Lifecycle of a training job
Start workers in parallel
The AI Platform Training service schedules as many workers as possible in a given amount of time at the onset of a training job. The Machine Learning framework automatically handles the workers that start in parallel. The workers run the code as soon as it is available. At this point, AI Platform Training sets the job state to RUNNING.
Restart workers during the training job
During a training job, the AI Platform Training service can restart the master or workers with the same hostname. This may happen for two reasons:
-
VM maintenance: AI Platform Training restarts the worker on another VM when its initial VM goes under maintenance.
-
Non-zero exits: Any worker that exits with a non-zero exit code is restarted immediately in the same VM.
If a worker cannot complete a task due to a common error, it is treated as a permanent error, and AI Platform Training terminates the entire job. But, if it is due to a non-permanent error, AI Platform Training allows the worker to keep running with up to five restarts. After five restarts, if it fails again, AI Platform Training reruns the entire job up to three times before terminating it.
Completing a job
A training job is completed successfully when the primary replica exits with code 0. The AI Platform Training then shuts down all the other running workers.
Handling training job errors
The following common errors shut down all the workers when encountered.
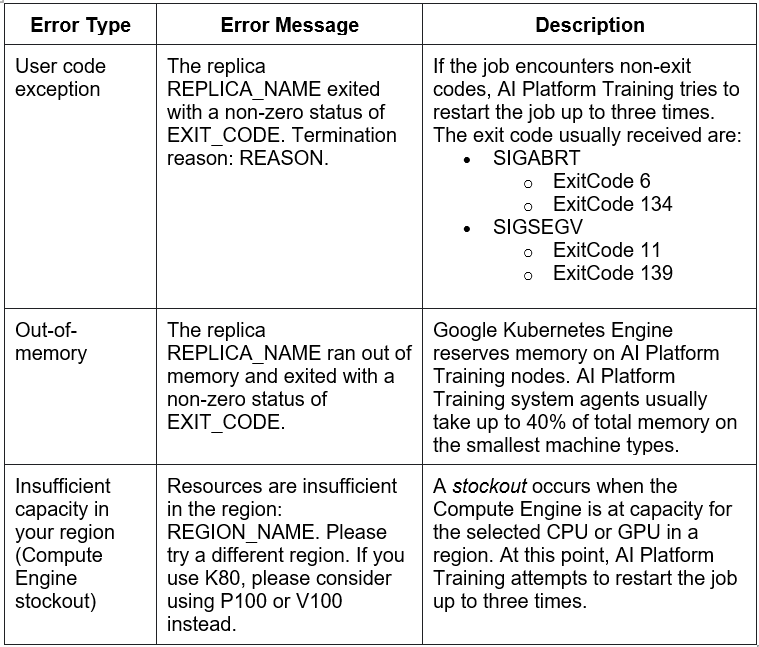
AI Platform Training tries to restart a job twice (three in total) for internal errors. If the restart attempts also fail, AI Platform Training returns an internal error stating, “Internal error occurred for the current attempt”.
TF_CONFIG
During a training job, the AI Platform Training service sets an environment variable called TF_CONFIG on every VM that is part of the job. It has access to the role of the VM it runs on and the details related to the training job. This variable allows each VM to behave differently depending on its type and helps them communicate with other VMs. TensorFlow uses it to run distributed training and hyperparameter tuning jobs.
Fields
TF_CONFIG is a JSON string containing the following fields.

Example:
{
"cluster": {
"chief": [
"cmle-training-chief-[ID_STRING_1]-0:2222"
],
"ps": [
"cmle-training-ps-[ID_STRING_1]-0:2222"
],
"worker": [
"cmle-training-worker-[ID_STRING_1]-0:2222",
"cmle-training-worker-[ID_STRING_1]-1:2222"
]
},
"environment": "cloud",
"job": {
...
},
"task": {
"cloud": "[ID_STRING_2]",
"index": 0,
"trial": "1",
"type": "worker"
}
}
Distributed Training
TensorFlow API can be used to split training across several GPUs and computers. The existing models can be distributed with the learning code easily. As datasets grow larger, it becomes increasingly difficult to train models in a short period. Distributed computing is used to overcome this problem.TensorFlow supports distributed computing which allows multiple processes to calculate different parts of a graph on different servers. TensorFlow’s distributed training is based on data parallelism, where different slices of input data can run on numerous devices while replicating the same model architecture.
To perform distributed training with TensorFlow, the tf.distribute.Strategy API is used. This distribution strategy uses the TF_CONFIG environment variable to assign roles to each VM in the training job. It also facilitates communication between VMs. TensorFlow handles the accessibility of this variable in the training code.
Hyperparameter Tuning
Hyperparameter values can be tuned to obtain optimal performance for a model. Hence, hyperparameter tuning is also known as hyperparameter optimisation. AI Platform Training provides various arguments for each trial of the training code. It also provides tools to monitor the progress of these hyperparameter tuning jobs.
Configuring distributed training for PyTorch
PyTorch is an open source machine learning framework based on the Torch library, used for applications such as computer vision and natural language processing. AI Platform Training can be used to create a distributed PyTorch training job. It runs the code on a cluster of virtual machine instances, known as nodes, with environment variables. This helps the training job scale up to handle a large amount of data.
Specifying training cluster structure
For distributed PyTorch training, configure the job to use one master worker node and one or more worker nodes. A Master worker is a VM with a rank of 0. It sets up connections between the nodes in the cluster. Workers constitute the remaining nodes of the cluster. Each worker node does a portion of training, as specified by the training application code.
Specifying container images
During the creation of a training job, the image of a Docker container for the master worker and every other worker to use in the trainingInput.masterConfig.imageUri field is specified. For creating a training job using commands, the --master-image-uri and --worker-image-uri flags are specified with “gcloud ai-platform jobs submit training”. If the trainingInput.workerConfig.imageUri field is not specified, its value is set to the value of trainingInput.masterConfig.imageUri by default.
Environment variables
Following are some of the environment variables used during the initialisation of a cluster:
-
WORLD_SIZE: The total number of nodes in the cluster. It has the same value on every node.
-
RANK: A unique identifier for each node. The master-worker has a rank of 0. Workers have a value ranging from 1 to WORLD_SIZE - 1.
-
MASTER_ADDR: The hostname of the master worker node. It has the same value on every node.
- MASTER_PORT: The port that the master worker node communicates on. It has the same value on every node.
Training at scale
Large Datasets
It becomes increasingly hard to handle large datasets for training. So, it's possible that downloading such a large dataset into a training worker VM and loading it into pandas does not scale. In such cases, TensorFlow's stream-read/file_io API can be used. Here is an example.
import pandas as pd
from pandas.compat import StringIO
from tensorflow.python.lib.io import file_io
# Access iris data from Cloud Storage
iris_data_filesteam = file_io.FileIO(os.path.join(data_dir, iris_data_filename), mode='r')
Large Models
Training worker VMs that demand higher memory needs can be requested by setting the scale-tier to CUSTOM and the master type via an accompanying config file. Scale-tiers can optimise the configuration for different jobs over time based on customer feedback and the availability of cloud resources. Each scale tier is defined based on the types of jobs.
Step 1: Create config.yaml locally with the following contents:
trainingInput:
masterType: large_model
Step 2: Submit the job:
CONFIG=path/to/config.yaml
gcloud ai-platform jobs submit training $JOB_NAME \
--job-dir $JOB_DIR \
--package-path $TRAINER_PACKAGE_PATH \
--module-name $MAIN_TRAINER_MODULE \
--region us-central1 \
--runtime-version=$RUNTIME_VERSION \
--python-version=$PYTHON_VERSION \
--scale-tier CUSTOM \
--config $CONFIG
Frequently Asked Questions
What is TensorFlow?
TensorFlow is an end-to-end open source platform with a comprehensive set of tools, libraries and community resources for Machine Learning. It supports distributed training in which storage and compute power are magnified with each added GPU, thereby reducing training time. TensorFlow helps run hyperparameter tuning jobs and provides an updated API for distributed training with multiple virtual machine instances.
Name some of the built-in algorithms available for training on AI Platform Training.
Built-in algorithms help train models for various use cases that can be solved using classification and regression. Linear learner, Wide and deep, TabNet, XGBoost, Image classification and Object detection are some of the built-in algorithms on AI Platform Training.
What are the different roles in a distributed Training structure?
The master role manages the other roles and reports the status of the job as a whole. Workers are one or more replicas that do their portion of the work as specified in the job configuration. Parameter servers coordinate the shared model state between the workers.
Conclusion
This blog discusses the AI Platform Training Service in detail. It briefly explains a training job's lifecycle, TF_CONFIG, and distributed training in Google Cloud for AI.
Check out our articles on TensorFlow, PyTorch and Hyperparameter Tuning. Explore our Library on Coding Ninjas Studio to gain knowledge on Data Structures and Algorithms, Machine Learning, Deep Learning, Cloud Computing and many more! Test your coding skills by solving our test series and participating in the contests hosted on Coding Ninjas Studio!
Looking for questions from tech giants like Amazon, Microsoft, Uber, etc.? Look at the problems, interview experiences, and interview bundle for placement preparations.
Upvote our blogs if you find them insightful and engaging! Happy Coding!































 8+ registered
8+ registered 

