


























Introduction
Amazon S3 Glacier is a durable, secure, and low-cost Amazon S3 class for storing, archiving, and long-term data backup. It provides long-term storage for archived data, which we don't need to access frequently. It has no restrictions on the kind of data we store.

This article the Amazon S3 glacier in detail.
Amazon S3 glacier Data Model
The main components of the Amazon s3 glacier model are :
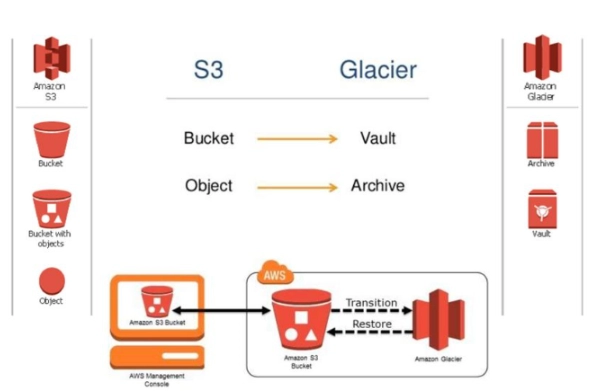
Vault
A Vault is basically a container for storing archives. When a vault is created, firstly, we specify its name and AWS region. Each vault has its unique address. An account can create a vault in any AWS region but within a region, it must have its unique name. A vault can store an unlimited number of archives in it.
The general form is:
https://<region-specific endpoint>/<account-id>/vaults/<vaultname>
Archive
An Archive is a data that can be of any form like a video, photo, or document and is stored in the vault. Each archive has its unique ID which is unique in each AWS region it is stored. The general form is:
HTTPS://<region-specific endpoint>/<account-id>/vaults/<vault-name>/archives/<archive-id>
An AWS account can create vaults in any supported AWS Region. Within a Region, an account must use unique vault names. An AWS account can create same-named vaults in different Regions.
An unlimited number of archives can be stored in a vault.
Job
An S3 Glacier Job is used to retrieve an archive, perform a selected query on an archive, or retrieve an inventory of a vault. A job is initiated when we perform a query on an archive. Amazon S3 Glacier selects and runs the query and gives the result Amazon s3.
Every job is identified uniquely by a URI of the form:
https://<region-specific endpoint>/<account-id>/vaults/<vault-name>/jobs/<job-id>
For every job, S3 Glacier maintains data like job type, description, creation date, completion date, and job status. Information about a specific job or a list of all the jobs associated with a vault can be obtained very easily. The set(list) of jobs that S3 Glacier returns include all the in-progress and recently finished jobs.
Notification configuration
Amazon s3 glacier has a notification mechanism, which notifies the user when the job is done as these jobs take a long duration to complete.
Every notification configuration resource is uniquely identified by a URI of the form:
https://<region-specific endpoint>/<account-id>/vaults/<vault-name>/notification-configuration
S3 Glacier supports operations to get, set, and delete a notification configuration. When a notification configuration is deleted, no notifications are sent when any data retrieval operation on the vault is complete.


 9+ registered
9+ registered 

