Do you think IIT Guwahati certified course can help you in your career?
Introduction
The world is achieving new heights in technological achievements day by day. We can do this with the help of many algorithms, machine learning, and much more, but learning machine learning is quite tricky, and so is its implementation.
But if we have to work in technological advancements in this era, we have to learn at least the basics of machine learning algorithms and their implementation. So is there any easy way for its implementation?
The answer to the above question is yes, and we can use sagemaker to train and implement our local machines quickly. But to train them more rapidly and make our data set, we can use amazon sagemaker ground truth. We will learn all about amazon sagemaker while moving further in the blog. So lets's get on with our topic without wasting any time further.
Amazon SageMaker Ground truth and its Labelling Services
Amazon SageMaker is used to train and implement the algorithms in our local machines very quickly. On the other hand, Amazon SageMaker Ground Truth can be understood as a fully managed data labeling service used to make data sets that are highly accurate for machine learning.
You can use either in-built or custom data labeling workflows and get started with amazon sagemaker round truth within minutes. They can be used in different cases like images, text, videos, and 3D point clouds.
By working with it, labelers also get some additional features to access like removing distortion in 2D images, automatic 3D cuboid snapping, reducing the time required to label data sets by using auto segment tools, and using ML to label your data automatically.
Additional Data Labeling Services
With regular updates, two more data labeling services are now available in amazon sagemaker ground truth data labeling jobs.
Data Labeling Services by iMerit’s US-based workforce
Data Labeling Services by Startek, Inc.
The iMerit also has an India-based workforce which now mainly provides three options that include:
Access to their US staff of their data labeling specialist.
Their text labeling capabilities include classification and entity extraction in Spanish and English.
Their image labeling capabilities include bounding boxes, key points, polygon, classification, and polylines.
StarTek is a business process outsourcing firm that specializes in data labeling. StarTek is a publicly-traded company with workforces in India, the Philippines, Honduras, Brazil, and Jamaica (NYSE: SRT). Classification, image segmentation, bounding boxes, key points, polygons, and polylines are among their image labeling capabilities. Entity extraction and type in English are among their text labeling capabilities.
Steps for vendors to complete Ground Truth Job
There are only numerous steps that vendors need to follow to complete the amazon sagemaker ground truth job.
Step 1: Click on the vendor's tab for Labelling Workforces.
First, sign in to your Amazon AWS account, open Amazon SageMaker Console, and redirect to labeling workforces. Then, you will see a vendor option. As shown in the image below:
Step 2: Subscribe labeling services of the vendor.
You will now redirect to the AWS marketplace, and after that, you can select the labeling service of different vendors accordingly. As shown in the image below:
In this section of the blog, we will learn about some of the use cases of amazon sage maker with examples:
High-Quality Instructions
Amazon SageMaker Ground Truth enables you to quickly create highly accurate machine learning training datasets (ML). You can use your workers, a vendor-managed workforce specializing in data labeling, or a public force powered by Amazon Mechanical Turk to generate the human-generated labels. When using a general workforce, you must provide simple, concise, and clear instructions to ensure high-quality brands. The most crucial action you can take to improve annotation quality is writing good instructions. It's worth taking the time to do it right the first time.
You must use the tools provided by ground truth and some tools of your own to get the best result and fastest instructions. Follow the given steps to achieve the same.
Step 1:First, gather your data and select some parts of it.
Browse your whole dataset and choose the examples covering all of your datasets. Selecting the items you want to label will help the annotators understand tour-specific tasks.
Step 2:Label your chosen example by running a private job.
You must add the images you've selected to a manifest file, establish a remote work team with your email address, and determine one annotator per example. You have no reason to label the same model more than once.
Running this private job gives you a better understanding of what you want to achieve with the difficulty of the task, your labeling job, and the tools the annotators will use. As you work, keep track of the problematic or ambiguous examples. These will come in use when it comes time to write the full instructions. It would help if you also considered timing yourself to determine how much to pay the workers.
Step 3: With the help of your result, create short instructions.
You can find the results of the private labeling job in the Amazon SageMaker console by going to Labeling jobs and selecting the name you gave it. The examples with annotations can be found at the bottom of the page. The simplest way to extract the results from image labeling tasks is to zoom in on the annotated images and take screenshots.
Create one or two images with various wrong annotations illustrating what you expect to be the most common sources of failure, then narrow your results to one or two exemplary "good" instances. You can accomplish this by re-running the private labeling job while ignoring the remaining examples.
Step 4: Finish the instruction by using the instruction-making tool.
First, upload your data or images on the Amazon S3 bucket to make it public so that different vendors can work on it. Finally, in the Amazon SageMaker console, go to the instruction-making tool in the job creation area, build your instructions, and connect to the photographs you gathered in your S3 bucket. By selecting the picture icon in the instructions tool and inputting the object URL, which you can discover in the S3 bucket overview by choosing the image name, you can place your photographs in the short instructions.
Step5: Now, clarify ambiguity by declaring full instructions.
You have to choose some additional settings to start working on full instructions. The full instructions should clarify the ambiguities in the task. So not repeat the short instructions in these unless necessary. Handle every edge case otherwise, and they will create the problem. Take two or three additional examples and first practice on them.
Step 6: Now, simplify your task and set the price accordingly.
At last, if your instructions are too complex, too large, or missing any vital example, try to take care of all these. And after that, set a reasonable price.
Custom Data labeling Workflow
You need a human to train the machine to make decisions manually. Amazon SageMaker provides custom templates for text, images, and audio data labeling jobs for beginners to get started.
Amazon Comprehend is an NLP(natural language processing) service that employs machine learning to uncover insights and connections in text. But in this piece, I'll show you how to create a custom text labeling procedure that extracts named entities from science publication abstracts to create a named entity recognition (NER) model's training dataset. It will show you how to easily import your existing Web templates into Amazon SageMaker Ground Truth.
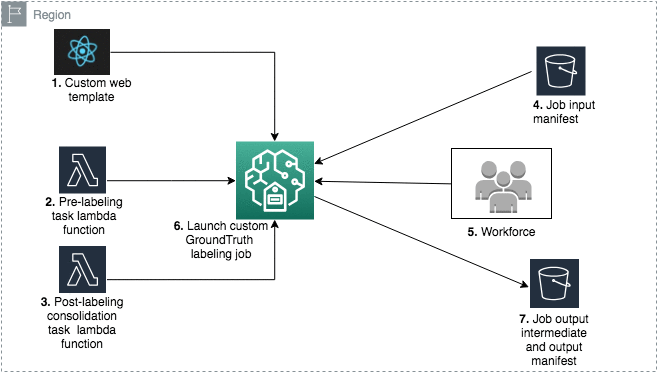
Working of Custom Web template
Here, we will discuss the AWS lambda function's solution for post-labeling and pre-labeling processing.
You use React to develop a single-page Web app that displays a .jpg image, text for annotation, a free-form text field for further notes, and a yes/no element to classify the quality of the abstract. The static JavaScript and CSS files can be found at s3:/smgtannotation/web/static on Amazon S3.
A worker labeling abstracts can use this app to annotate them by labeling selected content. As illustrated in the accompanying screenshot, the worker can choose the entity type (Background, Limitations, Objectives, Methods, Results, and Conclusions ) from a dropdown list. The worker can also make notes and label the abstract's quality.
The labeling job's input data is a group of data items you provide to your workforce to label. A manifest file describes each object in the supplied data. Each line of the manifest file is a legitimate JSON lines object that needs to be named and any additional custom metadata. A typical line break separates each line.
Now we will give both these inputs in pre and post-processing.
Pre labeling
The pre-labeling task Lambda function has a hook in the custom labeling workflow. This Lambda function is called with a JSON-formatted request, including a manifest element in the dataObject object before submitting a labeling task to the worker.
Below is the data that we will send to the AWS Lambda:
Similar to pre-labeling, we will do this with post-labeling. When all workers have finished labeling, Amazon SageMaker Ground Truth calls the post-labeling Lambda function with a pointer to the dataset object and the annotations of the workers. This Lambda function is commonly used to consolidate annotations. The following is an example of a request object:
At last, all the fields are connected. The Lambda function then starts data consolidation to build a consolidated annotation manifest in the S3 bucket defined as the labeling job's output when configured. The condensed response is included in the content object in the following example:
Now you have to deploy both the labeling and launch them.
FAQs
How does Amazon SageMkaer Ground Truth uses an interactive labeling interface?
It uses many assistive labeling features like auto segmentation and snapping.
Name some of the Machine learning techniques used by Amazon SageMaker Ground Truth.
ML uses many techniques like pre-labeling, machine validation, active learning, etc.
For how much time does AWS store our data in Ground Truth?
Amazon SageMaker Ground Truth stores your data in raw form, and for only the time of processing after that, it will delete it and its related content.
What is physical access control in Ground truth?
It is the control measures maintained by the service provider to prevent unauthorized access.
Conclusion
In this article, we have extensively discussed Amazon SageMakaer Ground Truth with a proper introduction, its features, additional data labeling techniques, steps for vendors to use it, and a step-by-step explanation of working with code and all the instructions.
We hope this blog has helped you enhance your knowledge of Amazon SageMaker Ground Truth. If you want to know more about Amazon AWS, its benefits, features, and reasons you should use it and be certified in it, you must refer to thisblog here. You will get a complete idea about all the features, benefits, and reasons you should be certified in Amazon AWS.
If you want to learn about Amazon Personalize, you should visit thisblog. Here, you will get a complete idea about its features, use cases, and benefits.
If you want to learn more about Amazon SageMaker, you must refer to thisblog. Here, you will get the whole idea of the topic with additional features, benefits, use cases, machine learning, etc. If you would like to learn more, check out our articles on Code studio. Do upvote our blog to help other ninjas grow.

































 9+ registered
9+ registered 

