Do you think IIT Guwahati certified course can help you in your career?
Introduction
In the present era, we seek approaches to simplify complicated tasks. We not only want the simplifications, but we also want to organize our workspace so that it does multiple numbers of tasks in a cost-efficient way. Here, we are going to discuss Amazon Keyspaces and Apache Cassandra and Amazon Keyspaces for Apache Cassandra, which provide us with an optimal way to deal with database services. We not only discuss the differences between them but also learn in detail about how to implement and use them in our practices.
By the end of this article, I can assure you that you’ll have a pretty clear understanding of Amazon Keyspaces for Apache Cassandra and how you will add this tool to your workspace arsenal. So let’s start by discussing What Amazon Keyspaces is?
What is Amazon Keyspaces (for Apache Cassandra)?
Amazon Keyspaces (for Apache Cassandra) is an Apache Cassandra–compatible database service that is scalable, highly available, and managed. We don't have to supply, patch, or manage servers, and here we don't have to install, maintain, or operate software using Amazon Keyspaces.
Because Amazon Keyspaces is serverless, we only pay for the resources we need, and the service scales tables up and down automatically in response to application load. We may create apps that service hundreds of requests per second with almost unlimited throughout and storage.
In the AWS Cloud, Amazon Keyspaces makes it simple to move, execute, and grow Cassandra workloads. Without deploying any equipment or installing software, we can create keyspaces and tables in Amazon Keyspaces just with a few clicks on the AWS Management Console or a few lines of code.
We may run our existing Cassandra workloads on AWS with Amazon Keyspaces, utilizing the same Cassandra application code and developer tools as before.
Amazon Keyspaces: How it works
The administrative overhead of operating Cassandra is eliminated with Amazon Keyspaces. It's helpful to start with Cassandra's architecture and then compare it to Amazon Keyspaces.
High-level architecture: Apache Cassandra vs. Amazon Keyspaces
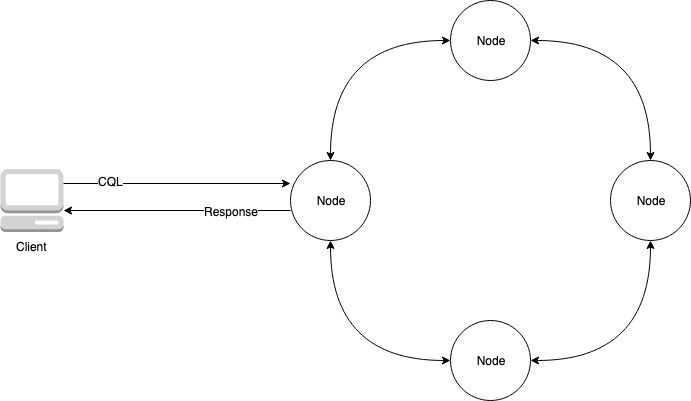
Apache Cassandra is often installed in a cluster of one or more machines. As your cluster grows, you'll be in charge of managing each node and adding and removing nodes.
Cassandra is accessed using client software that connects to one of the nodes and issues Cassandra Query Language (CQL) instructions. CQL is related to SQL, the popular relational database language. CQL has a familiar interface for querying and manipulating data in Cassandra, despite the fact that it is not a relational database.
A simple Apache Cassandra cluster with four nodes is depicted in the diagram below.
Hundreds of nodes running on hundreds of computer systems across one or more physical data centers could make up a Cassandra deployment. Application developers, who must provision, patch, and manage servers in addition to installing, updating, and operating software, may face a significant operational load.
We don't have to provision, patch, or manage servers using Amazon Keyspaces (for Apache Cassandra), so you can focus on developing better apps. For reads and writes, Amazon Keyspaces offers two throughput capacity modes: on-demand and provided. You may optimize the price of reads and writes by changing the throughput capacity mode of your table based on the predictability and variability of your workload.
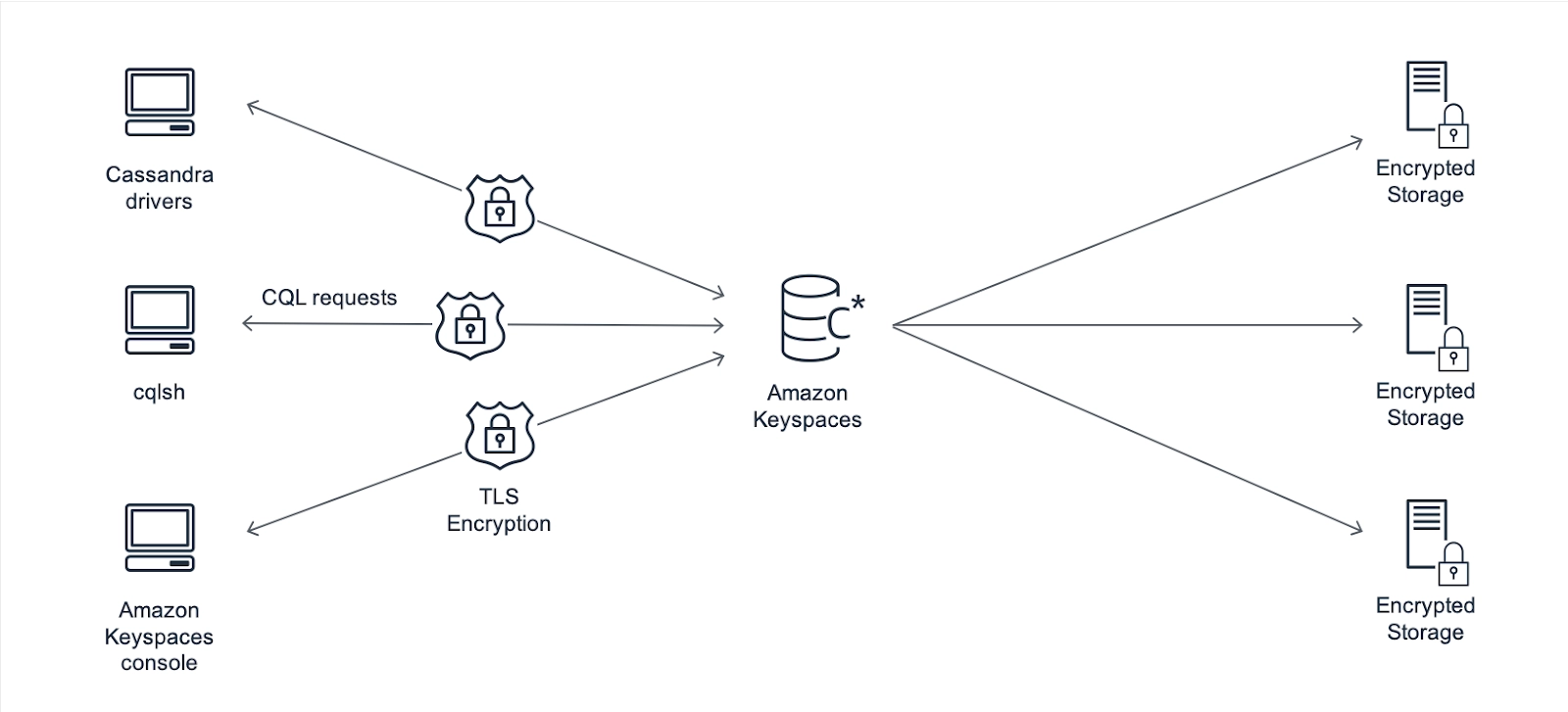
For durability and high availability, Amazon Keyspaces (for Apache Cassandra) saves three copies of your data in multiple Availability Zones. Furthermore, you gain access to a data center and network architecture designed to suit the needs of the most security-conscious businesses. When you establish a new Amazon Keyspaces table, encryption at rest is enabled by default, and client connections require Transport Layer Security (TLS). Monitoring, AWS Identity, Access Management, and virtual private cloud (VPC) endpoints are all further AWS security features. See Security in Amazon Keyspaces for a list of all possible security capabilities (for Apache Cassandra).
The architecture of Amazon Keyspaces is depicted in the diagram below.
Client software connects to Amazon Keyspaces by issuing CQL instructions and connecting to a predetermined endpoint (hostname and port number).
Cassandra data model
Getting the most out of Amazon Keyspaces depends on how you model your data for your business case. A flawed data model can have a major impact on performance.
Despite the fact that CQL looks similar to SQL, Cassandra and relational databases have fundamentally different backends and must be treated differently. The following are some of the most critical considerations:
Storage
Tables can be used to view Cassandra data, with each row representing a record and each column representing a field within that record.
Table design: Query first
In CQL, there are no JOINS. As a result, you should plan your tables around the form of your data and how you'll access it for business purposes. De-normalization with duplicated data may happen as a result of this. Each of your tables should be built with a specific access pattern in mind.
Partitions
Partition on the disc is used to store our data. Our partition key determines the number of partitions on our data and how it is kept, and how it is dispersed among them. The way we define our partition key can have a significant impact on how fast our queries run.
Primary key
Data is saved in Cassandra as a key-value pair. As a result, every Cassandra table must have a primary key, which is the key to each table row. A mandatory partition key and optional clustering columns make up the main key. The data that makes up the primary key must be unique across all of a table's rows.
Partition key: The partition key portion of the primary key is essential since it defines which partition of our cluster the data is stored in. A single column or a compound value made up of two or more columns can be used as the partition key. A single column partition key can result in a single partition or a small number of partitions containing the bulk of the data and hence bearing the majority of the disc I/O operations; you'd use a compound partition key.
Clustering column: Your primary key's optional clustering column controls how data is grouped and ordered inside each division. If your primary key includes a clustering column, the clustering column can have one or more columns. If the clustering column contains multiple columns, the sorting order is determined by the order in which the columns are listed, from left to right.
Accessing Amazon Keyspaces from an application
Amazon Keyspaces (for Apache Cassandra) uses the Apache Cassandra Query Language (CQL) API, allowing you to continue using your existing CQL and Cassandra drivers. It's as simple as changing your Cassandra driver or cqlsh configuration to point to the Amazon Keyspaces service URL to update your application.
Consider the Python program below, which connects to a Cassandra cluster and executes a query against a table.
from cassandra.cluster import Cluster
#TLS/SSL configuration goes here
ksp = 'MyKeyspace'
tbl = 'WeatherData'
cluster = Cluster(['NNN.NNN.NNN.NNN'], port=NNNN)
session = cluster.connect(ksp)
session.execute('USE ' + ksp)
rows = session.execute('SELECT * FROM ' + tbl)
for row in rows:
print(row)
To use the same software with Amazon Keyspaces, follow these steps:
Add the following to the cluster endpoint and port: The host can be substituted with a service endpoint like cassandra.us-east-2.amazonaws.com, and the port number with 9142.
Add the TLS/SSL configuration.
Amazon Keyspaces use cases.
Amazon Keyspaces can be used in a variety of ways, including the following:
Build low-latency apps — Process data at high speeds for applications, including industrial equipment maintenance, trade monitoring, fleet management, and route optimization that require single-digit millisecond latency.
Create applications with open-source software. — Create AWS apps using open-source Cassandra APIs and drivers for a variety of programming languages, including Java, Python, Ruby, Microsoft.NET, Node.js, PHP, C++, Perl, and Go.
Cassandra workloads should be moved to the cloud – Self-managing Cassandra tables is time-consuming and costly. We can set up, secure, and scale Cassandra tables in the AWS Cloud without managing infrastructure with Amazon Keyspaces. Want to know about Amazon Hirepro check this out.
What is Cassandra Query Language (CQL)?
Apache Cassandra is the primary language for communicating with Cassandra Query Language (CQL). The CQL 3.x API is compatible with Amazon Keyspaces (for Apache Cassandra) (backward-compatible with version 2.x).
We can use one of the following methods to conduct CQL queries:
On the AWS Management Console, use the CQL editor.
Use the cqlsh client to run them.
Use an Apache 2.0 licensed Cassandra client driver to run them programmatically.
Comparing Amazon Keyspaces (for Apache Cassandra) to Apache Cassandra?
To clients, Amazon Keyspaces (for Apache Cassandra) looks like a nine-node Apache Cassandra 3.11.2 cluster, and it supports Apache Cassandra 3.11.2 drivers and clients. Amazon Keyspaces is compatible with both versions 2.x and 3.x of the Cassandra Query Language (CQL) API. We may operate our Cassandra workloads on AWS using the same Cassandra application code, Apache 2.0–licensed drivers, and tools that we may use today with Amazon Keyspaces.
All standard Cassandra data-plane activities, such as creating keyspaces and tables, reading data, and writing data, are supported by Amazon Keyspaces. We don't have to provision, patch, or manage servers using Amazon Keyspaces because it's serverless. You won't have to install, maintain, or operate any software either. As a result, using Amazon Keyspaces does not necessitate using Cassandra control plane API calls to handle cluster and node configurations.
Setting such as replication factor and consistency level are automatically tuned to ensure excellent availability, durability, and performance in the single-digit millisecond range.
Functional differences: Apache Cassandra vs. Amazon Keyspaces
The functional differences between Apache Cassandra and Amazon Keyspaces are listed below.
Functionality
Differences
Apache Cassandra APIs, operations, and data types
All standard Cassandra data-plane activities, such as creating keyspaces and tables, reading data, and writing data, are supported by Amazon Keyspaces.
Asynchronous creation and deletion of keyspaces and tables
Asynchronous data definition language (DDL) actions, such as creating and deleting keyspaces and tables, are performed by Amazon Keyspaces.
Authentication and authorization
AWS Identity and Access Management (IAM) is used by Amazon Keyspaces (for Apache Cassandra) for user authentication and authorization, and it supports the same authorization policies as Apache Cassandra. As a result, the security configuration commands of Apache Cassandra are not endorsed by Amazon Keyspaces.
BATCH
Up to 30 commands in unlogged batch commands are supported by Amazon Keyspaces. In a batch, only unconditional INSERT, UPDATE, or DELETE commands are allowed. Batches that have been logged are not supported.
Cluster configuration
There are no hosts, clusters, or Java virtual machines (JVMs) to configure with Amazon Keyspaces because it is a serverless platform. Compaction, garbage collection, compression, caching, and bloom filtering options in Cassandra are not applicable to Amazon Keyspaces and are disregarded if they are specified.
CQL query throughput tuning
Amazon Keyspaces supports up to 3,000 CQL queries per TCP connection per second; however, a driver can initiate an unlimited number of connections.
The majority of open-source Cassandra drivers create a connection pool to Cassandra and load balance queries across that pool. The default action of most drivers is to make a single connection to each peer IP address that Amazon Keyspaces provides to them. As a result, utilizing the default parameters, a driver's maximum CQL query throughput will be 27,000 CQL queries per second.
The recommendation is to increase the number of connections per IP address that your driver keeps in its connection pool to improve this number. Setting the maximum connections per IP address to two, for example, will increase your driver's maximum throughput to 54,000 CQL queries per second.
Empty strings
Empty strings and blob values are supported by Amazon Keyspaces. Empty strings and blobs, on the other hand, are not supported as clustering column values.
Lightweight transactions
On INSERT, UPDATE, and DELETE commands, which are known as lightweight transactions (LWTs) in Apache Cassandra, Amazon Keyspaces (for Apache Cassandra) fully support comparison and set capability. Amazon Keyspaces (for Apache Cassandra) provides constant performance at any scale, including for lightweight transactions, as a serverless service. There is no performance cost for using lightweight transactions with Amazon Keyspaces.
Load balancing
The entries in the system.peers table refer to Amazon Keyspaces load balancers. We recommend utilizing a round-robin load-balancing scheme and tailoring the number of connections per IP to your application's demands for the best results.
Pagination
The number of rows reads to process a request, not the number of rows returned in the result set, is used to paginate Amazon Keyspaces results. As a result, certain pages for filtered queries may have fewer rows than you set in PAGE SIZE. In addition, after reading 1 MB of data, Amazon Keyspaces paginates the results automatically to provide clients with consistent single-digit millisecond read performance.
Partitioners
You can use either the Amazon Keyspaces DefaultPartitioner or the Cassandra-compatible RandomPartitioner with Amazon Keyspaces. You can securely alter the partitioner for your account with Amazon Keyspaces without needing to refresh your Amazon Keyspaces data. The modified partitioner setting will be visible to clients the next time they connect.
Prepared statements
Prepared statements can be used for data manipulation language (DML) activities like reading and writing data in Amazon Keyspaces. Prepared statements are not presently supported by Amazon Keyspaces for data definition languages (DDL) activities like establishing tables and keyspaces. Prepared statements cannot be used to run DDL procedures.
Range delete
Deleting rows in a range is possible with Amazon Keyspaces. Within a partition, a range is a contiguous set of rows—a WHERE clause is used to indicate a range in a DELETE action. You can give a whole partition as the range.
You can also designate a range to be a subset of contiguous rows within a partition by including the partition key and omitting one or more clustering columns or by using relational operators (for example, '>', "). You can delete up to 1,000 rows in a range with Amazon Keyspaces in a single action. Range deletions are also atomic but not isolated.
System tables
The system tables required by Apache 2.0 open-source Cassandra drivers are populated via Amazon Keyspaces. The information in the system tables visible to a client is unique to the authenticated user. Amazon Keyspaces has complete control over the system tables, which are read-only.
System tables require read-only access, which you can limit with IAM access policies. See Managing Access with Policies for further details. Whether you utilize the AWS SDK or Cassandra Query Language (CQL) API calls through Cassandra drivers and developer tools, you must create tag-based access control policies for system tables differently. See Amazon Keyspaces resource access based on tags for more information on tag-based access control for system tables.
When you use Amazon VPC endpoints to access Amazon Keyspaces, you'll notice entries in the system.peers. Each Amazon VPC endpoint that Amazon Keyspaces has the authorization to see is listed in the system.peers table. As a result, your Cassandra driver may send a warning message concerning the system's control node. In the table of peers, this warning can be safely ignored.
Accessing Amazon Keyspaces (for Apache Cassandra)
You can use the console to access Amazon Keyspaces, or you can use a cqlsh client, or an Apache 2.0 licensed Cassandra driver to access it programmatically. Amazon Keyspaces supports Apache Cassandra 3.11.2 compatible drivers and clients. We must first complete the following two steps before you may use Amazon Keyspaces:
Signing up for AWS
Setting up AWS Identity and Access Management.
Step 1: Signing up for AWS
You must have an AWS account to use the Amazon Keyspaces service. When you sign up, you'll be asked to create an account if you don't already have one. If you don't utilize any of the AWS services you sign up for, you won't be charged.
Step 2: Setting up AWS Identity and Access Management.
AWS Identity and Access Management are used to manage access to Amazon Keyspaces resources (IAM). Policies that allow read and write access to specific resources can be attached to IAM users, roles, and federated identities using IAM. You can provide an IAM user read-only access to a subset of keyspaces and tables, for example.
The following example IAM policy allows complete read and write access to your Amazon Keyspaces resources and is solely suggested for testing purposes.
Create a user for AWS Identity and Access Management.
Create the following and assign it to the newly formed user.
In Amazon Keyspaces, you can utilize the console to conduct the following:
Keyspaces and tables can be created, deleted, described, and listed.
Data can be added, updated, and deleted.
Use the CQL editor to run queries.
Ways to use partition keys effectively in Amazon Keyspaces
One or more partition key columns, which designate which partitions the data is kept in, and one or more optional clustering columns, which describe how data is clustered and ordered inside a partition, make up the primary key that uniquely identifies each row in an Amazon Keyspaces table.
Because the partition key determines the number of partitions your data is stored in and how the data is spread across these partitions, the partition key you choose can have a significant impact on query performance. In general, your program should be designed to have consistent activity across all disc partitions.
Distributing your application's read and write overall activity partitions helps to reduce throughput costs, and this applies to both on-demand and provisions read/write capacity modes. If you use provisioned capacity mode, for example, you may assess the access patterns required by your application and estimate the total read capacity units (RCU) and write capacity units (WCU) needed by each table. If the traffic against a given partition does not exceed 3,000 RCUs or 1,000 WCUs, Amazon Keyspaces supports your access patterns utilizing the throughput that you provisioned.
Data protection in Amazon Keyspaces
Data protection in Amazon Keyspaces is governed by the AWS shared responsibility paradigm (for Apache Cassandra). As seen in this architecture, AWS is in charge of safeguarding the global infrastructure that underpins the whole AWS Cloud. You are in charge of keeping your material hosted on this infrastructure under your control. The security configuration and administration activities for the AWS services you use are covered in this material. See the Data Privacy FAQ for additional information about data privacy.
We recommend using AWS Identity and Access Management to protect AWS account credentials and set up individual user accounts for data security reasons (IAM). As a result, each user is only given the rights they need to do their job obligations. We also advise you to protect your data in the following ways:
With each account, use multi-factor authentication (MFA).
To communicate with AWS resources, use SSL/TLS. TLS 1.2 or later is recommended.
AWS CloudTrail could be used to log into API and user activity.
Use AWS encryption solutions, as well as all of AWS's basic security settings.
Utilize advanced managed security services like Amazon Macie, which aids in the discovery and protection of sensitive data stored in Amazon S3.
Use a FIPS endpoint if you need FIPS 140-2 verified cryptographic modules while connecting to AWS via a command-line interface or API.
We strongly advise against entering confidential or sensitive information, such as email addresses, into tags or free-form fields like the Name box. This includes using the console, API, AWS CLI, or AWS SDKs to interact with Amazon Keyspaces or other AWS services. Any information you give in tags or free-form fields for names may be utilized for billing or diagnostic purposes. If you submit a URL to an external server, we strongly advise you not to include credentials information in the URL so that the server can validate your request.
To build low-latency apps, creating applications with open-source software and the Cassandra workloads should be moved to the cloud.
Are empty strings supported by Amazon Keyspaces?
Empty strings and blob values are supported by Amazon Keyspaces.
How is CQL different from SQL?
In CQL, there is a table design query first. There are also no JOINS in CQL, and the partition on the disc is used to store our data. Data is saved in Cassandra as a key-value pair, i.e., partition key and clustering column form.
Conclusion
In this article, we have extensively discussed Amazon Keyspaces for Apache Cassandra. We hope that this blog has helped you enhance your knowledge and aspects that you should keep in mind while dealing with the Amazon Keyspaces for Apache Cassandra; you will also like this article on the comparison between AWS vs Azure and Google clouds and AWS console mobile application. If you would like to learn more, check out our articles here. Do upvote our blog to help other ninjas grow.
Learning never stops, and to feed your quest to learn and become more skilled, head over to our practice platform Coding Ninjas Studio to practice problems, attempt mock tests, read interview experiences, and much more!





























 9+ registered
9+ registered 

