25m average time
75% success
0/80
Asked in company
You have been given a directed weighted graph of ‘N’ vertices labeled from 1 to 'N' and ‘M’ edges. Each edge connecting two nodes 'u' and 'v' has a weight 'w' denoting the distance between them.
Your task is to detect whether the graph contains a negative cycle or not. A negative cycle is a cycle whose edges are such that the sum of their weights is a negative value.
Example:
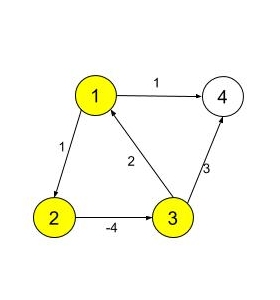
The above graph contains a cycle ( 1 -> 2 -> 3 -> 1 ) and the sum of weights of edges is -1 (1 - 4 + 2 = -1) which is negative. Hence the graph contains a negative cycle.
Note:
It's guaranteed that the graph doesn't contain self-loops and multiple edges.
Problem approach
Approach (Using Bellman-Ford Algo) :
1) Iterate on the source (vertex 1 to vertex ‘N’).
2) Make an array ‘D’ and initialize the array with an infinite value, except ‘D[source]’, ‘D[source]’ = 0.
3) Do ‘N’ iterations and in each iteration follow the below steps:
3.1) Iterate on the edges on the graph and for each edge (‘u’,’v’,’w’) update the value to ‘D[v]’, i.e., ‘D[v]’ = min(‘D[v]’, ‘D[u]+w’).
3.2) In the Nth iteration, if there is an edge (‘u’,’v’,’w’) such that, ‘D[v]’ is less than ‘D[u]+w’, then the given graph contains a negative cycle.
TC : O(N^2 * M), where N is the number of vertices in a graph and M is the number of edges in the graph.
SC : O(N)
2. OOPS Question
Difference between Constructor and Method?
Problem approach
Constructors :
1) A Constructor is a block of code that initializes a newly created object.
2) A Constructor can be used to initialize an object.
3) A Constructor is invoked implicitly by the system
4) A Constructor is invoked when a object is created using the keyword new.
5) A Constructor doesn’t have a return type.
6) A Constructor’s name must be same as the name of the class.
7) A Constructor cannot be inherited by subclasses.
Method :
1) A Method is a collection of statements which returns a value upon its execution.
2) A Method consists of Java/C++ code to be executed.
3) A Method is invoked by the programmer.
4) A Method is invoked through method calls.
5) A Method must have a return type.
6) A Method’s name can be anything.
7) A Method can be inherited by subclasses.
3. OOPS Question
Explain Singleton Class in Java
Problem approach
1) In object-oriented programming, a singleton class is a class that can have only one object (an instance of the
class) at a time.
2) After first time, if we try to instantiate the Singleton class, the new variable also points to the first instance created.
3) So whatever modifications we do to any variable inside the class through any instance, it affects the variable of the
single instance created and is visible if we access that variable through any variable of that class type defined.
The key points while defining class as singleton class are :
1) Make constructor private.
2) Write a static method that has return type object of this singleton class. Here, the concept of Lazy initialization is
used to write this static method.
4. OOPS Question
What is Garbage collector in JAVA?
Problem approach
Answer :
1) Garbage Collection in Java is a process by which the programs perform memory management automatically.
2) The Garbage Collector(GC) finds the unused objects and deletes them to reclaim the memory.
3) In Java, dynamic memory allocation of objects is achieved using the new operator that uses some memory and the
memory remains allocated until there are references for the use of the object.
4) When there are no references to an object, it is assumed to be no longer needed, and the memory, occupied by
the object can be reclaimed.
5) There is no explicit need to destroy an object as Java handles the de-allocation automatically.
The technique that accomplishes this is known as Garbage Collection. Programs that do not de-allocate memory can
eventually crash when there is no memory left in the system to allocate. These programs are said to have memory
leaks.
Garbage collection in Java happens automatically during the lifetime of the program, eliminating the need to de-
allocate memory and thereby avoiding memory leaks.
In C language, it is the programmer’s responsibility to de-allocate memory allocated dynamically using free() function.
This is where Java memory management leads.
03
Round
Medium
Video Call
Duration60 Minutes
Interview date14 Jun 2021
Coding problem5
This was a standard DSA round where I was asked to solve 1 question and also code it in a production ready manner. I was also tested on DBMS in this round. This round ended with the famous Die-Hard Puzzle.
1. Reverse Stack Using Recursion
Easy
21m average time
80% success
0/40
Asked in companies

Reverse a given stack of 'N' integers using recursion. You are required to make changes in the input parameter itself.
Note: You are not allowed to use any extra space other than the internal stack space used due to recursion.
Example:
Input: [1,2,3,4,5]
Output: [5,4,3,2,1]
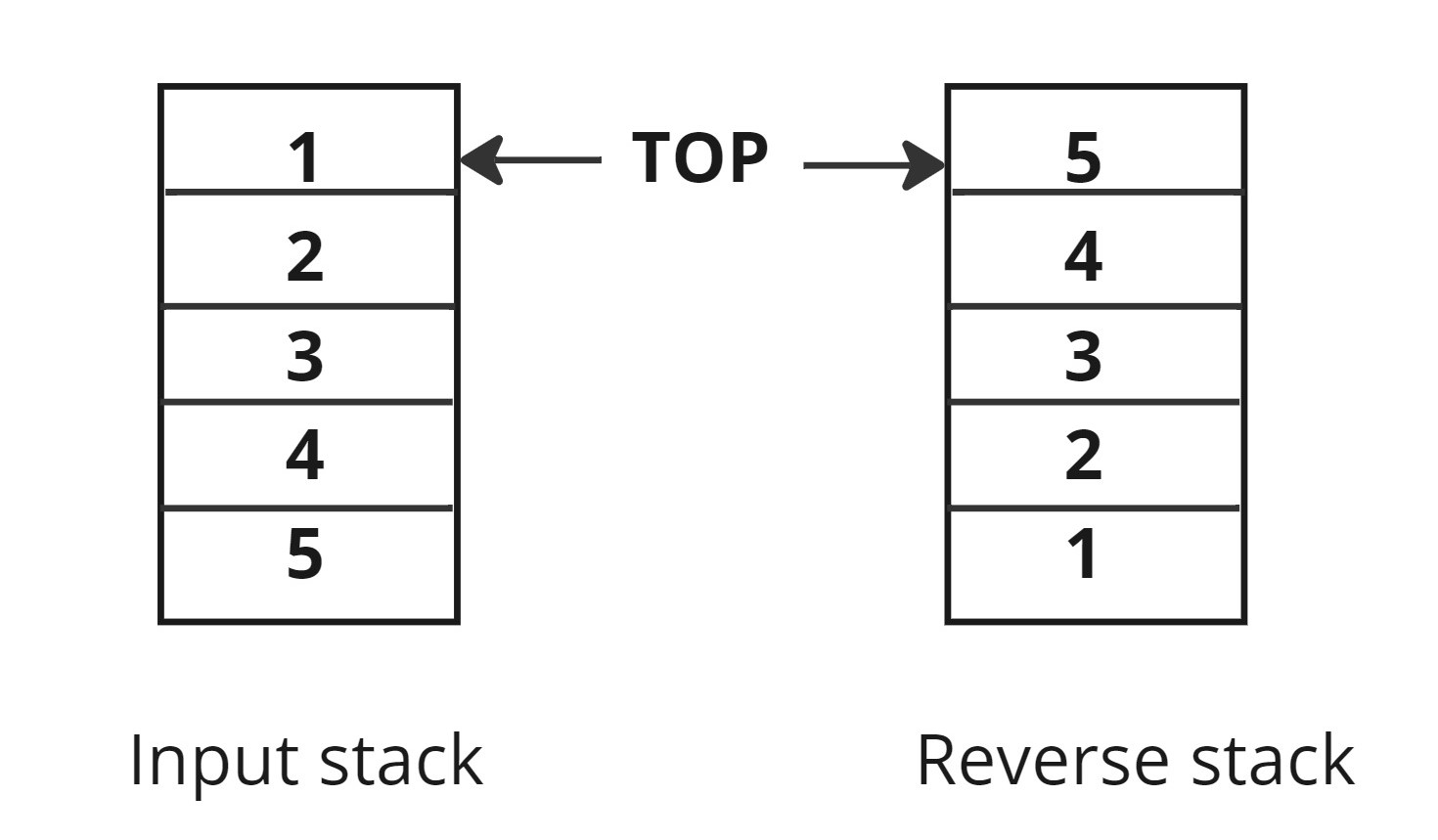
Problem approach
Algorithm :
1) ReverseStack(stack)
i) If the stack is empty, then return
ii) Pop the top element from the stack as top
iii) Reverse the remaining elements in the stack, call reverseStack(stack) method
iv) Insert the top element to the bottom of the stack, call InsertAtBottom(stack, top) method
2) InsertAtBottom(stack, ele)
i) If the stack is empty, push ele to stack, return
ii) Pop the top element from the stack as top
iii) Insert the ele to the bottom of the stack, call InsertAtBottom(stack, ele) method
iv) Push top to the stack.
TC : O(N^2) , where N=total number of elements in the given stack
SC : O(N)
2. DBMS Question
What is meant by normalization and denormalization?
Problem approach
NORMALIZATION :
1) Normalization is a process of reducing redundancy by organizing the data into multiple tables.
2) Normalization leads to better usage of disk spaces and makes it easier to maintain the integrity of the database.
DENORMALIZATION :
1) Denormalization is the reverse process of normalization as it combines the tables which have been normalized into
a single table so that data retrieval becomes faster.
2) JOIN operation allows us to create a denormalized form of the data by reversing the normalization.
3. DBMS Question
Difference between Primary key and Unique key
Problem approach
Primary Key : Used to serve as a unique identifier for each row in a table.
Unique Key : Uniquely determines a row which isn’t primary key.
Key Differences Between Primary key and Unique key:
1) Primary key will not accept NULL values whereas Unique key can accept NULL values.
2) A table can have only one primary key whereas there can be multiple unique key on a table.
3) A Clustered index automatically created when a primary key is defined whereas Unique key generates the non-
clustered index.
4. DBMS Question
Explain Left Outer Join and Right Outer Join .
Problem approach
LEFT JOIN :
The LEFT JOIN or the LEFT OUTER JOIN returns all the records from the left table and also those records which
satisfy a condition from the right table. Also, for the records having no matching values in the right table, the output or
the result-set will contain the NULL values.
Syntax:
SELECT Table1.Column1,Table1.Column2,Table2.Column1,....
FROM Table1
LEFT JOIN Table2
ON Table1.MatchingColumnName = Table2.MatchingColumnName;
RIGHT JOIN :
The RIGHT JOIN or the RIGHT OUTER JOIN returns all the records from the right table and also those records
which satisfy a condition from the left table. Also, for the records having no matching values in the left table, the
output or the result-set will contain the NULL values.
Syntax:
SELECT Table1.Column1,Table1.Column2,Table2.Column1,....
FROM Table1
RIGHT JOIN Table2
ON Table1.MatchingColumnName = Table2.MatchingColumnName;
5. Puzzle
Measure 4L using 3L and 5L cans .
Problem approach
Steps :
Let's call 5L jar as X and 3L jar as Y.
1) We'll take the first jar, i.e, X. Fill X completely.
2) Then empty the X content in Y. We are left with 2 L in the X.
3) Now we will empty the Y jar and then Fill 2L from X into Y. We are left with 0L in X and 2L in Y.
4) Now again we will fill X with 5L and then empty till Y gets full.
5) As Y is already full with 2L from previous operation so it can only accomodate 1L now from X. So when
Y jar is full automatically we will have 4L left in X. This is how we will calculate 4L


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
Which collection class forbids duplicates?
Choose another skill to practice
Similar interview experiences
Associate Software Engineer
4 rounds | 4 problems
Interviewed by IBM
 Selected
Selected 2383 views
0 comments
0 upvotes
System Engineer
3 rounds | 12 problems
Interviewed by IBM
Rejected
2314 views
0 comments
0 upvotes
Associate Software Engineer
2 rounds | 4 problems
Interviewed by IBM
Selected 5407 views
0 comments
0 upvotes
SDE - 1
2 rounds | 4 problems
Interviewed by IBM
Rejected
977 views
0 comments
0 upvotes
Companies with similar interview experiences
Associate Software Engineer
3 rounds | 10 problems
Interviewed by Amdocs
Selected 2525 views
0 comments
0 upvotes
Associate Software Engineer
3 rounds | 4 problems
Interviewed by Amdocs
 Selected
Selected 2127 views
0 comments
0 upvotes
Associate Software Engineer
3 rounds | 5 problems
Interviewed by Optum
Selected 2357 views
0 comments
0 upvotes