Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Database management systems (DBMS) have largely replaced the conventional filing system by offering a simple, safe, efficient, and dependable method of storing, retrieving, accessing, and sharing data within databases. Aggregation in DBMS is a design method that models the relationship between a group of items and another relationship.
What is Aggregation in DBMS?
In DBMS (Database Management System), aggregation is the process of joining two or more entities to create a more meaningful new entity. The aggregate method is used when the entities do not make sense on their own. In order to produce aggregation between two entities that cannot be used for their own attributes, a relationship is constructed and the end product is created into a new entity. Any form of relationship can be used, such as SUM, AVG, AND, OR, and so on. A wide range of tools are available on the market for table aggregation.
When using numerical numbers as data, the following DBMS aggregation operations can be used:
Operation Name
Description
Avg
The mean or average of the data values is returned by this function.
Sum
After adding the data values, this method returns the total value.
Count
The number of records returned by this field.
Maximum (Max)
Returns the highest value from a supplied set of data.
Minimum (Min)
The smallest value in a given set of data is returned by this method.
Standard Deviation (Std dev)
A statistical measure of data's dispersion or spread from the mean.
Example of Aggregation in DBMS
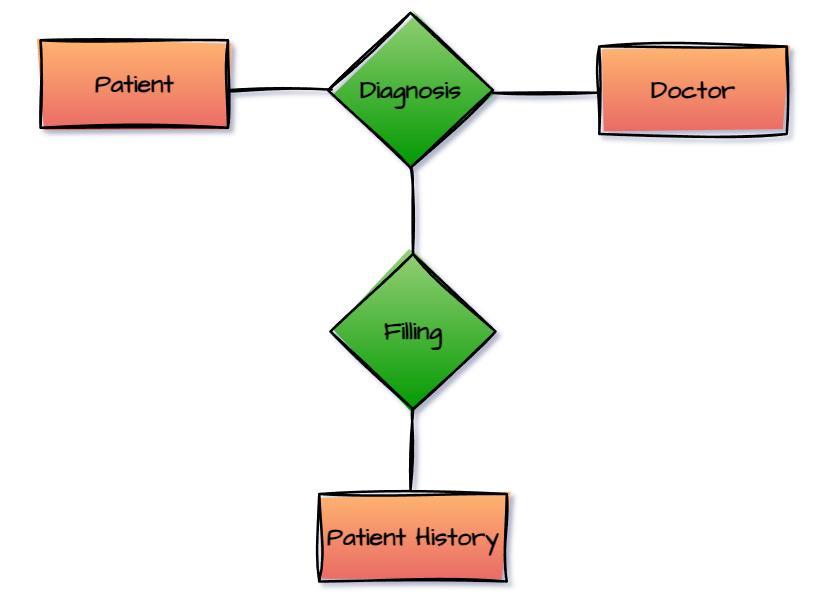
Assume a patient has gone to a doctor in the hospital to seek treatment for a specific type of ailment. The graphic below depicts the hospital's aggregation process flow.
We'll stick to simple ER model stated above. There are three entities in the diagram above: the patient history, the doctor, and the patient. Relationships are represented by filing and diagnosis. The doctor examines the patient and makes a diagnosis. The database stores information about this diagnosis as well as any other patient data. Filing is essential so that the doctor may easily obtain the patient's information in the future.
In this example, the patient is unable to work on his own. To receive a diagnosis, he needs to establish a relationship with the doctor. A diagnosis cannot be made without the presence of the patient. In the future, the doctor will require data regarding the patient's past, which he will obtain via a file system.
The final entity (the patient's history) verifies that the entire system works properly. A diagnosis from the doctor and a filing system is required to obtain the patient's history.
When to Use Aggregation in DBMS?
Many trivial entities: A DBMS may have many trivial entities that do not deliver meaningful information. In this situation, trivial entities can be aggregated into a single complex entity. For example, numerous trivial entities known as rooms can be joined to produce a single entity known as a hotel.
Single Trivial Entity: Aggregation is also required if DBMS has a single trivial entity that should be used for various operations. In this case, trivial entity is used to build relationships with other entities. Depending on the necessary actions, this may result in a large number of aggregate entities. For example, an employee in an organization may be offered insurance coverage that includes his dependents. The entity dependents is a trivial entity since it cannot exist without the entity employee.
Inapplicable entity-model relationship: The entity-model relationship cannot be applied to certain entities in the system. These specialized entities can be merged with other entities to allow the entity-model relationship to be applied throughout the system. This ensures that all of the system's entities are used. For example, entity-model relationships for students can only be applied if students enroll in a class. Entity grade can only be formed if the relationship enroll exists.
Process Flow for Aggregation in DBMS
The entity-relationship model (ER model) can be used to explain aggregation in DBMS. This is a conceptual diagram that depicts the structure and components of a database. In a DBMS, it holds the relationships, attributes, and entities. This is analogous to the columns, rows, and tables found in a database.
In an ER model, the following are the main types of relationships:
One-to-one: In this case, trivial entity has only one other entity with which it has a relationship. For example, one employee may only work in one department of a company.
One-to-many: In this relationship, one entity has numerous relationships. For example, a worker may work across various divisions within same organization.
Many-to-one: In this case, numerous entities from same entity set can build a relationship with just one other entity. For example, many employees may work in only one department.
Many-to-many: Multiple entities from one entity set that can build a relationship with several entities from another entity set fall into this category. For example, many employees may work in multiple divisions within the same business.
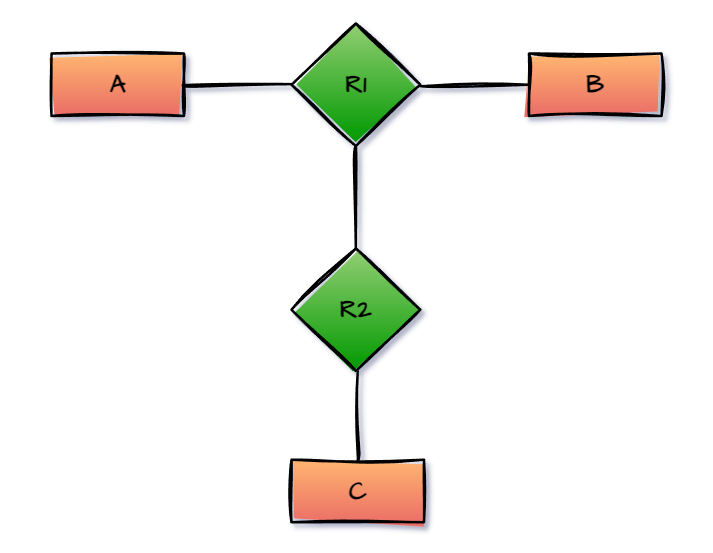
The diagram below depicts a simplified ER model that can be used to demonstrate the aggregate process flow in DBMS.
A, B, and C are entities in this ER model. A and B should be merged to form a single complex entity. R1 is the relationship formed when A and B are connected. R1 must establish relationships with other entities in order for other DBMS procedures to be successful.
This procedure results in the creation of a new relationship (R2). R2 is linked to another entity C in order to improve its operation. Aggregation is also used to create this entity.
Importance of Aggregation in DBMS
The importance of Aggregation in DBMS are:
Efficient Data Handling: Aggregation reduces the volume of data, making it easier to process and analyze large datasets
Performance Optimization: It allows for faster query execution by summarizing data, reducing the computational load on the system
Simplified Data Analysis: Aggregated data provides high-level insights, simplifying complex data sets and aiding in decision-making
Statistical Analysis: It enables the calculation of summary statistics like averages, totals, and counts, which are vital for business intelligence
Data Privacy and Security: Aggregation can anonymize sensitive information, protecting individual identities while still providing useful insights
Reporting and Visualization: Aggregated data is more conducive to creating meaningful reports and visualizations for stakeholders
Applications of Aggregation in DBMS
Aggregation functions are useful for summarizing data and generating reports for various business applications.|
In business intelligence applications, aggregation functions are used to examine massive datasets and derive insights.
In statistical analysis, aggregation functions can be used to compute measures of central tendency such as the mean, median, and mode.
To better understand the underlying trends and patterns, aggregated data can be displayed in charts and graphs.
A DBMS may have a large number of insignificant entities that do not provide useful information. The trivial entities in this situation can be combined into a single complex entity. Many tiny units known as rooms, for example, can be united to produce a single entity known as a hotel.
Frequently Asked Questions
What is aggregation in the ER model?
Aggregation in the ER model is a higher-level abstraction that represents a relationship as an entity. It is used when a relationship itself participates in another relationship, simplifying complex designs.
Where is aggregation used in DBMS?
Aggregation in a DBMS is used for summarizing, analyzing, and simplifying data, making it beneficial in data analysis, SQL queries, data warehousing, business intelligence, OLAP, and reporting.
Why is aggregation important in DBMS?
Aggregation in a DBMS is crucial for summarizing and analyzing data, aiding decision-making, and reducing data complexity. It simplifies information retrieval, improving efficiency and comprehension.
What are the disadvantages of aggregation in DBMS?
Disadvantages of aggregation in DBMS include increased storage requirements, potential loss of detailed data, complexity in maintaining aggregated data, and potential performance overhead during aggregation processes.
Conclusion
Aggregation in DBMS helps simplify complex relationships by treating them as higher-level entities. It allows a relationship to participate in another relationship, improving the clarity and efficiency of database design. This approach enhances data organization, making it easier to manage and understand interconnected entities in large-scale database systems.






























 9+ registered
9+ registered 

