


























Introduction
AWS stands for Amazon Web Services. AWS offers several tools and solutions for enterprises and software developers that can be used in data centers.
It provides servers, storage, networking, remote computing, email, mobile development, and security.
Storage and Content Delivery are a few of the prominent services provided by Amazon.
In this article, we will discuss them in detail.
Also see, Amazon Hirepro
Amazon Storage and Content Delivery Services
AWS offers a variety of services to meet customers' storage needs, such as Amazon Simple Storage Service, Amazon CloudFront, AWS Storage Gateway, Amazon Glacier, and Amazon Elastic Block Store.
Further in this article, we will provide an overview of the major Storage and Content Delivery Services by Amazon.
Amazon Simple Storage Service
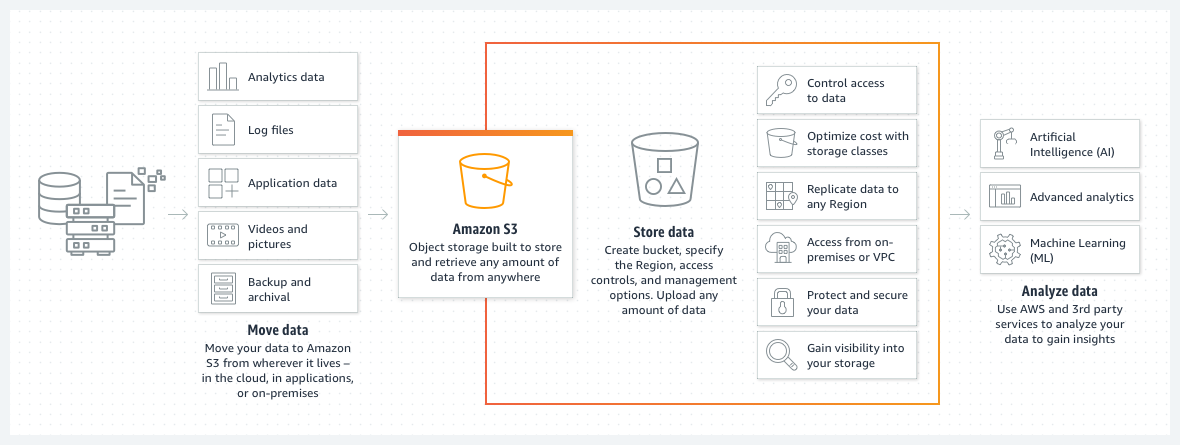
Amazon Simple Storage Service is also called Amazon S3 in short. It offers developers and IT teams high durability and scalability object storage that handles unlimited amounts of data virtually and a very high amount of concurrent users. It enables organizations to store huge amounts of objects of any type, like source code files, HTML pages, image files, and encrypted data, and access them through HTTP-based protocols.
Amazon S3 allows cost-effective object storage for a wide variety of use cases, involving backup and recovery, nearline archive, disaster recovery, big data analytics, cloud applications, and content distribution.
How Amazon Simple Storage Service works
In Amazon Simple Storage Service, data is stored as objects. Objects are the basic entities of data storage in Amazon S3 buckets and a bucket is a fundamental logical container where data is stored in Amazon S3 storage. Objects can be placed on several physical disk drives distributed over the data center.
It provides redundancy and version control using block storage methods. Data is stored automatically in multiple locations, distributed across multiple disks, and in some cases, multiple availability regions or zones. The Amazon S3 service verifies the integrity of the data periodically by checking its control hash value. If there is data corruption, the object is restored using redundant data.
To know more about Cloud Computing click here.
Use cases
Below we describe a few specific use cases of Amazon S3:
-
To back up and restore data
Because of Amazon S3, meeting Recovery Time Objectives (RTO), Recovery Point Objectives (RPO), and compliance requirements with S3’s robust replication features become very easy.
-
To run cloud-native applications
It enables the building of fast, powerful mobile and web-based cloud-native apps that scale automatically in a highly available configuration.
-
To build a data lake
It is used to run big data analytics, artificial intelligence (AI), machine learning (ML), and high-performance computing (HPC) applications to unlock data insights.
Amazon CloudFront
Amazon CloudFront is one of the Content Delivery web services that integrate with other AWS Cloud services to provide businesses and developers an easy way to distribute content to users across the world with high data transfer speeds, low latency, and no minimum usage commitments.
Amazon CloudFront can also be employed to deliver the entire website, including static, dynamic, interactive content, and streaming, using a global network of edge locations. All the requests for content are automatically routed to the nearest edge location, therefore the content is transferred with the best possible performance to the end-users around the globe.
How Amazon CloudFront works
It delivers the requested content through a worldwide network of data centers called edge locations. So, when a user asks for content that is being served with CloudFront, the request is routed to the edge location that offers the lowest latency, so that content is delivered soon as possible.
For this, two scenarios arise:
- If the content is in the edge location already, with the lowest delay time, CloudFront delivers it immediately.
- In case, the content is not in that edge location, CloudFront retrieves it from an origin that has been defined like an Amazon S3 bucket, an HTTP server, or MediaPackage channel, which is identified as the source for the definitive version of the requested content.

Use Cases
-
To accelerate dynamic content delivery and APIs
It helps in optimizing dynamic web content delivery with the feature-rich and purpose-built AWS global network infrastructure supporting edge termination and WebSockets.
-
To distribute patches and updates
Scale automatically to deliver software, game patches, and IoT over-the-air (OTA) updates at scale with high transfer rates.
AWS Storage Gateway
It is a service connecting cloud-based storage to on-premises software appliances providing secure and seamless integration between the AWS storage infrastructure and an organization’s on-premises IT environment. The service offers support to the industry-standard storage protocols that work with already existing applications. It also provides low latency performance by maintaining a cache of frequently accessed data on-premises while storing all of the data encrypted securely in Amazon Simple Storage Services.
Types of Storage Gateways
-
Amazon S3 File Gateway
Amazon S3 File Gateway represents a file interface that allows storing files as objects in Amazon S3 and accessing those files as objects directly in Amazon S3. Consumers can use Amazon S3 File Gateway to back up on-premises file data as objects in Amazon Simple Storage Services like Microsoft SQL Server and Oracle databases and logs, and for hybrid cloud workflows through the data generated by on-premises applications for processing by AWS services like machine learning(ML) or big data analytics.
-
Amazon FSx File Gateway
It offers fast, low-latency on-premises access to scalable, fully managed, and highly reliable shares in the cloud using the industry-standard SMB protocol. Consumers can store and access file data in Amazon FSx along with Windows-native compatibility including full NTFS support, Access Control Lists, and shadow copies. It can also be employed for on-premises file-based business applications and workloads like user or group file shares, media workflows, and web content management.
-
Tape Gateway
Tape Gateway stores the virtual tapes in Amazon Simple Storage Service and automatically creates new ones, making management and transition to AWS simple. Its Virtual Tape Library interface aids in the reduction of ongoing media costs, physical tape infrastructure capital expenses, and multi-year maintenance contract commitments.
-
Volume Gateways
Data written to the volumes can be asynchronously backed up as point-in-time snapshots of the volumes, and stored in the cloud as Amazon Elastic Block Storage(EBS) snapshots. This backup can be achieved via using the AWS Backup service or the service’s native snapshot scheduler. In both scenarios, volume backups are stored as Amazon EBS snapshots in AWS. To minimize storage costs, all snapshot storage is compressed.
Consumers often choose Volume Gateway to back up local applications and use it for disaster recovery based on Cached Volume Clones, or EBS Snapshots.
Use Cases
-
Modernize interactive file sharing
To transform the on-premises user and group file shares to a hybrid cloud architecture for cost reduction and simplified management.
-
To back up data to the cloud
In providing cloud-based backup for database applications and on-premises files for low-cost, unlimited scale virtually.
Amazon Glacier
Amazon Glacier is a durable, secure, and extremely low-cost storage service for long-term backup and data archiving. With Amazon Glacier, organizations can reliably store any amount of data for a very low cost per gigabyte per month. To keep costs low for customers. It is optimized for data that is accessed infrequently where a retrieval time of several hours is suitable.
Amazon S3 integrates also closely with Amazon Glacier to enable organizations to make choices for the right storage tier for their workloads.
How Amazon Glacier works
It stores the infrequently accesses data as an archive. An archive can include a combination of files or only one file. Each archive has a unique ID so so that it can be located and retrieved easily later from its storage location in the Vault.
A Vault is basically a container for storing archives. Each of the vaults can be tagged to define them to better utilize filtering capabilities.
The below diagram depicts how data gets stored in Amazon Glacier stores data.

Use Cases
-
For durability and scalability
The Amazon S3 Glacier storage classes run on the world’s largest global cloud infrastructure with unlimited scalability virtually and are designed for approximately 99.99% of durability. Data is stored redundantly across multiple Availability Zones that are separated physically within an AWS Region.
-
For quick retrievals
The Amazon S3 Glacier storage classes offer retrieval options from milliseconds to hours to fit the performance requirements. The S3 Glacier Instant Retrieval storage class delivers milliseconds retrieval for archives that need immediate access, like medical images or news media assets. S3 Glacier Flexible Retrieval provides three retrieval options for any task.
-
For security and compliance capabilities
The S3 Glacier storage classes provide very systematic integration with AWS CloudTrail for logging, monitoring, and retaining storage API call activities for auditing, and they support three different forms of encryptions as well.
Amazon Elastic Block Storage
Amazon Elastic Block Store also Amazon EBS, in short, provides persistent block-level storage volumes for use with Amazon Elastic Computing (EC2) instances. Each Amazon EBS volume is replicated automatically within its Availability Zone to protect organizations from component failure, giving durability and high availability.
By delivering low-latency and consistent performance, Amazon EBS offers the disk storage needed to run a wide variety of workloads.
How Amazon Elastic Block Storage works
EBS encrypts the data volume with a data key employing the industry-standard AES-256 algorithm. This data key is stored on disk along with the encrypted data, but not before EBS encrypts it with your KMS key.
The data key does not appear on the disk in plaintext. The snapshots of the volume share the same data key and any subsequent volumes created from those snapshots are encrypted using the same KMS key as the snapshot.
Below is the figure conveying the same.

Use Cases
-
To run relational or NoSQL databases
For deploying and scaling any database, including Oracle, SAP HANA, Microsoft SQL Server, MongoDB, Cassandra, and MySQL.
-
To build Storage Area Network in the cloud for I/O intensive applications
Migration of mid-range, on-premises storage area network (SAN) workloads to the cloud can be done easily along with high-performance and high-availability block storage for mission-critical applications.
Check out the Amazon Interview Experience to learn about Amazon’s hiring process.


 9+ registered
9+ registered 

