


























LinkedIn interview experience Real time questions & tips from candidates to crack your interview

SDE - 1
LinkedIn
4 rounds | 8 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 5 months
Topics: Data Structures, Algorithms, System Design, Aptitude, OOPS
Tip 1 : Must do Previously asked Interview as well as Online Test Questions.
Tip 2 : Go through all the previous interview experiences from Codestudio and Leetcode.
Tip 3 : Do at-least 2 good projects and you must know every bit of them.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Have at-least 2 good projects explained in short with all important points covered.
Tip 2 : Every skill must be mentioned.
Tip 3 : Focus on skills, projects and experiences more.

Interview rounds
01
Round
Hard
Online Coding Test
Duration60 minutes
Interview date21 Apr 2015
Coding problem3
3 DSA based questions were given to be solved within 60 minutes.
1. Optimal BST
Hard
55m average time
45% success

0/120
Asked in companies
Given a sorted array of keys of BST and an array of frequency counts of each key in the same order as in the given inorder traversal. The frequency of an element is the number of searches made to that element. Construct a binary search tree from the given keys such that the total cost of all the searches is minimum.
Cost of searching a key is its frequency multiplied by its level number in the BST.
A binary search tree (BST), also called an ordered or sorted binary tree, is a rooted binary tree whose internal nodes each store a key greater than all the keys in the node's left subtree and less than those in its right subtree.
For example:
Input keys = [ 1, 3, 5 ]
Frequency = [ 3, 10, 7 ]
All the unique BST possible from the given keys are:
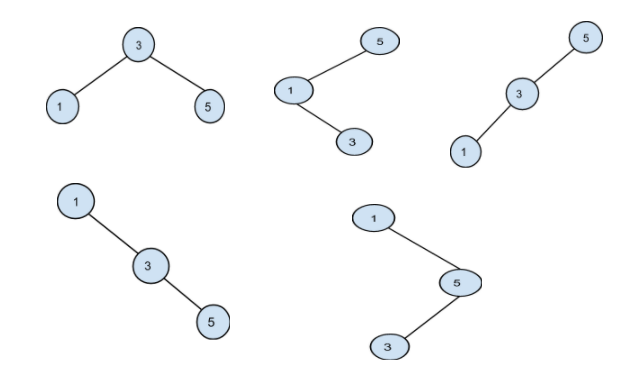
Among all these possible BST, the minimum cost is obtained from the below BST:
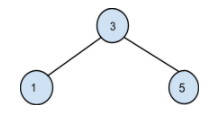
Cost = 1 * (freq of 3) + 2 * (freq of 1) + 2 * (freq of 5) = 30
where 1 is the level of node 3, 2 is the level of the node 1 and node 5.
Problem approach
Begin by examining the root node. If the tree is null, the key we are searching for does not exist in the tree. Otherwise, if the key equals that of the root, the search is successful, we return the node.
If the key is less than that of the root, we search the left subtree. Similarly, if the key is greater than that of the root, we search the right subtree. This process is repeated until the key is found or the remaining subtree is null. If the searched key is not found after a null subtree is reached, then the key is not present in the tree.
Time Complexity : On average, binary search trees with n nodes have O(log(n)) height. However, in the worst case, binary search trees can have O(n) height (for skewed trees where all the nodes except the leaf have one and only one child) when the unbalanced tree resembles a linked list.
Auxiliary Space : The space used by the call stack is also proportional to the tree’s height.
2. Number Of Distinct Substring
Moderate
30m average time
70% success
0/80
Asked in companies
Ninja has been given a string ‘WORD’ containing lowercase English alphabets having length ‘N’. Ninja wants to calculate the number of distinct substrings in the ‘WORD’.
For Example :
For ‘WORD’ = “abcd” and ‘N’ = 4 following are the 10 distinct substrings of ‘WORD’.
“abcd”, “abc”, “ab”, “a”, “bcd”, “bc”, “b”, “cd”, “c”, and “d”
Can you help the Ninja to find out the number of distinct substrings in the ‘WORD’?
Note :
If you are going to use variables with dynamic memory allocation then you need to release the memory associated with them at the end of your solution.
Problem approach
The naïve approach would be to use a hashset. The idea is to find all substrings and insert each substring into a HashSet. Since there will be no duplicates possible into the HashSet, after we have inserted all the substrings in the HashSet the size of the HashSet will be equal to the number of distinct substrings.
The steps are as follows :
1. Iterate through the current string and pivot each index, let’s say the pivoted index is ‘i’.
o Iterate from the ‘i’ till the end of the loop, let’s say the current index is ‘j’.
Insert the substring from index ‘i’ to index ‘j’ into the HashSet.
2. Return the size of the HashSet+1(extra 1 for empty substring), as that will be the number of distinct substrings in the given string.
Time Complexity : O(N^3), where N is the length of the given string.
The solution can be optimised by the use of a trie. The idea is to build a trie for all suffixes of the given string. We will use the fact that every substring of ‘S’ can be represented as a prefix of some suffix string of ‘S’. Hence, if we create a trie of all suffixes of ‘S’ then the number of distinct substrings will be equal to the nodes in the trie. This is because for every substring there will be only one path from the root node of the trie to the last character of the substring, hence no duplicate substrings will be present in the trie.
The trie class structure is as follows:
class TrieNode
{
public:
unordered_map children;
};
The steps are as follows :
1. Iterate through the given string, let’s say our current index is ‘i’.
1. Insert the suffix starting at index ‘i’ of the given string into the trie.
2. Now to count the number of nodes in the trie , recursion can be used. Define a function countNodes(root) where “root” denotes the current node of the trie. This function will return the number of nodes in the subtree of the “root”.
1. Initialize a variable “subtreeNodes” to 1, we will use this variable to count the number of nodes in the subtree of the current node. We are initializing the variable to 1 because the current node will also be counted in the subtree.
2. Iterate through the children nodes of the current node, let’s say we are currently at the ‘i’ th child.
1. If the current child node is not null then recursively call the function for all children of the current node i.e. countNodes(root->child[i]) and add the value returned by this function call to “subtreeNodes”.
3. Return the value of “subtreeNodes”
3. Return the number of nodes of the trie as this will be the number of distinct substrings in the given string.
Time Complexity: O(N^2), where N is the length of the given string.
3. Find all distinct palindromic substrings of a given string
Moderate
20m average time
80% success
0/80
Asked in companies
Ninja did not do homework. As a penalty, the teacher has given a string ‘S’ to ninja and asked him to print all distinct palindromic substrings of the given string. A string is said to be palindrome if the reverse of the string is the same as the string itself. For example, the string “bccb” is a palindrome, but the string “def” is not a palindrome.
Problem approach
The brute force approach is to simply use three loops and check for each substring if it is palindromic and add it to the output array accordingly. A Hashmap can be used to keep track of palindromic substrings and will sort all palindromic substrings before returning them.
Time Complexity : O(N^3)
For the efficient approach, Manacher’s algorithm can be modified.
For each character in the string, consider all odd and even lengths substrings centered at the character. For odd length substrings, keep a string and append the character in the string, compare the left and right characters. If both of them are equal then we can expand that string to left and right as including that left and right character in the string will also result in a palindromic substring. For even length substrings, keep the string empty and expand.
Odd length :
At position I, Each character at J distance to its left and right should be the same to create a palindromic substring of odd length ( S[ I-J ] = S[ I+J ] ).
For example, Consider S = ’abcbd’ and odd length substrings centered at position 3 will be [ ‘c’ , ‘bcb’, ‘abcbd’ ] and palindromic substrings among them are [ ‘c’ , ‘bcb’ ] .
Even length :
Consider S =’dabbac’ and even length substrings at position 4 will be [ ‘bb’, ‘abba’, ‘dabbac’ ] and palindromic substrings are [ ‘bb’, ‘abba’ ].
Consider S =’abcbd’ and even length substrings centered at position 3 will be [ ‘bc’ , ‘abcb’ ], out of which no substring is palindrome.
Use a Hashmap to keep track of all palindromic substrings and sort all palindromic substrings before printing.
Algorithm:
• Maintain a Hashmap M.
• Let N be the length of the String S.
• Iterate I from 0 to N - 1,
o Firstly we will find the odd length palindromic substrings. To find them, we will set the variable Start as I - 1 and the variable End as I + 1.
o While both the variables Start, End lies between 0 to N - 1, then
Check if S[ Start ] equal to S[ End ]
Insert S[ Start:End ] into the HashMap, if it is already not present in it. Here, S[ Start:End ] is the substring of S from Start to End index.
Otherwise, terminate the loop
Decrement Start by 1 and increment End by 1.
• To find the even length palindromic substrings, we will take the variable Start as I - 1 and the variable end as I and will perform the same procedure as mentioned above.
• After iterating through the input string completely, we will store the keys of the HashMap into an array of strings
• Sort the array of strings and return the final array.
Time Complexity : O(N^2), where N is the length of the string S.
02
Round
Medium
Face to Face
Duration60 minutes
Interview date21 Apr 2015
Coding problem2
Technical Interview round where the interviewer asked 2 DSA problems.
1. Distance between two nodes of a Tree
Moderate
25m average time
60% success
0/80
Asked in companies
Given a binary tree and the value of two nodes, find the distance between the given two nodes of the Binary Tree.
Distance between two nodes is defined as the minimum number of edges in the path from one node to another.
Problem approach
The distance between two nodes can be found out using the lowest common ancestor. Following is the formula.
Dist(n1, n2) = Dist(root, n1) + Dist(root, n2) - 2*Dist(root, lca)
'n1' and 'n2' are the two given keys
'root' is root of given Binary Tree.
'lca' is lowest common ancestor of n1 and n2
Dist(n1, n2) is the distance between n1 and n2.
LCA of binary tree :
The recursive approach is to traverse the tree in a depth-first manner. The moment you encounter either of the nodes node1 or node2, return the node. The least common ancestor would then be the node for which both the subtree recursions return a non-NULL node. It can also be the node which itself is one of node1 or node2 and for which one of the subtree recursions returns that particular node.
Pseudo code :
LowestCommonAncestor(root, node1, node2) {
if(not root)
return NULL
if (root == node1 or root == node2)
return root
left = LowestCommonAncestor(root.left, node1, node2)
right = LowestCommonAncestor(root.right, node1, node2)
if(not left)
return right
else if(not right)
return left
else
return root
}
2. Decode Ways
Moderate
15m average time
85% success
0/80
Asked in companies
Given a string ‘strNum’ which represents a number, your task is to find the ways to decode the given string ‘strNum’.
The format of encoding is as follows: ‘A’ - 1, ‘B’ - 2, ‘C’ - 3, ‘D’ - 4, ……………, ‘Z’ - 26.
Encoding is possible in letters from ‘A’ to ‘Z’. There is an encoding between character and number.
Example :
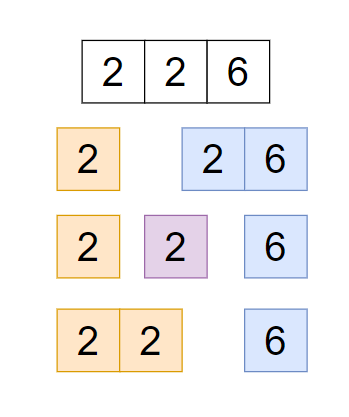
‘n = 226’ so we can decode ‘226’ in such a way-
‘BZ = 2-26’, as B maps to 2 and Z maps to 26.
‘BBF = 2-2-6’
‘VF = 22-6’
‘226; can be decoded in three ‘BZ’, ‘BBF’, ‘VF’ possible ways.
Point to be noticed we can’t decode ‘226’ as ‘226’ because we have no character which can directly map with ‘226’ we can only decode numbers from ‘1’ to ‘26’ only.
Problem approach
Recursion can be used in this. Start from the end of the given digit sequence. Initialize the total count of decodings as 0.
Recur for two subproblems:
1) If the last digit is non-zero, recur for the remaining (n-1) digits and add the result to the total count.
2) If the last two digits form a valid character (or smaller than 27), recur for remaining (n-2) digits and add the result to the total count.
The time complexity of above the code is exponential.
Dynamic programming can be used to optimise the above solution.
For a character s[i], we have 2 ways to form:
o Single digit: Require s[i] != '0' (forms 1..9)
o Two digits: Require i + 1 < len(s) and s[i] == 1 (forms 10..19) or s[i] == 2 and s[i+1] <= '6' (forms 20..26).
Time Complexity - O(N)
Space Complexity - O(N)
03
Round
Medium
Face to Face
Duration60 minutes
Interview date21 Apr 2015
Coding problem2
Technical interview round where I was given 2 DSA problems to solve.
1. Validate BST
Moderate
25m average time
0/80
Asked in companies

You have been given a binary tree of integers with N number of nodes. Your task is to check if that input tree is a BST (Binary Search Tree) or not.
A binary search tree (BST) is a binary tree data structure which has the following properties.
• The left subtree of a node contains only nodes with data less than the node’s data.
• The right subtree of a node contains only nodes with data greater than the node’s data.
• Both the left and right subtrees must also be binary search trees.
Example :
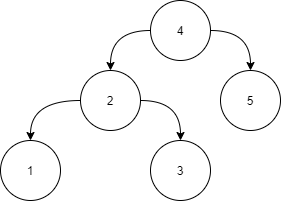
Answer :
Level 1:
All the nodes in the left subtree of 4 (2, 1, 3) are smaller
than 4, all the nodes in the right subtree of the 4 (5) are
larger than 4.
Level 2 :
For node 2:
All the nodes in the left subtree of 2 (1) are smaller than
2, all the nodes in the right subtree of the 2 (3) are larger than 2.
For node 5:
The left and right subtrees for node 5 are empty.
Level 3:
For node 1:
The left and right subtrees for node 1 are empty.
For node 3:
The left and right subtrees for node 3 are empty.
Because all the nodes follow the property of a binary search tree, the above tree is a binary search tree.
Problem approach
Approach:
A simple O(N) approach for this question would be to do an inorder traversal of the tree and store all the values in a temporary array. Next, check if the array is sorted in ascending order or not. If it is sorted, the given tree is a BST.
The above approach uses an auxiliary array. In order to avoid using auxiliary array, maintain track of the previously visited node in a variable prev. So, do an inorder traversal of the tree and store the value of the previously visited node in prev. If the value of the current node is less than prev, then the given tree is not a BST.
2. Number of Islands
Easy
0/40
Asked in companies
You have been given a non-empty grid consisting of only 0s and 1s. You have to find the number of islands in the given grid.
An island is a group of 1s (representing land) connected horizontally, vertically or diagonally. You can assume that all four edges of the grid are surrounded by 0s (representing water).
Problem approach
The question boils down to finding the number of connected components in an undirected graph. Now comparing the connected components of an undirected graph with this problem, the node of the graph will be the “1’s” (land) in the matrix.
BFS or DFS can be used to solve this problem. In each BFS call, a component or a sub-graph is visited. We will call BFS on the next un-visited component. The number of calls to BFS function gives the number of connected components. A cell in 2D matrix has 8 neighbors. So for each cell, we process all its 8 neighbors. We keep track of the visited 1s so that they are not visited again using a visited matrix.
Time Complexity : O(m*n) where m*n is the size of the given matrix
Space Complexity : O(min(m,n))
04
Round
Easy
HR Round
Duration30 minutes
Interview date21 Apr 2015
Coding problem1
Typical HR round where he asked questions on my resume and challenges faced in my project.
1. System Design Question
Showed me wwww.amazon.com page and asked me how to design the backend database so that it supports functions like displaying entire information about a product , its average rating and number of customers who gave each rating etc.
Problem approach
Tip 1:Before you jump into the solution always clarify all the assumptions you’re making at the beginning of the interview. Ask questions to identify the scope of the system. This will clear the initial doubt, and you will get to know what are the specific detail interviewer wants to consider in this service.
Tip 2 : Design your structure and functions according to the requirements and try to convey your thoughts properly to the interviewer so that you do not mess up while implementing the idea .


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
An AI invents a fake court case to support its legal answer. This is a:
Choose another skill to practice
Similar interview experiences
SDE - 1
3 rounds | 5 problems
Interviewed by LinkedIn
Selected 1223 views
0 comments
0 upvotes
SDE - 1
3 rounds | 9 problems
Interviewed by LinkedIn
Selected 1275 views
0 comments
0 upvotes
SDE - 1
1 rounds | 3 problems
Interviewed by LinkedIn
Rejected
1067 views
0 comments
0 upvotes
SDE - 1
2 rounds | 4 problems
Interviewed by LinkedIn

Rejected
1254 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
2 rounds | 3 problems
Interviewed by BNY Mellon
 Selected
Selected 6564 views
3 comments
0 upvotes
SDE - 1
3 rounds | 6 problems
Interviewed by BNY Mellon
Selected 0 views
0 comments
0 upvotes
SDE - 1
3 rounds | 5 problems
Interviewed by CIS - Cyber Infrastructure
Selected 2300 views
0 comments
0 upvotes