Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Are you confused about what language you should consider learning for Big Data? In the world of ever-increasing data volumes and complex data analytics, Apache Spark has turned out to be one of the most popular open-source frameworks for processing large amounts of data in an organized manner.
In this article, we will learn about the powerful combination of Apache Spark with Scala. We will be discussing the implementation of data structures and RDD using Scala in Spark, followed by the advantages of Apache Spark with Scala.
Introduction to Scala in Apache Spark
Apache Spark is a powerful open-source system that is used to process large-scale datasets. It provides high-level APIs in many programming languages like Scala, Java, Python, and R Programming Language.
Scala, or scalable programming language, is widely used for developing Apache Spark applications. Its concise syntax and compatibility with Java make it an excellent choice for working with big datasets and machine-learning problems. Today Scala is used by many companies like LinkedIn, Twitter, Airbnb, Sony, Tumblr, Apple, etc.
Scala and Apache Spark are combined for complex data analysis and hence developing analytics applications. Scala offers features like concise syntax, performance advantages, compatibility with Java, strong community support, etc., making it a good choice for developing dynamic and high-performance spark applications.
To get started with Apache Spark, you should know the basics of Java and its syntax. While using Apache Spark with Scala, there are many basic terms that you should be familiar with.
Some of the key concepts of Apache Spark with Scala are:
Spark session: It is the entry point for interacting with Apache spark that is it serves as a way to create DataFrames, and RDDs and work on spark operations.
RDD: RDD or Resilient Distributed Datasets are an important data structure in SparkSpark. They are a distributed collection of objects that can be processed in parallel.
Transformations: These are tasks or operations that are applied to RDDs to create new RDDsTransformation does not run immediately. Examples are map, filter, join, sortBy, etc.
Actions: Action operations can perform calculations and return the result as count, collect, take, etc. Unlike transformations, actions are executed immediately.
DataFrames: DataFrames provide a high-level, tabular data structure abstraction in Apache Spark with Scala. They structure data into named columns which is similar to a relational database.
SparkSQL: SparkSQL provides a programming platform for querying organized and semi-organized data using SQL Syntax. With this interface, the user can work on SQL-like operations On Apache Spark with Scala.
Implementing Data Structures using Scala in Spark
Many Data structures can be implemented using Apache Spark with Scala. Some examples of this implementation are:
1. Lists: Lists are ordered collections of elements that can contain duplicates.
6. Sequences: Sequences are ordered collections of Data.
val sequenceSCALA = Seq(2, 4, 6, 8, 10)
The choice of Data structure depends on the use case and data type of data.
Implementing RDD in Apache Spark using Scala
RDD in Apache Spark stands for Resilient Distributed Dataset. This is a fundamental data structure in Apache Spark that can handle and process data in a distributed and fault-tolerant manner.
Resilient Distributed Dataset is a collection of objects that can be processed parallel across a cluster of machines. RDD is an immutable data structure; that is, it cannot be changed once created.
To implement RDD in Apache Spark with Scala, you can follow these steps:
1. First import the required Spark libraries.
import org.apache.spark.{SparkConf, SparkContext}
2. Create a SparkConf object to configure the Spark application.
val confRDD = new SparkConf().setAppName("RDDEx").setMaster("local[*]")
3. Next, you should create a SparkContext object using the SparkConf.
val sc = new SparkContext(confRDD)
The SparkContext is like an entry point for interacting with SparkSpark.
4. Next, create an RDD from a collection.
val dataVal = List(1, 2, 3, 4, 5)
val rddSCALA = sc.parallelize(dataVal)
5. Now, you can perform transformations and actions on RDD.
While transformations create a new RDD from an initial one like a map, filter, etc.
val transformRDD = rddSCALA.map(x => x * 5)
Action operations can perform calculations and return the result as count, collect, take, etc.
val countRDD = transformRDD.count()
6. Next, you can stop the SparkContext using the below command:
sc.stop()
Features of RDD
Some of the features of RDD are:-
1. Resilient: RDD is resilient, it can be recomputed in the event that one or more nodes fail.
2. Distributed: RDD is a distributed dataset that can be divided among a number of cluster nodes
3. Immutable: RDD cannot be changed once it has been created. If any alterations are necessary, transformation can be used to create a new RDD.
4. Lazy: Apache Spark RDD just depicts the data produced by computation. It doesn't start any computations on its own; instead, processing RDD data with transformations and actions can result in the creation of new RDDs.
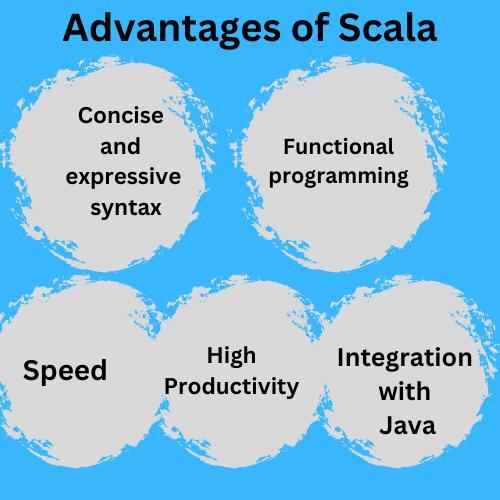
Advantages of Scala for Apache Spark
The advantages of using Apache Spark with Scala are:
Concise and expressive syntax: Scala's concise and clear syntax makes it easier to write short and readable code.
Functional programming: The functional programming feature of Scala, such as pattern matching, pure functions, immutability, etc., make it easier to work with spark operations.
High productivity: Working with Scala turns out to be more productive when compared to other programming languages like Java.
Speed: Scala has better optimization capabilities, resulting in faster responses than Python and R.
Integration with Java: Scala is highly compatible with Java; the user can easily use the Java libraries and code in your Spark application.
Frequently Asked Questions
What is RDD in Apache Spark with Scala?
RDD in Apache Spark stands for Resilient Distributed Dataset. The fundamental data structure in Apache Spark can handle and process data in a distributed and fault-tolerant manner. Resilient Distributed Dataset is a collection of objects that can be processed in parallel across a cluster.
What is Apache Spark used for?
Apache Spark is a powerful open-source system that is used to process large-scale complex datasets. It provides high-level APIs in many programming languages like Scala, Java, Python, and R.
What do you understand about transformations and actions in Apache Spark with Scala?
Transformations are tasks or operations that are applied to RDDs to create new RDDsTransformation does not run immediately. Examples are map, filter, join, sortBy, etc. On the other hand, Action operations can perform calculations and return the result as count, collect, take, etc. Unlike transformations, actions are executed immediately.
Conclusion
Kudos, Ninja, on making it to the finish line of this article! This blog has covered all the important fundamentals of Apache Spark with Scala.
We hope this blog has helped you understand Apache Spark with Scala better. Keep learning! We suggest you read some of our other articles on Data Analytics:
But suppose you are just a beginner and are looking for questions from tech giants like Amazon, Microsoft, Uber, etc. For placement preparations, you must look at the problems, interview experiences, and interview bundles.
































 8+ registered
8+ registered 

