Do you think IIT Guwahati certified course can help you in your career?
Introduction
Apache Kafka is a free and open-source streaming platform. It was first built at LinkedIn as a publish-subscribe messaging system or a messaging queue that enabled the user to send messages between processes, applications, and servers. Apache Kafka was initially developed as a software where topics can be defined, and further processing, like applications, may connect to the system and transfer messages onto the topic was possible.
A message could be anything from any event on a Personal blog to a very simple text message that would trigger any event. Now, Kafka has evolved into much more than just being a messaging system; it's a versatile tool for working with data streams that may be applied to various scenarios.
Kafka can process a large amount of data in a very short amount of time. Kafka has low latency, thereby making it possible to process the data in real-time. Apache Kafka is written and developed in Java and Scala, but it can be used with various other programming languages.
What is Kafka?
Apache Kafka is a distributed event streaming platform designed to handle high-throughput, fault-tolerant, and scalable data pipelines in real-time. Developed by LinkedIn and later open-sourced, Kafka has become a crucial component in modern data architectures.
Key features and concepts of Kafka include:
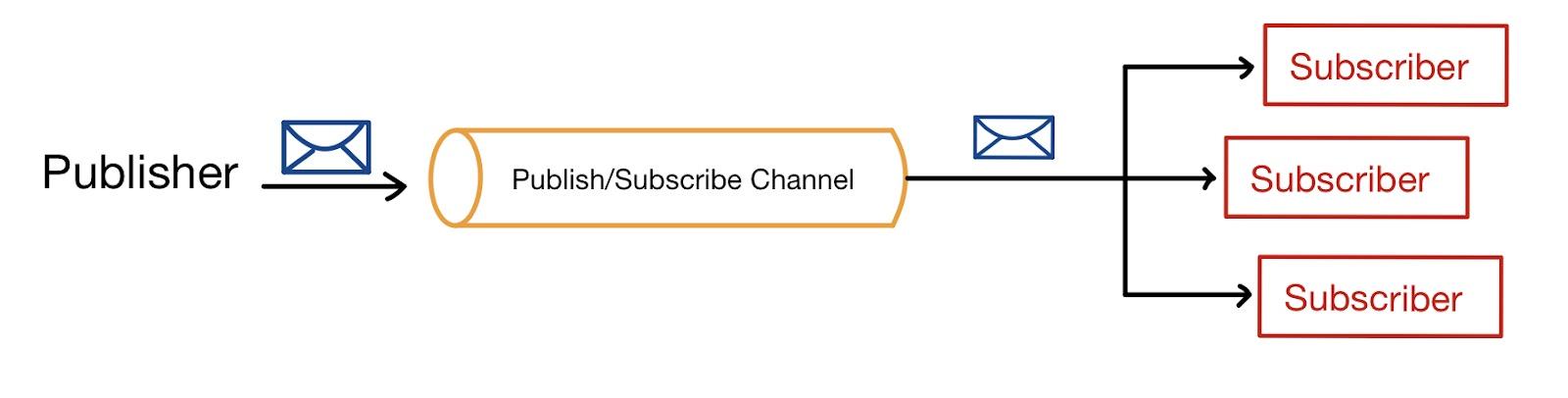
Publish-Subscribe Model: Kafka follows a publish-subscribe messaging pattern, where producers publish data to topics, and consumers subscribe to these topics to receive the data.
Distributed System: Kafka runs as a cluster of servers, allowing for high availability and scalability.
Topics and Partitions: Data in Kafka is organized into topics, which are further divided into partitions for parallelism and improved performance.
Persistence: Kafka stores all published data to disk and replicates it within the cluster for fault tolerance.
High Throughput: Designed to handle millions of messages per second, making it suitable for big data and real-time analytics applications.
Low Latency: Kafka can process these high volumes of data with very low latency, often in the millisecond range.
Stream Processing: With the Kafka Streams API, you can perform complex data processing on streams of data.
Apache Kafka Interview Questions for Freshers
1.What is Apache Kafka, and why was it developed?
Apache Kafka is a free and open-source fault-tolerant,high-throughput, and highly scalable distributed messaging system designed by LinkedIn. Jay Kreps, Neha Narkhede, and Jun Rao - a group of LinkedIn engineers who were working on data streaming tasks, came up with the idea of Kafka as the event data from the LinkedIn websites and entire infrastructure was ingested into the architecture of Lambda, which was to be harnessed by Hadoop and other real-time processing systems. Kafka had low latency in the processing of real-time events during the process, and therefore by using Kafka, LinkedIn was able to send large streams of a message to clusters in Hadoop.
2. Explain the traditional method of message transfer. How is Kafka better than them?
Some of the traditional methods of message transfer are as follows:
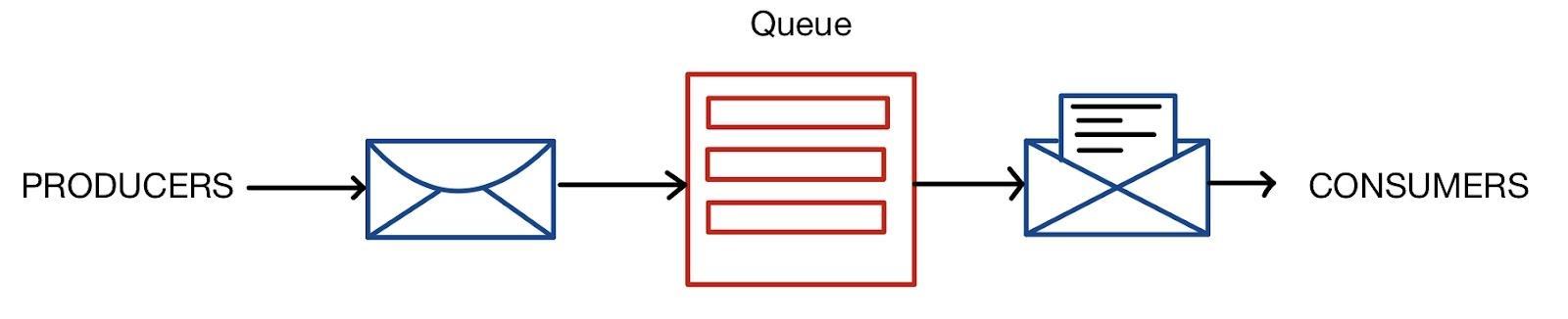
Message Queuing: A message queuing pattern uses a point-to-point technique. Just like in the Post Office Protocol, a message is removed from the server once it has been delivered, the same way a message in the queue is destroyed once it has been consumed. Message queuing allows asynchronous messaging. If there is a delay in delivering a message, like if a consumer is unavailable, then the message will be held onto the queue until it can be sent. Messages aren't delivered in the same order always. They are delivered on a first-come, first-served basis.
Publisher-Subscriber Model: In the publish-subscribe model, the publishers produce ("publishing") messages in multiple categories, and the subscriber consumes the published messages from the multiple categories to which they are subscribed. In this model, a message is only removed once consumed by all category subscribers, unlike point-to-point texting.
Some of the benefits of using Kafka over traditional messaging techniques :
Scalable: Multiple devices in the form of the cluster are used to partition and streamline the data, thereby making it easy to scale up the storage capacity.
Fast: A large number of clients (thousands) can be served by a single Kafka broker. As a single Kafka broker is capable of handling megabytes of reads and writes per second.
Durability and Fault-Tolerant: In Kafka, the data is copied in the clusters, because of which the data remains persistent and tolerant to any hardware failure.
3. Name and explain the major components of Kafka.
The major components of Kafka are:
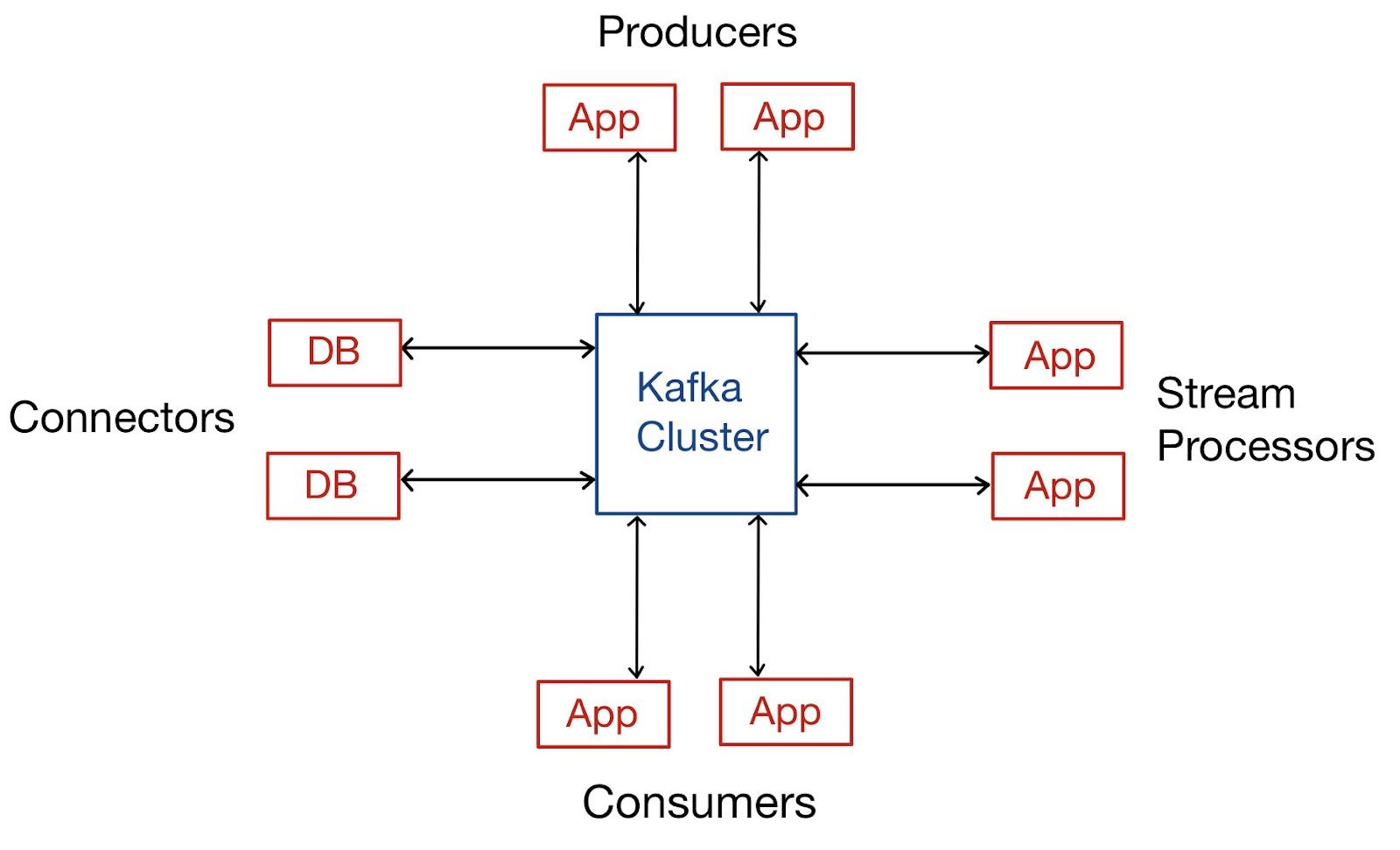
Topic A topic in Kafka is basically a category or a feed in which the records are saved and published. In Kafka, all the producer applications write data to the topics, and all the consumer apps read data from the topics. In short, topics are used to organize all of Kafka's records. Records that are published to the cluster remain there in the cluster for the duration of a configurable retention period. In case of Kafka, the records are kept in the logs, and it is up to the consumer to keep track of where they are in the log. The consumer usually advances the offset in a linear fashion when the messages are read. On the other hand, the consumer is in charge of the position, as they can consume the messages in any order.
Producer In Kafka, a producer serves as a data source for one or more Kafka topics. A Kafka producer optimizes, writes, and publishes the messages. Partitioning allows a Kafka producer to serialize, compress, and load balance data among brokers.
Consumer A consumer can read data by reading the messages from those topics they have subscribed to. Consumers are divided into groups, where each consumer in the group will be responsible for reading only a subset of the partition of each subject to which they have subscribed.
Broker A Kafka broker is a server that works as a part of a Kafka cluster. Multiple brokers typically work together to build a Kafka cluster that provides load balancing, reliable redundancy, and failover. A Kafka broker has the capability to handle read and write volumes of hundreds of thousands per second without any compromise in performance. Each Broker has its own ID. A broker can be in charge of one or more topic log divisions.
4. Why are there 3 brokers in Kafka?
Three brokers are suggested as the minimum for a Kafka cluster for the following reasons:
High availability: If one of your three brokers fails, the other two can still function and continue to provide data to your applications. This is due to the replication of each partition within a Kafka topic across various brokers.
Performance: By dispersing the load across several servers, several brokers can enhance the performance of your Kafka cluster.
Consistency: Every replica for a partition receives a message that a producer submits to Kafka. This guarantees that the message will still be accessible on the other replicas even if one broker fails.
5. Is Kafka synchronous or asynchronous?
By design, Kafka is asynchronous. As a result, when a producer sends a message to Kafka, it does not wait for the broker's reply before sending the message back. As a result, the producer can send messages without worrying about the broker blocking them.
However, Kafka can be set up to use synchronous communication. Setting the acks producer property to 1 or all will accomplish this. When acks is set to 1, the producer will pause before returning while awaiting a response from the partition leader. When acks is set to all, the producer will hold off on returning until every replica in the partition has responded.
6. Explain the architecture of Apache Kafka.
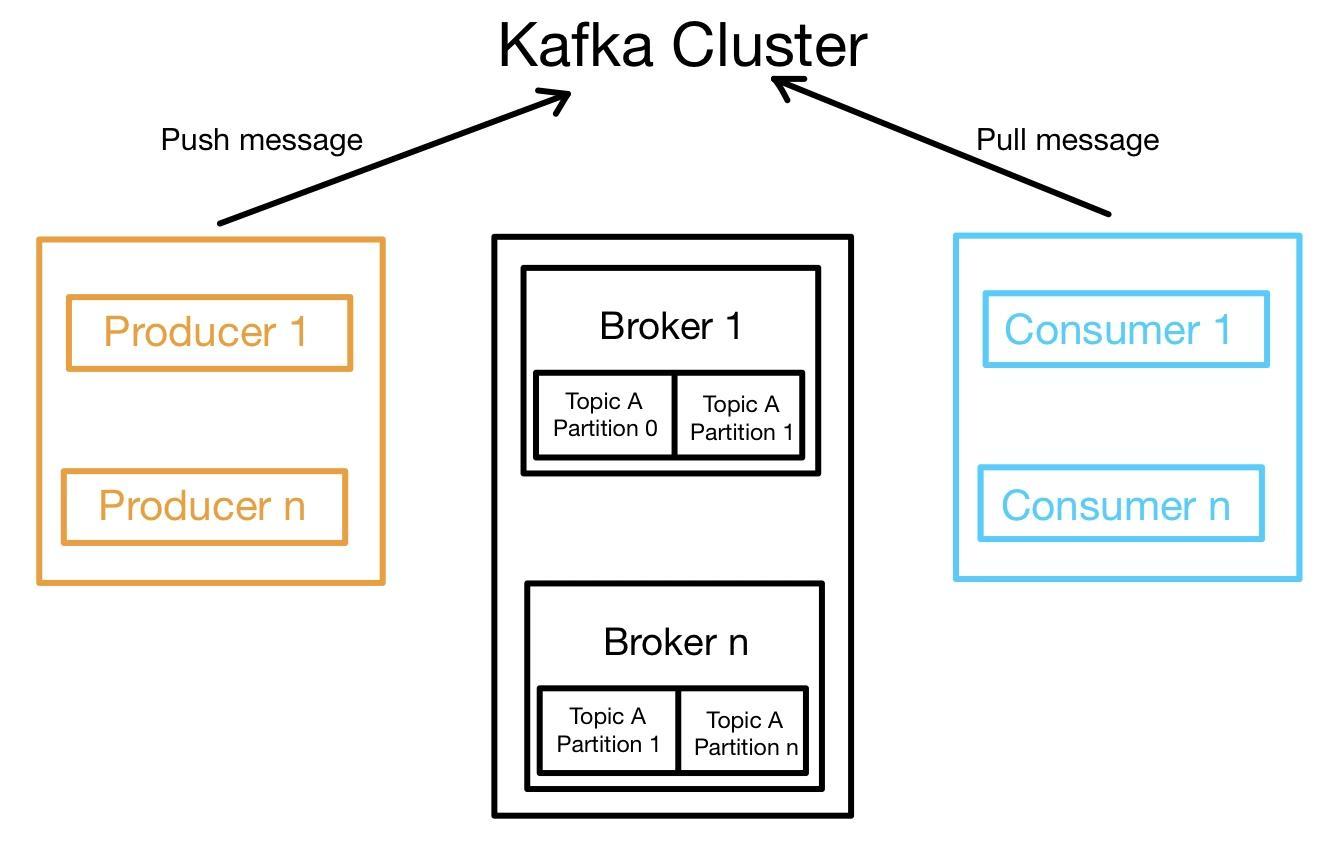
Kafka architecture has four basic components: Brokers, Consumers, Producers, and Zookeepers. In the Kafka architecture, the basic element is a message which is a payload of bytes. A stream of messages belonging to a specific category is called a Topic. Each message is identified by its index called offset.
Topics In Kafka, the data is stored in the form of topics. Each topic is partitioned into a set of segment files that are equal in size. All the messages in the partition are organized into immutable order sequence. Each topic must have a minimum of one partition. The backup of a partition is known as a Replica.
Brokers A Kafka broker is a stateless server that stores the published messages. A set of servers is called a cluster. A Kafka broker has the capability to handle read and write volumes of hundreds of thousands per second without any compromise in the performance. A broker in Kafka is stateless. Therefore a zookeeper is used to maintain the cluster state.
Zookeepers A zookeeper in Kafka is used to coordinate and manage the Kafka broker. The zookeeper sends a notification to the producers and consumers whenever a new broker is started, or an existing broker is stopped. The producer and consumer uses these notifications to communicate with the brokers accordingly.
Producers In Kafka, a producer is an element that produces/publishes a message to the topic. In other words, a producer pushes the data to brokers. The producer requires no acknowledgment from the Broker. The producer continuously pushes data to the Broker as fast as the Broker can handle. Each time a new broker is started, a Kafka producer searches for that new Broker and sends messages to that Broker.
Consumer In Kafka, a consumer is an element that subscribes to one or more topics in order to consume messages from the brokers. The consumers use the partition offset values obtained by the zookeeper to maintain how many messages they have consumed. When a consumer acknowledges a particular message offset, it signifies that all the prior messages have been consumed.
7. Explain how does Apache Kafka messaging system work?
Kafka supports a publish-subscribe messaging system as well as a queue-based messaging system. An example of the publish-subscribe system is:
A producer is responsible for pushing data to the brokers, and they regularly send messages to the topics.
A broker usually categorizes the messages into specific topics and stores them in their corresponding partition. All the partitions share an equal number of messages, in case there are two messages, each partition stores one message.
In order for a consumer to pull data from these partitions, the consumer must first subscribe to the topic. When the consumer has subscribed to a topic, an offset of the topic is provided to the consumer, this offset value is saved in the zookeeper ensemble.
A consumer requests for messages repeatedly in regular intervals. Whenever a new message is posted by the producer, it is forwarded to the consumer.
Once the consumer has successfully processed a message, an acknowledgment is sent by the consumer to the Broker.
The Broker updates the offset values with new ones when an acknowledgment is received.
This whole process is repeated until the consumer stops requesting for the message.
A consumer has the capability to rewind to any offset value to consume the desired messages.
8. Can we use Kafka without a zookeeper?
Yes, from version 2.8 and newer, we can use Kafka without a zookeeper. However, this version is not yet ready/available for production and lacks some key features.
In the older versions bypassing the zookeeper and connecting directly to the Broker was not possible. This was because it is impossible to fulfill the client's requests when the zookeeper is down.
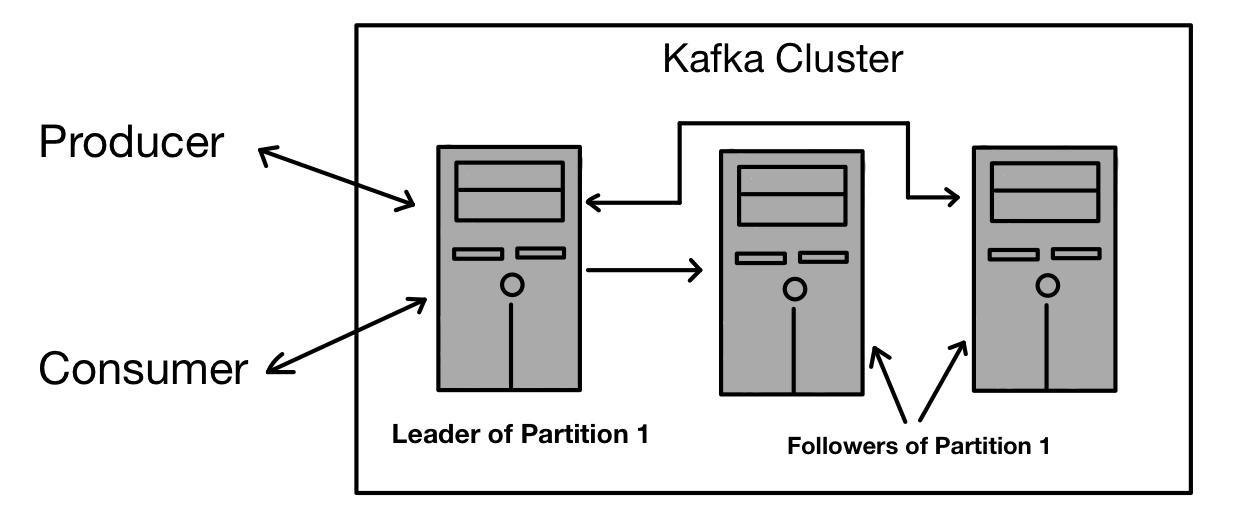
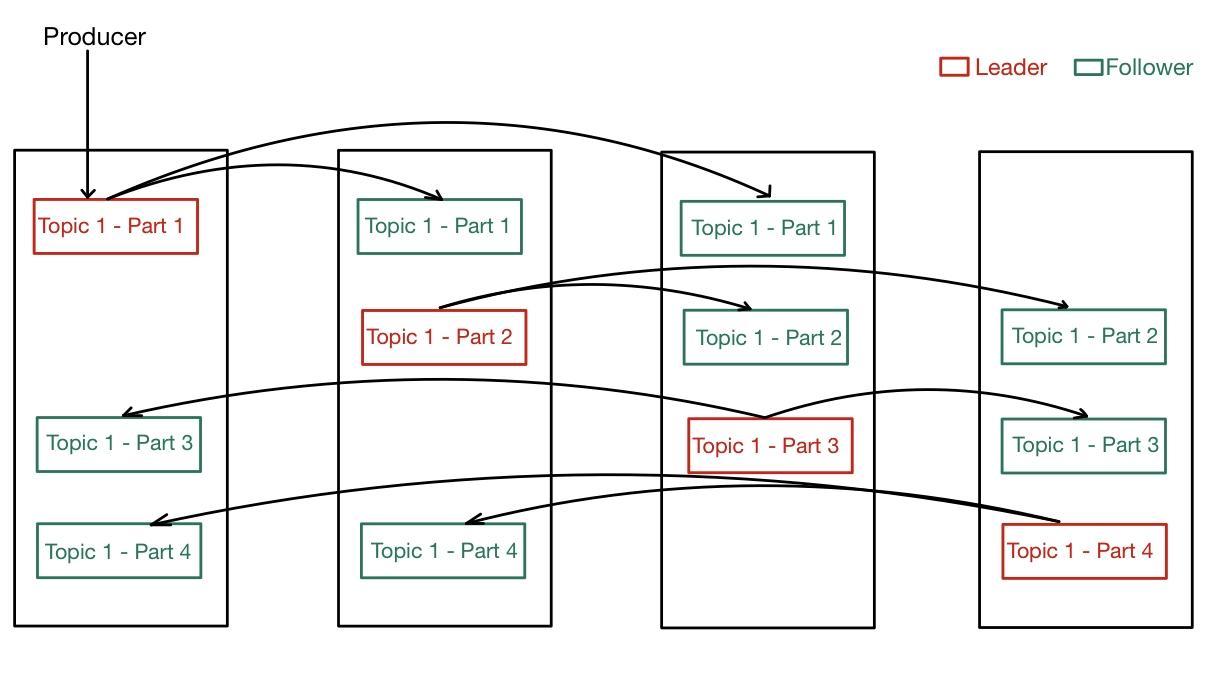
9. Briefly describe the concept of Leader and Follower in Kafka.
In Kafka, we have a leader and a follower. Each partition in Kafka has one server which acts as a Leader and one or more servers that act as Followers. All the read and write requests for the partition are the responsibility of the Leader, whereas the Follower's responsibility is to passively replicate the Leader. In case the Leader fails, then one of the followers will assume leadership, resulting in a load of the server getting balanced.
10. What is a consumer group in Kafka?
In Kafka, a consumer group is a collection of consumers who work together to ingest data from the same topic or a range of topics. Consumers in Kafka often fall into one of the several categories. The '-group' command is used to consume messages from a consumer group. A consumer group essentially represents an application name.
11. What is the default maximum size of a message that Kafka can receive? Can it be modified?
By default, the maximum size of a message that a Kafka can receive is 1MB (megabyte). Yes, the broker settings allow you to modify the size. It is designed to handle 1KB messages as well.
12. What is geo-replication in Kafka?
In Kafka, geo-replication is a feature that allows messages in one cluster to be copied across many other data centers or cloud regions. It entails replicating all files and storing them throughout the globe if required. It is a technique that is used for ensuring data backup. It can be accomplished by using Kafka's MirrorMaker Tool.
13. How many types of Kafka are there?
Only Apache Kafka is available as a type of Kafka. Numerous businesses use Apache Kafka, an open-source distributed event streaming platform, for mission-critical applications, high-performance data pipelines, streaming analytics, and data integration.
However, Apache Kafka can be installed and utilised in a few different ways. Kafka, for instance, can be set up as a managed cluster, a standalone cluster, or a cloud-based cluster. Kafka can also be utilised in a wide range of diverse applications, including data integration, microservices communication, and real-time streaming analytics.
14. What are the benefits of using clusters in Kafka?
In Kafka, a cluster is a group of multiple brokers used to main the load balance because the brokers in Kafka are stateless, they rely on zookeepers to keep track of their cluster state. A Kafka broker can manage TBs of messages without compromising performance. Therefore having a cluster of Kafka brokers can heavily increase the performance.
15. What are the disadvantages of Kafka?
Some of the disadvantages of Kafka are:
If there is any kind of message tweaking, the performance of Kafka degrades.
It is necessary to match the exact topic name, Kafka does not support wildcard topic selection.
Consumers and Brokers reduce their performance of Kafka when dealing with huge messages by compressing and decompressing the messages.
Kafka doesn't support certain message paradigms, including point-to-point queues and requests/replies.
It doesn't have a complete set of monitoring tools.
16. Why is ZooKeeper used in Kafka?
Kafka uses ZooKeeper to offer a distributed coordination service. ZooKeeper is used by Kafka for the following activities:
Leader election: Each partition in a Kafka topic has a leader, who is chosen using ZooKeeper. The leader is in charge of answering customer requests and duplicating data to the other replicas for the partition.
Management of configuration: ZooKeeper is used to store and manage the configuration of the Kafka cluster, including the topic information and a list of the cluster's brokers.
Partition assignment: Brokers are given partitions via ZooKeeper. As a result, partitions are allocated equally throughout the cluster's brokers.
Failure detection: Broker and consumer failures are found using ZooKeeper. ZooKeeper tells the broker or consumer when one of them fails.
17. What are the core API architectures that Kafka uses?
There are four core API architectures that Kafka uses:
Producer API: The producer API allows an application to publish a stream of records to multiple Kafka topics.
Consumer API: It allows an application to subscribe to one or more Kafka topics. It also allows an application to process a stream of records generated.
Streams API: it allows an application to use a stream processing architecture to process data in Kafka. It can also be used to take input streams from one or multiple topics, and we can further process the input stream using the stream operations and generate output streams to transmit to more topics.
Connect API: it is also known as the Connector API. It is used to connect Kafka topics to applications. The connect API is responsible for constructing and managing the operations of producers and consumers. It also establishes reusable links between these solutions.
18. What is a partition in Kafka?
In Kafka, every broker has some partitions that are available either for a leader or a replica of a topic. Some of the features of a partition in Kafka are:
Every Kafka topic is separated into partitions that contain records in a fixed order.
Since multiple partitions of logs are possible in a single topic, each record is assigned and attributed with a unique offset in a partition. This enables several users to read from the same topic simultaneously.
In Kafka, a replica is the redundant element of a topic partition since replication is done at the partition level.
Partitions can contain messages that are duplicated across many brokers in the cluster because a partition can contain one or more replicas.
Only one server can act as the leader of each partition, and the rest of the servers act as followers.
19. Why is Topic replication important in Kafka? What is ISR in Kafka?
Topic replication is one of the most important processes in Kafka, as it is used to construct Kafka deployments in order to ensure durability and high availability. Its main objective is that if one broker fails, then the other brokers remain available to ensure that the data is not lost and Kafka deployment is not disrupted. Topic replication ensures that the messages published are not lost.
The replication factor is used to specify the number of copies of a particular topic that is to be kept across the Kafka cluster. This is defined at the subject level but takes place at the partition level.
The full form of ISR is In-Sync Replica, and it is that replica that is up to date with the partition’s leader.
20. What is the purpose of the retention period in the Kafka cluster?
In the Kafka cluster, the retention period is a period that is used to retain all the published records without checking whether they have been consumed or not. We can easily discard the records by using a configuration setting for the retention period. Records are discarded from the Kafka cluster in order to free up some space.
Apache Kafka Interview Questions for Experienced
21. When does the broker leave the ISR?
ISR stands for In-Sync Replica, it refers to the set of messages which are completely in-sync with the leader’s partition. This means that the ISR contains all of the committed messages and also includes all the replicas until it gets a real failure, that is, ISR will drop a replica when it deviates from the leader.
22. What is load balancing in Kafka? How is it done in Kafka?
Load balancing is a process that Kafka handles by default. The process spreads the messages between partitions while preserving the message ordering. Kafka allows the user to specify the exact partition for a message.
In Kafka, there are leaders and followers, leaders are responsible for all the read and write requests for the partition, whereas the followers are responsible for passively replicating the leader. If a leader fails, then any one of the followers will take over the role of leader, and this process ensures load balancing of the servers.
23. What are the different ways to get exactly-once messaging from Kafka during the data production?
In order to ensure that we get exactly-once messaging during data production from Kafka, we need to avoid two things: avoiding duplicates during the data consumption process and avoiding duplication during the data production.
The two ways to get exactly one semantics while data production is as follows:
Avail a single writer per partition that is, whenever we get a network error, we should check for the last message in that particular partition to check whether the last write succeeded or not.
We should include a primary key such as UUID and de-duplicate the consumer in the message.
24. What are the uses of the Apache Kafka Cluster?
Apache Kafka cluster is a messaging system that is used to overcome the challenges of collecting and analyzing large volumes of data.
A few of the benefits of Apache Kafka Cluster are as follows:
It can be used to track web activities by simply storing or sending the events for real-time processes.
It can be used to alert as well as report the operational metrics.
It also allows us to transform the data into a standard format.
It allows processing of the streaming data to the topics continuously.
25. Differentiate between Apache Kafka and Apache Flume.
Apache Kafka
Apache Flume
It is a distributed data system.
It is a distributed, available, and reliable system.
It is designed and optimized for ingesting and processing streaming data in real-time.
It is capable of efficiently collecting, aggregating, and moving a large amount of log data from different sources to a centralized data store.
It is easily scalable.
It is not easily scalable.
It works as a pull model.
It works as a push model.
As it runs as a cluster, it can easily handle a high volume of data streams in real-time.
It is a tool to collect log data from distributed web servers.
It treats each topic partition as an ordered set of messages.
It takes streaming data from multiple sources for storage and analysis, which is then used in Hadoop.
26. What is MQ in Kafka?
Kafka uses a message queue, or MQ. It is a distributed streaming platform with message broker functionality. In the publish-subscribe messaging model used by Kafka, message producers post content to topics, while message consumers subscribe to receive content.
Kafka is a dependable messaging system since its messages are stored on disc. Kafka is also very scalable and has low latency while handling large volumes of data. In microservices architectures, Kafka MQ is frequently used for inter-microservice communication. It can also be applied to stream processing and real-time data processing.
27. Differentiate between Apache Kafka and RabbitMQ.
Apache Kafka
RabbitMQ
In Kafka, there are partitions that provide message ordering, and messages are sent to topics by message key.
It doesn't support message ordering.
In Kafka, data is shared and replicated, making Kafka distributed, durable, and highly available.
No such features in RabbitMQ.
Apache Kafka is a log that supports message logging, which means that the message are always there.
RabbitMQ is a queue, because of which messages are destroyed once consumed and acknowledgment is provided.
It guarantees that either the entire batch of messages will fail or pass. Only retains order inside a partition.
It doesn't provide any guarantee.
The performance rate is around 100,000 messages per second.
The performance rate is around 20,000 messages per second.
28. Explain the working principle of Kafka.
The working principle of Kafka is:
A producer is an entity that sends messages to topics at regular intervals.
Kafka brokers are responsible for storing the messages available in partitions configured for that particular topic.
If a producer publishes two messages, Kafka ensures that both of them are accepted by the consumer.
A consumer is an entity that pulls the message from the allocated topic.
Once the consumer digests the topic, Kafka pushes the offset value to the zookeeper.
A consumer repeatedly sends a signal to Kafka after every 100ms while waiting for the messages.
The consumer sends an acknowledgment once the message has been received.
On receiving the acknowledgment, Kafka modifies the offset value to a new value, then sent to the zookeeper. The zookeeper keeps the record of the offset value so that the consumer can always read the next message correctly, even if there is a server outage.
This flow is repeated till the time request is live.
29. How is Apache Kafka a distributed streaming platform, and what can be done with it?
There are three main capabilities that a streaming platform must possess, Apache Kafka possesses all of them, which are as follows:
A distributed streaming platform helps to push the records easily.
It provides a large amount of storage space and also helps to store a large amount of records without any trouble.
It helps to process the records as they come in.
Using Apache Kafka, we can do the following:
Using it, we can build a real-time stream of data pipelines that transmit data between two systems.
It can be used to build a real-time streaming platform that can react to the data.
30. What are the use cases where Kafka doesn't fit?
Some of the cases where Kafka isn't a good fit are:
Lack of monitoring tools.
It's difficult to set up and configure the Kafka ecosystem, good knowledge is required for its implementation.
The wildcard option is not available for choosing a topic.
Third-party services like zookeepers are required for coordinating between the cluster
31. What is the role of the zookeeper in Kafka?
When we implement a cluster in Kafka, we have to set up a coordination server for selecting a controller, cluster management, topic configuration, and who is allowed to read and write topics.
Having a zookeeper is not mandatory, but it plays a significant role in cluster management, like fault tolerance and identifying when one cluster is down it replicates the messages to another cluster.
32. What is a controller in Kafka?
In order to ensure the stability and dependability of the Kafka cluster, the Kafka controller, a key component of the Apache Kafka distributed messaging platform, is in charge of managing leader elections, partition reassignments, broker monitoring, cluster metadata, and topic and partition operations. For a Kafka cluster to remain stable and resilient, the controller—a crucial part of the distributed architecture of Kafka—must operate properly. Kafka is intended to recover and ensure that the cluster is still operating in the event of controller failure or problems.
33. What is meant by consumer lag? How can it be monitored?
Kafka follows a publish-subscribe mechanism in which the producer writes to a topic, and one or more consumers read from that topic. However, reads in Kafka always lag writes because there is a delay between the moment a message is written by a producer and the moment a subscriber consumes it. The delta between the latest and consumer offset is known as consumer lag.
There are a variety of tools that can be used to monitor consumer lag, like LinkedIn Burrow. Confluent Kafka comes with out-of-the-box tools to measure the lag.
34. What is Kafka Mirror Maker?
In Kafka, data replication is done within the cluster to ensure high availability. Enterprises often need a data availability guarantee to span the entire cluster. One of the solutions to this is Mirror Maker. Mirror Maker is a utility tool that helps replicate data between two Kafka clusters irrespective of whether they are in the same or different data centers. In mirror maker, the Kafka consumer and producer are hooked together. The origin and destination clusters are completely different entities with a different number of partitions and offsets, however, the topic names should be the same between the source and a destination cluster. It also retains and uses the partition key so that the ordering is maintained within the partition.
35. How can we send large messages with Kafka?
By default, Kafka doesn't handle large sizes of data, the max size of data is 1MB. There are ways to increase the size of data which are as follows:
The consumer system that reads the messages from a topic can read a message with the largest size of a message driven by the property fetch.message.max.bytes. We can adjust this property to allow the consumer to read a large data size.
In Kafka, the broker has a property replica.fetch.max.byte, which drives message-sized replicated across the cluster. In order to ensure that the replicated message is of the correct size, we need to make sure that the size defined is not too small for this property; otherwise, messages won't be committed successfully.
Another property on the broker side that is the message.max.bytes is used to determine the maximum size of data that Kafka broker can receive from the producer system.
The max.message.bytes property on the broker side is used to validate the maximum size of message one can append to the topic.
If we want to send large Kafka messages, that can be easily done by tweaking a few properties mentioned above.
36. How is multi-tenancy achieved in Kafka?
A multi-tenancy system allows multiple client servers at the same time. Kafka is, by default, a multi-tenancy system as multiple clients can read/write data to the Kafka broker. There is built-in support on multi-tenancy, but it doesn't provide isolation and security to multiple client servicing. This isolation and security can be achieved by:
Authentication: There should be some sort of authentication mechanism in the Kafka system so that it does not allow anonymous users to login into the Kafka broker.
Authorization: The user must be authorized to read/write from the topic.
Manage quotas: As Kafka can produce/consume a high volume of data, there should be a quota set up per user or per consumer group. Managing quota is a mandatory step to support multi-tenancy.
37. How can we achieve FIFO behavior in Kafka?
In Kafka, messages are stored in topics that are stored in different partitions. A partition is a sequence of ordered messages, where each message is uniquely identified by a sequential number called offset. FIFO behavior can be achieved only inside the partition using the following steps:
Firstly, set the enable the auto-commit property to be false.
No calls should be made to the consumer.commitSync() after processing the message.
Then make a call to “subscribe” to ensure the registry of the consumer system to the topic.
Listener consumerRebalance should be implemented, and a call to the consumer.seek(topicPartition, offset) should be made within a listener.
After the message is processed, the offset associated with the message should be stored along with the processed message.
38. List some of the real-time applications of Apache Kafka.
Some of the real-time applications of Apache Kafka are as follows:
Twitter: On Twitter, only registered users can read and post tweets, whereas unregistered users can only read tweets. Twitter uses Storm-Kafka as its stream processing infrastructure.
LinkedIn: LinkedIn uses Apache Kafka for activity stream data and operational metrics. Various other LinkedIn products like LinkedIn Newsfeed, LinkedIn today, etc., uses the Kafka messaging system.
Netflix: Netflix is a very popular American multinational provider of on-demand internet streaming media, it uses Kafka for real-time monitoring and event processing.
Box: Kafka is used at the box for production analytics pipeline and real-time monitoring infrastructure.
39. What is the role of the consumer in Kafka?
A consumer in Kafka is an entity that consumes the messages stored in partitions.
A consumer in Kafka can subscribe to one or more topics. It can also maintain a counter for the messages as per the offset value. If a consumer acknowledges a specific message offset, it depicts that all the previous messages were consumed successfully. The consumer's offset value is notified by the zookeeper.
If in case all the consumers fall into the same consumer group, then by using a load balancer, the messages will be distributed over the consumer instances, if the consumer instances fall into different groups, then each message will be broadcast to all the other consumers group.
40. What are the series in Kafka?
The term series stands for serialization and deserialization. A SerDe is a combination of a serializer and a deserializer. In order to achieve materialization when needed, every application must offer support for serialization and deserialization of the record key and values. Serialization involves converting a message into a stream of bytes for transmission over the network. The array of bites then gets stored on the Kafka queue. Whereas deserialization is the reverse of serialization, it ensures that an array of data streams get converted into meaningful data.
When the producer sends data to the broker, serialization ensures the transmission and storage of data in the form of a byte of an array. The consumer system reads the data from the topic in the form of a byte of an array, this byte of an array must be deserialized successfully to convert it into meaningful data.
Apache Kafka MCQs
1. Which of the following is a key feature of Apache Kafka?
A) Real-time streaming B) Data storage C) Data analysis D) Data encryption
Answer: A) Real-time streaming
2. What does a Kafka producer do?
A) Consumes messages from topics B) Produces messages to topics C) Manages Kafka brokers D) Monitors Kafka clusters
Answer: B) Produces messages to topics
3. What is the default retention period for messages in a Kafka topic?
A) 24 hours B) 1 week C) 2 days D) 7 days
Answer: A) 24 hours
4. Which of the following components is responsible for distributing data in Kafka?
A) Broker B) Producer C) Consumer D) Zookeeper
Answer: A) Broker
5. What is a Kafka partition?
A) A log file containing all the messages B) A Kafka producer instance C) A Kafka broker configuration D) A topic storage unit
Answer: D) A topic storage unit
6. Which protocol does Kafka use for communication between brokers?
A) HTTP B) FTP C) TCP D) UDP
Answer: C) TCP
7. What role does Zookeeper play in Apache Kafka?
A) Storing Kafka messages B) Managing topics and partitions C) Synchronizing Kafka nodes D) Consuming messages from Kafka topics
Answer: C) Synchronizing Kafka nodes
8. In Kafka, a consumer group is:
A) A group of producers B) A group of brokers C) A group of consumers working together D) A group of topics
Answer: C) A group of consumers working together
9. What happens when the replication factor of a Kafka topic is set to 1?
A) Each partition will have one copy of data B) Data is replicated to multiple partitions C) Data is replicated to multiple brokers D) All data is deleted after one hour
Answer: A) Each partition will have one copy of data
10. How can Kafka achieve scalability?
A) By increasing the number of producers B) By adding more consumers in the consumer group C) By increasing the number of partitions D) By reducing the message size
Answer: C) By increasing the number of partitions
Frequently Asked Questions
What if ZooKeeper fails in Kafka?
The Kafka cluster won't be able to function correctly if ZooKeeper fails in Kafka. This is so because ZooKeeper is employed by Kafka to provide a variety of crucial functions like failure detection, leader election, partition assignment, and configuration management.
What is the limitation of Apache Kafka?
Kafka needs a strong, reliable network connection between its clients and brokers. As a result, if the network is unstable, Kafka cannot be used. Additionally, for embedded and safety-critical systems, Kafka is NOT deterministic.
What is the main method of message transfer in Kafka?
The two main methods of message transfer in Kafka are message queuing and the publisher-subscriber model. Messages from the server are read by a pool of consumers using the queuing mechanism and distributed to all users using the Publish-Subscribe approach.
What problems does Apache Kafka solve?
Apache Kafka is a distributed data storage designed with real-time streaming data processing in consideration. The main advantage of using Apache Kafka is that businesses can create unique software services by implementing a streaming data architecture.
Conclusion
In this article, we have discussed Apache Kafka interview questions with answers. Apache Kafka has emerged as a powerful and reliable distributed streaming platform used by many organizations for real-time data processing. In this blog, we have covered a wide range of Apache Kafka interview questions to help you prepare for your next interview.






























 9+ registered
9+ registered 

