


























Introduction
Textual data surround us. After waking up and before reaching for our first cup of coffee, we usually navigate through enormous volumes of textual material in the form of text messages, emails, and social media updates.
In Companies also, large amounts of text data are generated. Companies use various analysis and extraction technologies to extract high-quality, relevant information from massive amounts of text data.
Here we will learn about some vital analysis and extraction techniques of text information, including natural language processing (NLP).
Natural language processing
NLP's main objective is to extract meaning from text. Natural Language Processing uses linguistic elements such as grammatical structures and parts of speech. This form of analysis usually determines who did what to whom, where, when, how, and why.
Computational linguistics resulted in NLP, allowing computers to interpret written and spoken human language forms.
Natural language processing uses different levels to extract the content of each sentence and translate it into a format that computers can interpret. The primary levels for performing natural language processing tasks are:
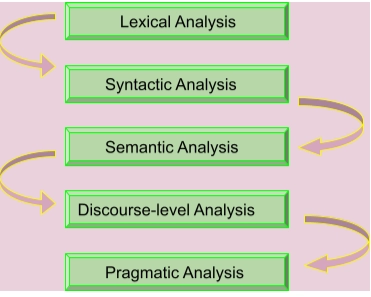
Lexical Analysis
Lexical analysis is concerned with the individual words in a text. It searches for morphemes, the minor units of a word.
For example, irrationally can be broken down into ir (prefix), rational (root), and ly (suffix).
The lexical analysis identifies the relationship between these morphemes and transforms the word into its root form.
A lexical analyzer also assigns the word's possible Part-Of-Speech (POS). A lexical analysis uses a dictionary, thesaurus, or any list of words that offer information about those words.
Syntactic Analysis
Syntax analysis guarantees that the structure of a particular piece of text is proper. It aims to parse the sentence to ensure that the grammar is correct at the sentence level. A syntax analyzer assigns POS tags based on the sentence structure given the possible POS created in the preceding stage.
For example:
Correct Syntax: Code studio is the best coding practice platform.
Incorrect Syntax: coding platform practice the is best Code studio.Semantic Analysis
Take the following sentence: "The apple ate a banana." The line is syntactically valid, yet it is illogical because apples cannot eat. Semantic analysis is the process of looking for meaning in a statement. It also deals with putting words together to form sentences.
"White Car," for example, refers to a single thing. So, we treat it as a single sentence. Similarly, names that refer to the same category, person, object, or organisation might be grouped. The term "Coding Ninjas" refers to the same organisation, not two different organisations with the names "Coding" and "Ninjas."
Discourse-level Analysis
Discourse is concerned with the impact of a prior sentence on the current sentence. In the text, “Harry is a good coder. He spends most of the time practicing codes.” Here, discourse assigns “he” to refer to “Harry.”
Pragmatics Analysis
The fifth and final phase of NLP is pragmatic. It uses a set of rules that characterise cooperative discussions to assist you in discovering the desired impact. "Open the door," for example, is read as a request rather than an order.



 8+ registered
8+ registered 

