Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
In data mining and machine learning, the Apriori algorithm stands out as a fundamental tool for uncovering hidden patterns within large datasets. Originally developed for market basket analysis, the Apriori algorithm is widely used to identify frequent item sets and generate association rules, which reveal relationships between items in transactional data. By analyzing these associations, businesses can make informed decisions, such as optimizing product placement, improving inventory management, and enhancing customer experience.
The Apriori algorithm operates on the principle of finding frequent itemsets, which are groups of items that appear together frequently in transactions.
What is Apriori Algorithm?
The Apriori algorithm is a classic algorithm used in data mining for finding frequent itemsets and generating association rules. It is particularly useful for discovering relationships between variables in large transactional databases, such as market basket analysis, where the goal is to identify which products are frequently bought together by customers.
The Apriori algorithm operates on the principle that any subset of a frequent itemset must also be frequent. This is known as the "apriori property" or "downward closure property," which significantly reduces the search space for frequent itemsets.
Apriori Property
All subsets of the frequent itemset that aren't empty must be frequent. The anti-monotonicity of the support measure is a crucial concept in the Apriori algorithm. Apriori, all subgroups of a frequent itemset are assumed to be frequent (Apriori property).
If an item set is rare, all of its supersets are rare.
We'll locate common itemsets in the following dataset and develop association rules for them.
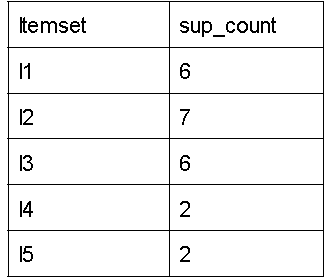
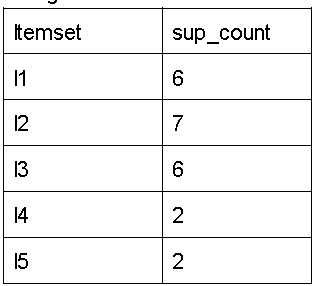
Step-1: K=1
(I) Create a table called C1 that contains the support count for each item in the dataset (candidate set)
II) compare the support count of the candidate set item to the minimal support count (here, min support=2). Remove items from the candidate list if their support count is less than min support). This gets us the L1 itemset.
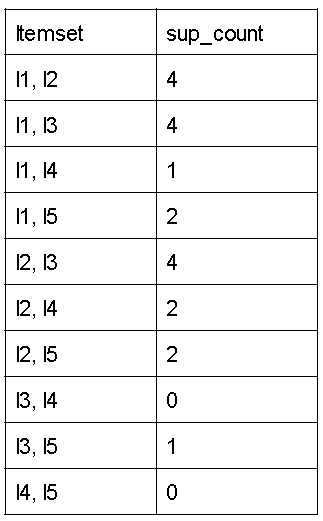
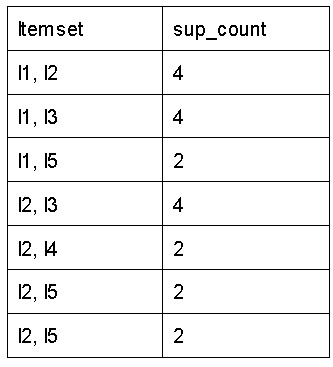
Step-2: K=2
Create a candidate set C2 with L1 as a starting point (the join step). The condition for combining Lk-1 and Lk-1 is that they must share (K-2) components.
Check whether all subsets of an itemset are common and if they aren't, eliminate the itemset.
(I1 and I2 are prominent examples of subsets of I1 and I2.)
Check for each itemset) Now, using the dataset, find the support count for these itemsets.
(II) Compare the number of supporters for a candidate (C2) with the minimal number of supporters (min support=2). If the support count of a candidate set item is less than min support, those items are removed, giving us itemset L2.
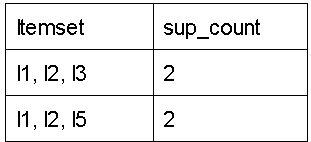
Step-3:
Create a C3 candidate set using L2 (join step). The condition for combining Lk-1 and Lk-1 is that they must share (K-2) components. As a result, the initial element for L2 should be the same.
As a result of connecting L2, the itemset formed is I1, I2, I3I1, I2, I5I1, I3, i5I2, I3, I4I2, I4, I5I2, I3, I5I2.
Check whether all subgroups of these itemsets are frequent and if they aren't, eliminate them.
(A frequent subset of I1, I2, I3 is I1, I2; I2, I3; I1, I3; I1, I3; I1, I3; I1, I3; I1, I3; I1, I3; I1, I3; I1, I3; I1, I3; I1, I3; I1, I3; I1, I3; I1, I3; I Subset I3, I4 is not frequently used in I2, I3, I4, hence it should be removed. Check each item set in the same way, and then use the dataset to find the support count for the remaining itemsets.
(II) Compare the number of supporters for the candidate (C3) with the minimal number of supporters (min support=2). If the support count of a candidate set item is less than min support, those items are removed, giving us itemset L3.
Step 4
Using L3, create candidate set C4 (join step). The requirement for combining Lk-1 and Lk-1 (K=4) is that they share (K-2) components. So, for L3, the first two elements (items) should be identical.
Check whether or not all subsets of these itemsets are frequent (the itemset generated by joining L3 is I1, I2, I3, I5; hence its subset contains I1, I3, I5, which is not often). As a result, there are no itemsets in C4.
We come to a halt here because there are no more frequent itemsets to be located.
As a result, we've uncovered all of the common item sets. Now comes the generation of a strong association rule. To do so, we must assess the confidence of each rule.
Confidence
A 60 percent confidence level indicates that 60% of customers who bought milk and bread also bought butter.
So, if the minimum level of confidence is 50%, the first three criteria can be classified as strong association rules.
Components of the Apriori Algorithm
Frequent Itemsets: Sets of items that appear frequently together in transactions. The algorithm starts with individual items and iteratively combines them to form larger itemsets, retaining only those that meet a minimum support threshold.
Support: The proportion of transactions in the dataset that contain a particular itemset. It helps in identifying how frequently an itemset appears in the database.
Confidence: A measure used in association rules to indicate the reliability of the rule. It is calculated as the ratio of the support of the combined itemset to the support of the antecedent.
Candidate Generation: The process of creating new itemsets from the frequent itemsets of the previous iteration. This step involves joining itemsets and pruning those that do not meet the minimum support.
Pruning: Removing candidate itemsets that do not meet the minimum support threshold. This step helps in reducing the number of itemsets to be considered in subsequent iterations.
How to Improve the Efficiency of the Apriori Algorithm?
Reduce the Number of Scans: Instead of scanning the entire database multiple times, use more efficient data structures such as hash trees to count the support of itemsets.
Transaction Reduction: Remove transactions that do not contain any of the frequent itemsets. This reduces the number of transactions to be considered in future iterations.
Partitioning: Divide the database into smaller partitions and find frequent itemsets in each partition. Combine the results to get the global frequent itemsets.
Hash-Based Techniques: Use hash-based itemset counting to reduce the size of candidate k-itemsets.
Sampling: Use a representative sample of the database to find frequent itemsets. Verify the results with the entire database to ensure accuracy.
Dynamic Itemset Counting: Adjust the support threshold dynamically during the algorithm’s execution based on the frequency of itemsets.
Advantages of the Apriori Algorithm
Simplicity: The Apriori algorithm is easy to understand and implement. It follows a straightforward iterative approach to finding frequent itemsets.
Wide Applicability: It can be applied to various domains such as market basket analysis, bioinformatics, and web usage mining.
Scalability: The algorithm can handle large datasets, especially with optimization techniques like transaction reduction and partitioning.
Understandable Results: The association rules generated by Apriori are easy to interpret and can provide valuable insights.
Disadvantages of the Apriori Algorithm
High Computational Cost: The algorithm requires multiple passes over the database, leading to high computational cost and time complexity, especially with large datasets.
Memory Intensive: Generating and storing candidate itemsets can consume significant memory, especially as the size of the itemsets increases.
Difficulty with Low Support Thresholds: When the minimum support threshold is low, the number of candidate itemsets can grow exponentially, making the algorithm inefficient.
Assumes Uniform Distribution: The Apriori algorithm assumes a uniform distribution of items, which may not always be the case in real-world datasets, leading to less accurate results.
Limitations of Apriori Algorithm
The Apriori Algorithm is sluggish. The biggest drawback is the amount of time it takes to hold many candidate sets with frequent itemsets, low minimum support, or huge itemsets, making it inefficient for large datasets. For example, if there are 104 common 1-itemsets, it must generate more than 107 2-length candidates, who will then be tested and accumulated. Furthermore, to recognize a regular pattern of size 100, i.e., v1, v2,... v100, it must generate 2100 candidate itemsets, which is costly and time-consuming. As a result, it will check for several sets from candidate itemsets, as well as scan the database multiple times to locate candidate itemsets. When memory capacity is restricted and there are many transactions, Apriori will be very low and inefficient.
Frequently Asked Questions
What is the Apriori formula?
The Apriori formula refers to the method of finding frequent itemsets by iteratively applying support thresholds to candidate itemsets in a dataset.
What is support and confidence in the Apriori algorithm?
Support measures the frequency of an itemset in the dataset, while confidence indicates the reliability of an association rule based on its occurrence.
What is the apriori algorithm for example?
The apriori algorithm is a method of extracting frequent product sets and relevant association rules. In most cases, the apriori technique is used on a database with many transactions. Customers, for example, can purchase products at a Big Bazar.
What is the apriori algorithm used for?
The Apriori technique extracts common itemsets from a transactional database and creates association rules. The terms "confidence" and "support" are employed. The frequency of occurrence of items is referred to as support, while confidence is a conditional probability. An item set is made up of the items in a transaction.
What is an apriori algorithm in machine learning?
Apriori is a mining algorithm for association rules. The datasets look for a succession of often occurring sets of elements. It is based on the itemsets' relationships and correlations. It's the algorithm behind the "You Might Also Like" feature that you've probably seen on a recommendation platform.
What is Apriori analysis?
Apriori analysis is when an investigation is done before running on a specific system. This part of the study is when a function is defined using a theoretical model.
Is Apriori supervised or unsupervised?
Apriori is typically regarded as an unsupervised learning strategy because it's frequently used to find or mine for intriguing patterns and associations. Apriori may also be tweaked to classify data that has been labeled.
Conclusion
So that's the end of the article.
After reading about the Apriori Algorithm, are you not feeling excited to read/explore more articles on the topic of data mining? Don't worry; Coding Ninjas has you covered.






























 9+ registered
9+ registered 

