Do you think IIT Guwahati certified course can help you in your career?
Introduction
Data structures like trees and graphs are traversed or explored by the Depth-First Search algorithm, or DFS Algorithm. Starting from the root node, the algorithm evaluates each scenario as far as it can go before returning.
The Depth-First Search technique keeps track of when a dead end happens during any iteration and when to pick up the next vertex to start a search using a stack data structure. This technique uses a deathward motion to analyze a network.
After reading the description of the DFS algorithm, consider an example to have a better grasp of the DFS methodology.
Depth-First Search Algorithm Example
A spanning tree is produced by the DFS traversal of a graph. A spanning tree is a type of graph that doesn't contain loops. The actions on the following list must be completed in order to complete DFS traversal.
Select a vertex to act as the traversal's beginning point. to include that vertex in the stack, requiring a trip there.
Newly added vertices surrounding a vertex should be placed at the top of the stack.
Till every vertex has interacted with the vertex at the top of the stack, repeat the procedures as mentioned above.
If there are no more vertices to visit, proceed and use backtracking to return and choose a vertice from the stack.
Continue to perform the above three steps until the stack is gone.
When the stack is empty, make the last spanning tree by removing any unnecessary edges from the graph.
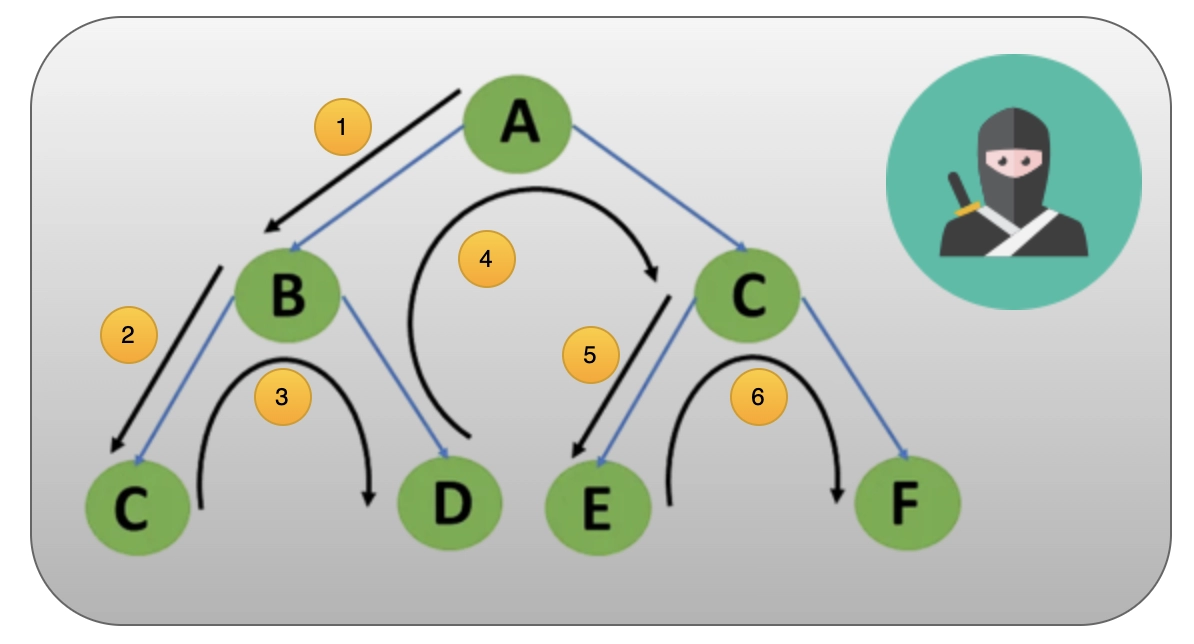
Take the graph below as an illustration of how to apply the DFS algorithm.
Example-of-DFS-algorithm.
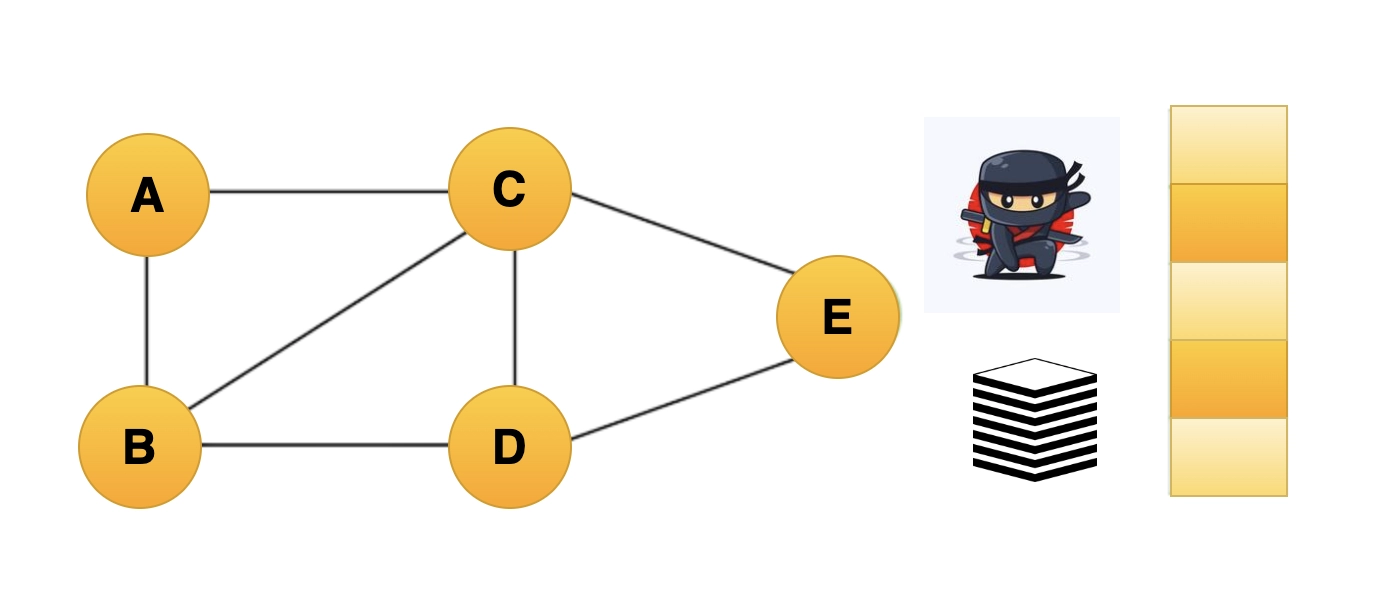
Step1: Vertex A must first be chosen as a source node and marked as a visited source node.
Vertex A should be moved to the top of the stack.
Example-of-DFS-algorithm1
Step 2: Visit any adjacent unvisited vertex of vertex A, such as B.
Put Vertex B at the very top of the stack.
Example-of-DFS-algorithm2
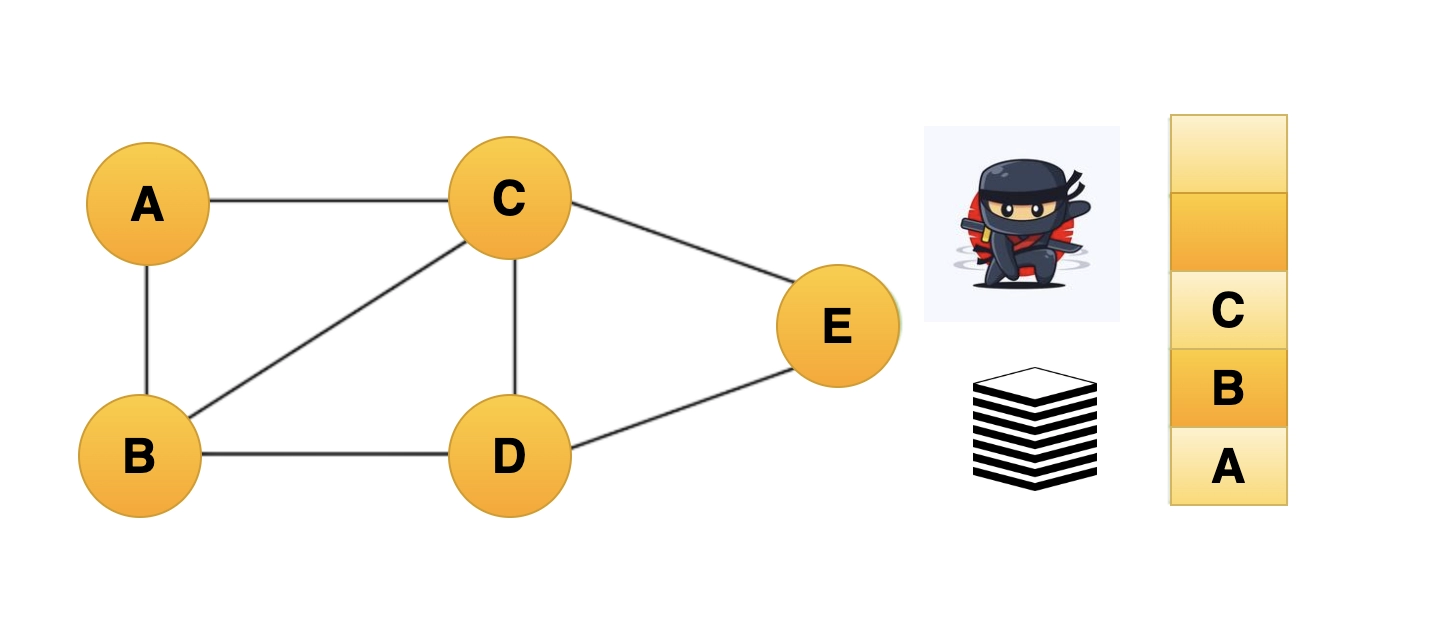
Step 3: From vertex C and D, go to any nearby vertex B that hasn't been visited yet. Vertex C might be chosen and decided to be a visited vertex.
The stack is moved up to include Vertex C.
Example-of-DFS-algorithm3
Step 4: Choose vertex D and mark it as a visited vertex after visiting any surrounding unvisited vertices of vertex C.
The stack is moved up to include Vertex D.
Example-of-DFS-algorithm4
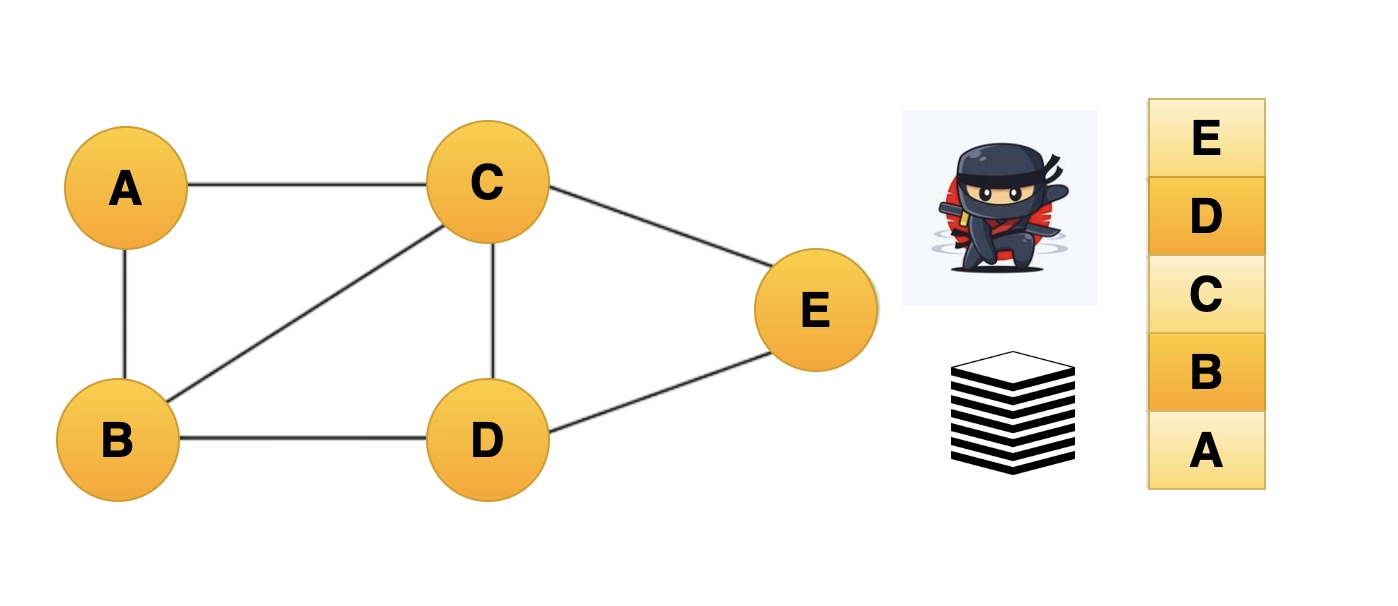
Step 5: Vertex E is the only unvisited neighbor of vertex D, designating it as visited.
The stack should be raised up to include Vertex E.
Example-of-DFS-algorithm5
Step 6: After visiting vertex E's neighboring vertices, vertex C and D, vertex E is removed from the stack.
Example-of-DFS-algorithm6
Step 7: Remove vertex D from the stack after visiting vertex B and vertex C, which is all of vertex D's close-by vertices.
Example-of-DFS-algorithm7
Step 8: In a similar vein, pop vertex C off the stack because its neighboring vertices have already been inspected.
Example-of-DFS-algorithm8
Step 9: Remove b from the stack because its next vertex is no longer unvisited.
Example-of-DFS-algorithm9
Step 10: Vertex A should also be removed from the stack because Vertex A's neighbors—Vertex B and Vertex C—have previously been visited.
Example-of-DFS-algorithm10
Implementation in C
C
C
#include <stdio.h> #include <stdlib.h>
//Creating require variables
int source_node,Point,Edge,time,checked[10],Output[10][10];
void DFS(int i)
{ //Point is Vertex int j; checked[i]=1; printf(" %d->",i+1); for(j=0;j<Point;j++)
{ if(Output[i][j]==1&&checked[j]==0) DFS(j); } }
int main()
{
int i,j,v1,v2; printf("\t\t\tDepth_First_Search\n"); printf("Enter the number of edges:"); scanf("%d",&Edge); printf("Enter the number of vertices:"); scanf("%d",&Point); for(i=0;i<Point;i++) { for(j=0;j<Point;j++)
Enter the number of edges: 4
Enter the number of vertices: 3
Enter the edges (V1 V2) : 1 2
Enter the edges (V1 V2) : 2 3
Enter the edges (V1 V2) : 3 4
Enter the edges (V1 V2) : 4 5
Enter the source: 1
Output
Enter the number of edges: 4
Enter the number of vertices: 3
Enter the edges (V1 V2) : 1 2
Enter the edges (V1 V2) : 2 3
Enter the edges (V1 V2) : 3 4
Enter the edges (V1 V2) : 4 5
0 1 0
0 0 1
0 0 0
Enter the source: 1
1 -> 2 -> 3 ->
Complexity
Time complexity
O(V+E): The temporal complexity of DFS is O(V+E), where V is the number of vertices when the whole graph is traversed and E is the number of edges.
Reason: Every vertex keeps track of all the edges close to it. You can find all its neighbors by exploring a node's adjacency list only once in linear time. So time complexity is O(V+E).
Space Complexity
O(V): The Space complexity of DFS is O(V), where V is the number of vertices when the whole graph is traversed.
Reason: In the worst case, the stack could expand until it is the size of the graph’s vertices because you are keeping track of the last visited vertex. The space complexity is, therefore, O(V).
Application of Depth-First Search Algorithm
The DFS traversal of the unweighted graph results in the formation of the minor spanning tree.
Finding a graph's cycle is as simple as determining whether a back edge is discernible during DFS. Therefore, you can use DFS to scan the graph for back edges.
Topological Sorting: Topological sorting is mainly used to plan tasks based on the dependencies between the jobs. Sorting occurs in computer science when instructions are scheduled, formula cell evaluation is ordered when recalculating formula values in spreadsheets, logic is synthesized, compilation jobs are ordered in makefiles, data is serialized, and symbol dependencies between linkers are resolved.
You can use either BFS or DFS to color a new vertex opposite its parents when you first find it to tell if a graph is bipartite. Additionally, make sure that no edge connects two colored vertices. The first vertex of a connected component can be either red or black.
Finding Components in a Strongly Connected Graph: Each vertex in a directed graph has a path to every other vertex if the graph is strongly linked.
figuring out mazes and other puzzles with just one answer:
DFS is used to locate all maze keys by only including nodes that are currently on the current path in the visited set.
Path Finding: A path between two specified vertices, a and b, can be found using the DFS technique.
In DFS, use s as the start vertex (G, s).
Use a stack S to keep track of the route from the start vertex to the present vertex.
As soon as destination vertex c is reached, return the path as the stack's contents.
You will examine the Depth-First Search algorithm's code implementation at the end of this course.
Memory Efficiency: Depth First Search (DFS) typically requires less memory compared to Breadth First Search (BFS) as it explores as far as possible along each branch before backtracking.
Simplicity: DFS is relatively simple to implement using recursion or a stack data structure, making it suitable for various applications and scenarios.
Flexibility: DFS can be easily adapted to solve a wide range of problems, including pathfinding, cycle detection, and topological sorting.
Space Efficiency: In certain scenarios, DFS can be more space-efficient than BFS, especially when searching in large, sparse graphs or trees.
Disadvantages of Depth First Search
Completeness: DFS may not guarantee finding the optimal solution or shortest path in all cases, especially if the search space is infinite or contains cycles.
Non-Optimality: DFS may not always yield the shortest path or optimal solution, particularly in scenarios where the goal is to find the shortest path between two nodes.
Time Complexity: In some cases, DFS may have higher time complexity compared to other search algorithms, especially if the search space is highly interconnected or contains cycles.
Stack Overflow: When using recursion to implement DFS, there is a risk of encountering stack overflow errors, especially in scenarios with deep or infinite search trees.
Frequently Asked Questions
What is the purpose of depth-first search?
An algorithm for navigating or searching through tree or graph data structures is called depth-first search (DFS). The algorithm begins at the root node (choosing an arbitrary node to serve as the root node in the case of a graph) and proceeds to investigate each branch as far as it can go before turning around.
Why is DFS more efficient than BFS?
DFS is more space-efficient than BFS, it could dig too far. DFS may be preferable to BFS if there is a large width (large branching factor) but a small depth (e.g., a small number of "moves"). While the BFS must keep track of every node on the same level, the DFS simply has to keep track of the nodes in a chain from top to bottom, using less memory. This is the reason DFS is more efficient than BFS.
Why does DFS require a stack?
When a search runs into a dead end during any iteration, the Depth-First Search (DFS) algorithm employs a stack to keep track of where to go next to continue the search.
Why is DFS not ideal?
DFS will identify a solution if one exists for a given finite search tree if the search tree is finite. Optimality: DFS is suboptimal, which means there are too many stages or costs involved in getting to the answer.
Does Depth-First Search identify the shortest route?
One of the primary graph algorithms is Depth-First Search. Depth-First Search locates the lexicographical first path from each source vertex to each vertex in the graph. Since there is only one simple path in a tree, Depth-First Search will also locate the shortest paths across the tree, but this is not the case for generic graphs.
Conclusion
In this article, you learned the Depth-First Search technique (also known as the DFS algorithm) using examples, discovered how to use it in code, and observed several DFS algorithm implementations.
The Coding Ninjas Software development career is for you if you're looking for a more in-depth study that goes beyond Data Structure and covers the most in-demand programming languages and skills today.
Do you have any queries about the Depth-First Search algorithm covered in this tutorial? If so, do post them in the part below this page that is designated for comments.
Please refer to our guided pathways on Code studio to learn more about DSA, Competitive Programming, JavaScript, System Design, etc. Enroll in our courses, and use the accessible sample exams and questions as a guide. For placement preparations, look at the interview experiences and interview package.
If you find any problems, please comment. We will love to answer your questions.








































 6+ registered
6+ registered 

