Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Welcome to our blog on architecture of HBase. HBase, a distributed, scalable, and NoSQL database built on top of the Hadoop Distributed File System (HDFS), stands as a cornerstone in the realm of big data storage and processing. With its column-oriented structure, automatic sharding, and strong consistency guarantees, HBase offers a robust foundation for storing and managing vast amounts of structured data in real-time.
What is HBase?
Before learning the architecture of HBase, let us know about HBase.HBase is a data model and is similar to Google's big table. It is an open-source, distributed database developed by Apache software foundation written in Java.
The table in HBase is split into regions and served by the region servers in HBase. Regions are vertically divided by column familied into "stores." Stores are usually saved as files in HDFS. HBase runs on top of HDFS (Hadoop Distributed File System).
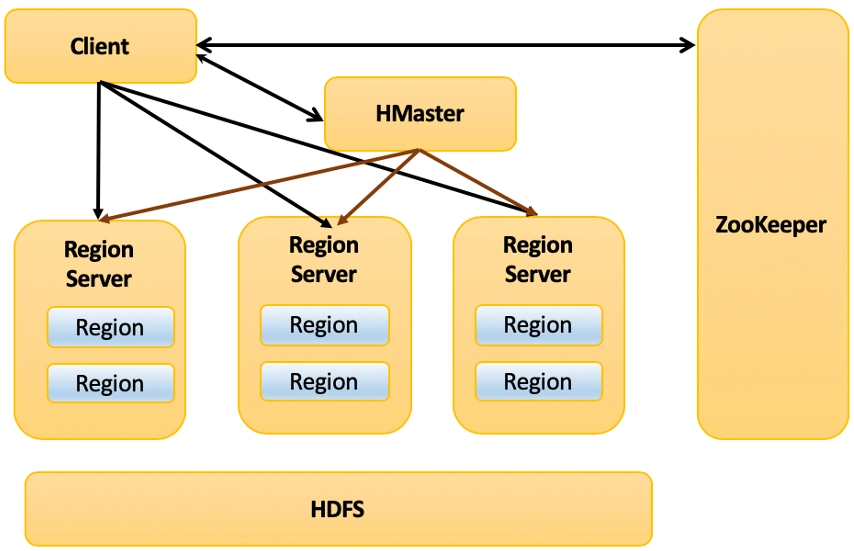
The following figure represents the architecture of HBase:
Architecture of HBase ~ source: dataunbox.com
Now we will study the architecture of HBase and its components.
Components of Hbase Architecture
There are three major components of Hbase that are:
Region Server
HMaster
Zookeeper
Let's understand these components in detail.
Region Server
Regions are the tables split up and spread across the region servers. The basic building blocks of the HBase cluster are regions that consist of the distribution of tables and are comprised of Column families. The size of a region is 256 MB by default.
The region servers have :
Regions that communicate with the client and handle data-related operations.
Regions that decide the region's size by following the region size thresholds.
Regions that can handle read and write requests for all the sub-regions under it.
When the client reads and writes requests received by the HBase Region Server, it assigns the request to a region specifically, where the actual column family resides. The client can contact HRegion servers directly, and there is no need for mandatory permission of the HMaster to the client regarding communication with HRegion servers. Whenever the operations related to metadata and schema changes are required, the client requires HMaster help.
HMaster
HMaster acts as a monitoring agent that monitor all Region Server instances present in the cluster, and it acts as an interface for all the metadata changes.
HMaster performs the following major roles in HBase:
HMaster provides admin performance and helps to distribute services to different region servers.
It also plays a vital role in the performance and maintenance of nodes in the cluster.
HMaster assigns regions to region servers.
When a client needs to change any schema and any Metadata operations, HMaster takes responsibility for these operations.
Note:
The client communicates with both HMaster and ZooKeeper in a bi-directional way. It directly contacts with HRegion servers for read and writes operations. HMaster assigns regions to various region servers and, in turn, checks the health status of region servers.
Zookeeper
HBase Zookeeper is a centralized monitoring server that maintains configuration information and provides distributed synchronization. It acts as a coordinator in HBase.Clients communicate with region servers via zookeeper. Distributed synchronization helps access the distributed applications running across the cluster to provide coordination services between nodes.
Zookeeper has ephemeral nodes representing different region servers. Zookeeper is an open-source project and provides many important services, some of which are:
It maintains configuration information.
It also provides distributed synchronization.
Provides ephemeral nodes which represent different region servers.
It is used to track server failure and network partitions.
It masters servers usability of ephemeral nodes for discovering available servers in the cluster.
Features of HBase
Scalability: HBase scales horizontally, enabling storage and processing of massive data volumes across distributed clusters.
High Availability: It ensures data availability by replicating data across nodes, reducing the risk of downtime or data loss.
Consistency: HBase provides strong consistency, ensuring data integrity across distributed nodes.
Column-Oriented Storage: Data is stored in columns, optimizing for analytical queries and data retrieval.
Automatic Sharding: HBase automatically shards data based on row keys, facilitating efficient data distribution and parallel processing.
Advantages of HBase
Scalability: Easily scales to handle petabytes of data by adding more nodes.
Fault Tolerance: Distributed architecture ensures fault tolerance, minimizing data loss.
Real-Time Data Processing: Supports real-time data ingestion and processing.
Flexible Schema: Allows flexible schema design, accommodating varying data structures.
Integration with Hadoop Ecosystem: Seamlessly integrates with other Hadoop components for big data analytics.
Disadvantages of HBase
Complexity: Setting up and managing clusters can be complex.
High Overhead: Replication and consistency mechanisms may impact performance.
Limited SQL Support: Lacks native SQL support, requiring specific APIs or integration with SQL-on-Hadoop solutions.
Data Locality: Ensuring optimal data locality can be challenging.
Storage Overhead: Column-oriented storage may lead to storage overhead for certain data types.
What is HDFS?
HDFS (Hadoop distributed File System) provides a distributed environment for storage. It is a file system designed to run on commodity hardware.
HDFS provides high latency operations.
HDFS supports Write once Read Many times.
HDFS gets in contact with the HBase components and stores a large amount of data in a distributed manner.
MapReduce or Hadoop Distributed File System (HDFS)
Data Integrity
Strong consistency
Eventual consistency
Schema Flexibility
Flexible schema design
Schema-on-read
Use Case
Real-time data processing, NoSQL database
Distributed file storage, batch processing
Frequently Asked Questions
What is HBase Data Model?
HBase Data Model is a set of components that consists of Tables, Rows, Column families, Cells, Columns, and Versions. It consists of : Set of various tables Each table have column families and rows Each table must have an element that is defined as a Primary Key. In HBase, the row key acts as a Primary key. Each column present in HBase denotes an attribute corresponding to an object.
What are the advantages of HBase?
Advantages of HBase are: It can store large data sets. The database can be shared easily. High availability through failover and replication. It is cost-effective, from gigabytes to petabytes.
What are the disadvantages of Hbase?
Disadvantages of HBase are: HBase does not support SQL structure. There is no transaction support. Memory issues on the cluster.
What is a file system?
The file system is an essential aspect of an operating system. It provides the mechanism for online storage of and approach to both data and programs of the OS (operating system) and all the users of the computer system. It consists of two distinct parts: a collection of files, storing related data, and a directory structure, which arranges and provides information about all the files in the system.
What is the HBase architecture of HDFS?
HBase architecture is built on top of Hadoop Distributed File System (HDFS), utilizing its distributed storage capabilities. HDFS provides the underlying file storage infrastructure for storing HBase data across distributed nodes.
What are the three major components of HBase?
The three major components of HBase are:
HMaster: Responsible for managing HBase cluster, metadata operations, and region assignment.
RegionServer: Manages one or more regions (tables) and handles read/write requests from clients.
ZooKeeper: Coordinates and manages distributed operations, such as leader election and synchronization, among HMaster and RegionServers.
Conclusion
In this blog, we learned about HBase and the architecture of HBase. We saw the architectural diagram of HBase and the components of HBase: Region server, HMaster, and zookeeper. Then we study these components in detail with their uses. Later on, we also learned about HDFS(Hadoop distributed File System).
Check out this link for the top 100 SQL problems asked in various product and service-based companies like Google, Microsoft, Infosys, IBM, etc.
You can visit Coding Ninjas Studio to practice programming problems for your complete interview preparation. Check it out to get hands-on experience with frequently asked interview questions and land your dream job.






























 6+ registered
6+ registered 

