


























Introduction🧾
The world is achieving new heights in technological achievements day by day. We can do this with the help of many algorithms, machine learning, and much more, but learning machine learning is quite tricky, and so is its implementation.

But if we have to work in technological advancements in this era, we have to learn at least the basics of machine learning algorithms and their implementation. So is there any easy way for its implementation?
The answer to the above question is yes, and we can use sagemaker to train and implement our local machines quickly. We will learn all about amazon sagemaker while moving further in the blog. So let's get on with our topic without wasting any time further.
Amazon SageMaker and its Benefits🎯
Amazon SageMaker is one of the many services provided by Amazon Web Services(AWS). With the help of this, you can train, build and deploy ML tools for industrial and personal work. As it provides AWS, you need not provide and manage your servers.
You can use machine learning in many areas due to its vast benefits. It automates such complex tasks as building a production-ready AI. It can also be used for back-end security threat detection and analytics for customers.
Deploying Machine learning algorithms is not easy even for experienced developers, but sagemaker makes it easy to apply and accelerate machine learning algorithms. We will learn more about sagemaker with its applications.
Features of Amazon SageMaker
Many features are available in Amazon SageMaker, but it has launched some new features in the latest launch of 2017. You can access and use all the features and functions in AWS SageMaker Studio. It is an IDE that consolidates all the capabilities.

There are many features available in sagemaker, and here we will discuss some of them:
📙Automation tools help the users to manage, debug and track ML models.
📗Autopilot makes the AI train the given data set and rank them in order of accuracy.
📙Auto ML makes it easier to do projects for both types of people, one who has coding experience and another who does not have any coding experience.
📗Easily discoverable, connectable, and can be terminated and managed by different amazon EMR clusters into a single account.
📙You can create a jupyter notebook easily and transfer all the data there with only one click.
Machine Learning with Amazon SageMaker
This section will understand the machine learning workflow and how it works with Amazon SageMaker. In machine learning, we work with computers and teach them to make predictions.
We initially insert some information and algorithm to make predictions and then integrate them with our application to make predictions in real-time. There are three steps in generating the data, training a model, and deploying a model.
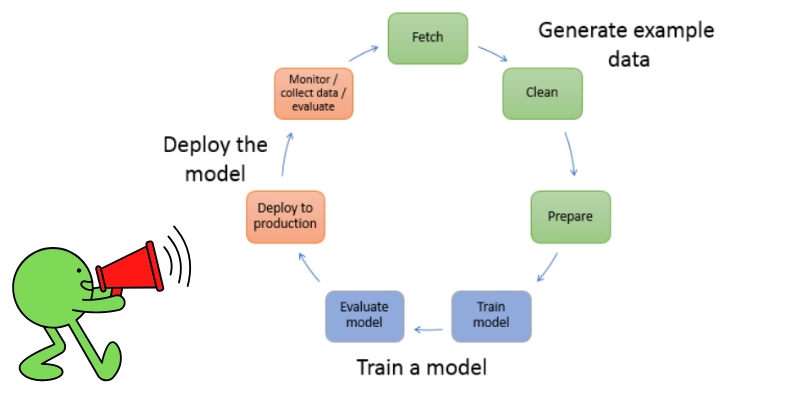
Generate the Data
Before doing any operation like training or deploying, you need some data. Here we will generate that data. It may vary from user to user need and from business to business requirements. There are three steps in developing the data.
1️⃣Fetch the Data: You can fetch the data either from your private repository or from any public repository.
2️⃣Clean the data: As the name suggests here, you check for any errors, and according to your requirements, you clean the data.
3️⃣Transform the data: Here, you will add some additional data with your cleaned data and combine their attributes so that this data can be trained.
Train the Data
We train the model using algorithms to behave accordingly in real-time situations. We cannot choose a random algorithm to train. It will depend on the number of factors, and we will discuss all of them in detail below:
Training the model
There are many steps involved in training the model. We have discussed all of them in this blog section.
📘Use an in-built algorithm provided by amazon sagemaker: Amazon Sage maker provides different algorithms that can be sued for training ML. If anyone of them satisfies your need, you can use them.
📘Amazon SageMaker Apache spark: Amazon sagemaker provides various libraries to train, and one of them can be used to train in Apache Spark.
📘Use your custom algorithms: You can use your algorithms to train. You have to combine your codes and create a docker image and specify the registry of the path in Amazon sage maker.
Evaluating the Model
Training is not alone enough, as, after training, we have to evaluate our model and then see its accuracy and whether it is capable of deploying or not. You can evaluate the model by two means, either online or offline.
📕Online Testing: You can use amazon sagemaker production variants. In this, your trained model small portion gets checked in different situations.
📕Offline Testing: In this, you will deploy your trained model on the alpha endpoint and use the previous or historical data to send inference requests.
Deploy the Model. You may not directly deploy the evaluated and trained model. You will re-engineer yourself and make different changes according to the need before posting it in hosting services. You can also deploy your model independently.
Your work is not finished after deployment. You have to monitor the data and collect ground truth.
Explore, Analyze, and Process Data
Before directly training the data model, the scientists usually analyze and preprocess it first.
Amazon SageMaker allows the jobs to post-process and preprocess the running data at every stage. Processing provides you with many benefits when the data is combined with other high-level ML tasks like hosting and training. It provides compliance support and security built into sagemaker. You have the freedom to use either built-in data processing containers or your containers to process the custom jobs. After submission, the sagemaker analyses the input data process and releases the resource upon completion.



 9+ registered
9+ registered 

