How does Amazon Neptune relate to the graph?
Before talking about the working of Amazon Neptune, I would like to introduce a very efficient and robust data structure called graphs because Amazon Neptune mainly works with graphs and highly connected data.
Graphs are everywhere. Graphs are the data structure that consists of nodes and links. They are particularly well suited for representing and describing relationships. There are many applications and use-cases that you can use to solve graph data and evaluate graph queries. So, for example, any network, a communication network, a social network, or a security network, is well suited for a graph network.
Now the question comes up when we should use a graph?
The answer is you can use a graph when there is a relationship between the data and then traverse those relationships or expression patterns over relationships. Using a graph to solve these problems is faster, more effective, and easier to operate.
Check out this article, Amazon Hirepro
What is inside of Amazon Neptune?
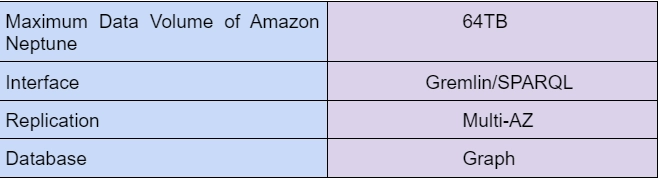
The core of Amazon Neptune is a purpose-built, high-performance, durable storage engine with ACID property with immediate consistency and optimized for graph queries; that engine itself is exposed through both property graph interfaces supporting Apache Tinker Pop and providing a Gremlin WebSocket Server and also supporting RDF graphs.
In addition, AWS also supports Neptune Workbench. The workbench is a jupyter Notebook-Based tool that has the provision through the AWS console or yourself through the COI and APIs that provides you a way to connect to your Neptune instance. Neptune experience to query it, issue commands, manage it, and visualize parts of your graph so that it can be a vital tool as an application builder to build graph applications.
In addition to the open standards and open-source APIs, amazon Neptune supports and provides services around managing and building the application. So, for example, Neptune provides fast, parallel, and non-transactional bulk loading services. This is exposed as a REST endpoint, and you post a JSON document to it, where the JSON document contains a specification of the load you would like to perform. Once you have assigned it, the services perform that load so you can check its status.
Use-Cases of Amazon Neptune
The following are the use cases of Amazon Neptune:
Knowledge graph
With Amazon Neptune, you can easily enable graph queries that enable users to navigate highly connected datasets. We can create an environment where data querying becomes very efficient. You can also create your graphical database and visualize things like this.
Fraud Detection
Sometimes, what happens is that an afraid person can make use of credit card information and try and purchase products. So they might be aware of your credit card number and email but using graph databases. We can create relationships or relationships with credit card holders, the location, and the previous purchases to detect any anomaly. If an illegal purchase is made, we can stop it and catch the transaction. So this is a significant use case for graph databases.
Social Networking
The third one we have is social networking. So you have users, and if you want a relationship of who follows whom, then amazon Neptune is a very efficient way to do that. Social Networking is all about relationships. So you can find out or draw a relationship by using internally connected data using the graph database.
Network / IT operations
When it comes to network operations most crucial thing is an event. There could be thousands of devices, and with the help of graph databases, we can capture a networking event and query them effectively. You can find out which data points you need for a particular instance or a specific host.
Amazon Neptune Engine
The amazon Neptune engine is optimized for storing billions of relationships and querying the graph with millisecond latency. So it is very, very fast. You are dealing with a service that can capture or query data and not a small amount of data. They are events and relationships and query them for you in a millisecond or less.
Amazon Neptune supports popular graph query languages:
- Apache Tinkerpop
- Gremlin
-
W3C's SPARQL.
The graph databases like Neptune can query the relationship between billions of vertices without bogging down. So without much lag, you will find yourself having the data you need when you need it.
Also read anomalies in database
Frequently Asked Questions
What is Amazon Neptune?
Amazon Neptune is a fast, reliable, fully-managed graph database service that makes it easy to build and run applications that work with highly connected datasets.
What are the advantages of Amazon Neptune?
- Highly available with reading replica
- Point-in-time recovery
- Continuous backup
- Fully managed
- Replication across availability zones.
What are the disadvantages of Amazon Neptune?
At first sight, the dual RDF-PG model looks like a great asset compared to other graph databases, but it may not be as good. Conversely, you can't use both; data must be fared and queried either as PG or RDF.
Conclusion
In this article, we extensively discuss Amazon Neptune and its purpose. We have also discussed the use-cases, advantages, and disadvantages of Neptune.
We hope that this blog has helped you enhance your knowledge regarding Amazon Neptune and if you would like to grasp more, check out our articles on Coding Ninjas.
We Recommend you to visit our articles on Pyglet, Pygame, interview prep, Basics of Python, and many more.You can also check out our Coding mock test series, Code Studio Interview Experience, Interview Bundle, SQL problems, and More Problems.
Do upvote our blog to help other ninjas grow.
Happy Coding!































 8+ registered
8+ registered 

