Why do we need Activation Functions?
The following set of equations can better explain the functioning of the activation function to know how the activation functions make the neurons learn.
In neural networks, a neuron is nothing but a weighted average of an input whose sum is calculated as follows:
Y = ∑ (weights*input + bias)
But adding the Activation function helps us create our desired output by adding non-linearity to the equation and helping us get the desired output. The new equation that is formed is:
Y = Activation function(∑ (weights*input + bias)).
Here the Y ranges from +infinity to -infinity.
Activation functions aid in normalization output from 0 to 1 or -1 to 1. Due to its differentiable characteristic, it aids in the backpropagation process. The loss function is updated during backpropagation, and the activation function aids the gradient descent curves in reaching their local minima.
Thus a neural network without an activation function is simply a linear regression model since these functions conduct non-linear calculations on the neural network's input, allowing it to learn and handle more complicated tasks.
Types of Activation Functions
Linear Activation Function
The input is directly proportional to the linear activation function. The fundamental disadvantage of the binary activation function is that this has zero gradient due to the absence of an x component. A linear function can be used to eliminate this. It can be written It may be written as
F(x) = ax.

Source: Link
Although linear functions are simple to solve, their complexity is restricted, and they have less capacity to learn complicated functional mappings from the input. Our neural networks would also be unable to learn and process various data types such as photos, videos, sound, and voice without the activation function.
Binary Activation Function
This relatively simple activation function comes to mind whenever we try to associate output. It's essentially a threshold-based classifier in which we choose a threshold value to determine whether a neuron must be stimulated or suppressed as an output.
Below is the graphical representation of the binary activation function for the equation
f(x) = 1, x>=0
f(x) = 0, x<0

Source: Link
The binary activation function is really uncomplicated. It can be applied to the construction of a binary classifier. When we only need to answer yes or no for a single class, the step function is ideal because it activates or deactivates the neuron.
Non-Linear Activation Function
The most often utilized activation functions are non-linear. It makes it simple for a neural network model to adapt to diverse data types and distinguish between distinct outputs.
Let’s learn about the most commonly used non-linear activation functions
TanH Activation Function
The hyperbolic tangent function with a range of -1 to 1 is also known as the zero-centered function. Since it's zero-centered, it's considerably easier to represent inputs with significantly negative, positive, or neutral values.
If the output is not between 0 and 1, the TanH function is used instead of the sigmoid function. TanH functions are commonly used in RNN for language processing and voice recognition tasks.

Source: Link
The equation for the Tanh function is f(x) = a =tanh(x) =(eˣ - e⁻ˣ)/(eˣ +e⁻ˣ)
On the downside, if the weighted sum input is really large or very little in both Sigmoid and TanH, the function's gradient becomes relatively small and near to zero.
Sigmoid Activation Function
The sigmoid activation function is commonly used as it is very efficient when working in accordance with the given parameters.
It is a probabilistic approach to decision making that ranges from 0 to 1, so when we need to decide or predict an output, we use this activation function as the range is the smallest. Hence, prediction is more accurate in the given range.

Source: Link
In the above-given formula -z refers to the weighted sum of input.
The sigmoid function produces a difficulty known as the vanishing gradient problem, which arises when big inputs are converted between 0, and 1 and their derivatives become significantly smaller, resulting in undesirable output.
When we don't have a tiny derivative problem, an alternative activation function like ReLU is employed to address the issue.
ReLu Activation Function
The Rectified linear unit, or ReLU, is the most extensively used activation function today, ranging from 0 to infinity.
All negative values are transformed to zero, and this conversion is so fast that it cannot map or fit into data properly, posing a problem; however, there is a solution where there is a problem.
The activation is simply set to zero as a threshold: max R(x)= max(0,x)
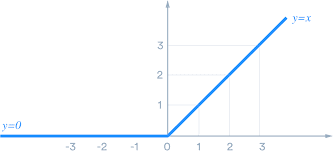
Source: Link
ReLU outperforms the Sigmoid and TanH activation functions in terms of effectiveness and generalization. ReLU is also quicker in computing since it does not perform exponentials or divisions. The downside is that, as compared to Sigmoid, ReLU overfits more.
Other Activation Functions
Leaky ReLu Activation functions
Leaky ReLu is essentially a better version of the ReLU activation function. As IU noted, it's not uncommon for us to kill specific neurons in our neural network by using ReLU, and all these neurons could never respond to any data again.
To solve this issue, the term "leaky ReLU" was coined. We add a minor linear component to the function with leaky ReLU, in contrast to standard ReLU, in which all output is 0 for input values below zero:
f(y)= ay, y<0
f(y)= y, y>=0

Source: Link
When set to 0.01, the value acts as a leaky ReLU function and a trainable parameter. The network can learn the significance of a for quicker and better convergence, keeping the sum live updating, helping neurons spark.
Softmax Activation Function
As an output, the Softmax activation function yields probabilities of the inputs. The target class will be determined using probability. The output with the highest probability will be the final product. All of this probability must add up to one. Below is the graph of the softmax activation function.

Source: Link
The equation of foftmax is f(x) = eˣᵢ / (Σⱼ₌₀ eˣᵢ)
As we saw before, the sigmoid function could only handle two classes. What should we do if we have several classes to manage? Then categorizing yes or no for a single class would be useless. The softmax function would divide by the outputs and squish the outputs for each class between 0 and 1. This is typically utilized in classification issues, especially multiclass classification.
FAQs
-
What is the best situation to use the Sigmoid Activation Function?
In general, sigmoid functions and their variants perform better in classification situations. Because of the vanishing gradient issue, sigmoid and tanh functions are sometimes avoided. Tanh is typically avoided because of the dead neuron issue.
-
Are Leaky ReLu and Parametric Leaky ReLu different?
Other activation functions, such as sigmoid or tanh, are slower than parametric Rectified Linear Unit activation functions. It enhances the performance and accuracy of neural networks, but it adds a bias towards zero in the output, resulting in specific gradients not being updated throughout the training process.
Thus, leaky ReLUs allow for a slight, non-zero gradient whenever the unit is not active. The leakage coefficient is turned into a statistic that is learned alongside the other neural network parameters in parametric ReLUs.
-
What is the Bipolar ReLu activation function used for?
The squash activation function is also known as the BiPolar Relu function. Because it avoids the vanishing gradient problem, Bipolar Relu activation outperforms other activation functions such as sigmoid and tanh in neural network activation. Bipolar ReLU should be used with an end-to-end learning method to minimize overfitting.
Key Takeaways
In the implementation of ANNs, activation functions are crucial. Their primary goal is to change a node's input signal to an output signal, which is why they're called transformation functions. The output of network layers without an activation function is turned into a linear function, with several limitations due to their limited complexity and capacity to understand complicated and inherent correlations among dataset variables.
Thus to overcome the linearity of neural networks we have introduced an activation function. In this article, we have successfully studied the most commonly used activation functions. To learn more about similar concepts, follow our blogs to understand deep in machine learning.
































 9+ registered
9+ registered 

