


























An activation tree tells the flow of execution of a program and represents it in a graphical manner where each node depicts a particular procedure.
A compiler uses stack-based memory management to manage, allocate, and deallocate memory for executing a program. It uses some units of user-defined action, such as procedures, methods, or functions for managing their runtime memory or a part of memory on the stack.

How is an activation tree created?
Whenever a compiler calls a procedure, it allocates a space for it by pushing it into the stack. After the termination of the procedure, it is popped off the stack. This enables sharing of space by procedure calls. Thus the use of stack makes code compilation efficient. The compiler allocates space to the activation record on the stack’s top.
The execution of a procedure is known as activation. An activation record comprises all the crucial information required to call a procedure. It stores immediate values and temporary values of expression.
Each procedure’s activation record is pushed in a stack in a predictable order. A procedure performs a specific task, and whenever it is called an instance of the procedure, an activation is created.
The local variables can be accessed relatively at the code’s beginning and the non-local variable’s address. A program has a sequential flow of control. Control is passed to the part of the procedure called for execution. After the procedure is completed, the control returns to the caller.
Procedure activates a tree where the main program is the root and a new node is created whenever a procedure is called. The children of the tree represent the procedures from the particular node.A procedure is considered recursive if a new activation starts before the completion of the previous procedure. Therefore an activation tree tells the flow of execution of a program and represents the control flow of a program in a graphical manner where each node depicts a particular procedure.
Symbol table in activation tree with example
A symbol table is a data structure that the compiler uses for storing information regarding functions, a variables symbols in a program. It stores the name of all the entities in a structured manner and determines the scope of a variable or a procedure. A runtime behavior can be depicted using the activation tree.
Each node is a procedure in the activation tree with its symbol table consisting of information about its variables and procures used in that particular node.
Code
#include <iostream>
using namespace std;
int NinjaVar1=5;
void NinjaFunc(){
int NinjaVar=20;
cout<<"NinjaFunc() called in main():"<<NinjaVar1+NinjaVar;
}
int main() {
NinjaFunc();
return 0;
}
Output

The symbol table for the above program is represented in the following activation tree.

In the main function, the ‘NinjaFunc()’ takes a parameter of data type ‘int’ and consists of the local variable ‘NinjaVar’ of data type ‘int.’ When the ‘‘NinjaFunc()’ is called from the main function, a node in the activation tree is created. Similarly, other nodes are created when the program continues further.
Example
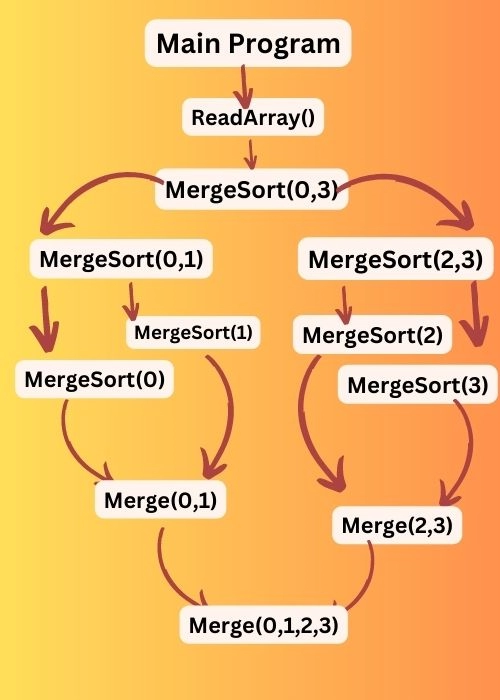
Let's understand the activation tree using merge sort.
Consider the following pseudo-code of merge sort.
int a[4];
void NinjaReadArray(){
//function that reads the input
//from the code for performing computations
}
void Ninjamerge(arr,s,e){
//merging
}
void NinjamergeSort(array[],s,e){
if(s>=e) return;
int mid=(s+e)/2;
mergeSort(arr,s, mid);
mergeSort(arr,mid+1,e);
merge(arr,mid+1,e);
}
int main() {
NinjaReadArray();
NinjamergeSort(0,4);
return 0;
}
In the above pseudo-code, we have called the NinjaReadArray() function that reads the input from the code for performing computation. It is used for separating the code that reads the input and is considered a better practice rather than keeping hard-coded values in a program.


 8+ registered
8+ registered 

