Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
A Data Warehouse is a central repository that allows organizations to store, manage, and analyze large volumes of data from various sources. Its architecture plays a crucial role in enabling efficient data retrieval, transformation, and reporting, supporting decision-making processes within an organization. A well-designed data warehouse architecture ensures that data is organized in a way that is optimized for querying and analysis, rather than for transactional processing.
What Is Data Warehouse Architecture?
Data Warehouse Architecture is complex as it's an information system that contains historical and commutative data from multiple sources. It defines the overall architecture of data communication processing and presentation that exist for end-clients computing within the enterprise. Data warehouses and their architectures vary depending on an organization's situation elements.
The following are three common architectures:
Data Warehouse Architecture (Basic).
Data Warehouse Architecture (with Staging Area).
Data Warehouse Architecture (with Staging Area and Data Marts).
Characteristics of Data Warehouse Architecture
1. Scalability
Data warehouse architecture is designed to scale as data grows. It can handle increasing amounts of data and users without losing performance. This means businesses can add storage, processing power, or users without rebuilding the system. Scalability helps organizations keep up with their expanding data needs.
2. Extensibility
A good data warehouse architecture supports easy extension. You can add new data sources, business rules, or tools without making major changes to the core structure. This feature allows businesses to adjust to new technologies and needs quickly. Extensibility makes the system future-proof and flexible.
3. Security in Data Warehouse
Security is a key part of any data warehouse architecture. It includes user access control, data encryption, and activity logging. These features help protect sensitive business data from unauthorized access or data breaches. A secure system builds trust and supports data privacy standards.
4. Administerability
A data warehouse should be easy to manage and monitor. Administerability includes tools for scheduling tasks, tracking performance, and maintaining data quality. This helps IT teams manage the system without much manual work. Good administration ensures the warehouse runs smoothly and efficiently.
5. Analytical vs Transactional Processing
Data warehouse architecture is optimized for analytical processing, not transactional tasks. It helps users analyze large volumes of data to discover trends and make decisions. Unlike transactional systems that process daily operations, data warehouses support reporting, forecasting, and business intelligence tasks. This separation improves speed and performance.
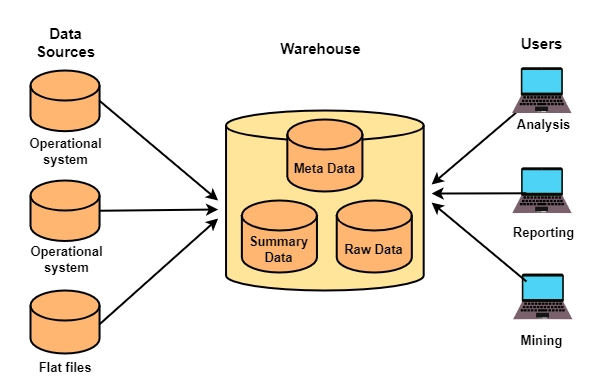
Basic Data Warehouse Architecture
Operational System: In data warehousing, an operational system is a system that processes an organization's day-to-day transactions.
Flat File System: A flat file system is a collection of files in which each file must have a unique name.
Metadata: The metadata contains information about other data but not the data itself, such as a message's text or an image's content. We use metadata to direct a query to the most relevant data source.
Raw data: Raw data is a set of data that has not yet been processed and delivered from a specific data entity to the data supplier and has not been processed by machine or human. This information is gathered from various online sources to provide detailed insight into users' online behavior.
Summary Data: Data summary is a simple term for a brief conclusion to a large theory or paragraph. This is frequently the case in which analysts write the code and then declare the ultimate end by summarizing data. In data mining and processing, a data summary is critical.
Components of Data Warehouse Architecture
A data warehouse architecture consists of several key components that work together to store, manage, and analyze large volumes of data. The main components are:
Data Sources – Various structured and unstructured data sources like databases, APIs, and flat files.
ETL (Extract, Transform, Load) Process – Extracts data from sources, transforms it into a usable format, and loads it into the data warehouse.
Data Staging Area – A temporary storage space where raw data is cleaned and transformed before loading.
Data Warehouse Storage – The central repository where processed data is stored, often structured in schemas like star or snowflake.
Metadata Repository – Stores information about data definitions, structures, and relationships to support data management.
Data Marts – Subsets of the data warehouse designed for specific business functions or departments.
OLAP (Online Analytical Processing) Engine – Enables complex queries, aggregations, and multi-dimensional data analysis.
BI (Business Intelligence) and Reporting Tools – Used for data visualization, dashboards, and generating reports to support decision-making.
Data Governance and Security – Ensures data quality, access control, compliance, and protection against unauthorized access.
Properties of Data Warehouse Architecture
1. Subject-Oriented
Data in a data warehouse is organized around key subjects, such as customers, products, or sales, rather than by individual applications or transactions. This organization makes it easier to answer business-focused questions and perform analysis.
2. Integrated
A data warehouse integrates data from multiple sources, ensuring that it is consistent and unified. It resolves any discrepancies in naming conventions, encoding formats, and other data attributes, so that the information is reliable and standardized across the system.
3. Non-Volatile
Once data is loaded into the data warehouse, it is not modified. This ensures the consistency of historical data, allowing for accurate analysis and reporting over time without interference from transactional updates.
4. Time-Variant
Data warehouses store historical data, enabling trend analysis and long-term insights. Changes to data over time are tracked, allowing businesses to examine how metrics evolve, which supports decision-making based on time-related patterns.
5. Three-Tier Architecture
A typical Data Warehouse follows a three-tier architecture, comprising:
Data Source Layer This layer collects data from various internal and external sources. These sources include operational databases, flat files, spreadsheets, and other systems. It is the first step where raw data enters the data warehouse.
Data Storage Layer This is the heart of the data warehouse. It stores data that has been processed through the ETL (Extract, Transform, Load) process. In this layer, the data is cleaned, transformed, and organized so it’s ready for analysis.
Presentation Layer This layer provides access to the processed data for end-users. It includes tools for reporting, data visualization, and querying. Users can explore the data, generate insights, and make informed decisions.
Types of Data Warehouse Architectures
Data Warehouse architectures are mainly of three types:
Single-Tier Architecture
Two-Tier Architecture
Three-Tier Architecture
Single-Tier Architecture
The data storage and data access components are stored on the same server in this architecture, which has a single tier defined for the data warehouse server. It works well for standalone or small-scale data warehouse deployments with limited user access requirements and data volumes.
Two-Tier Architecture
The client tier and the server tier are the two layers that make up this design. While the server tier contains the data warehouse and controls data processing and storage, the client tier offers user interfaces and tools for data querying and analysis. It offers superior performance, scalability, and concern separation over single-tier architecture.
Three-Tier Architecture
The client tier, middle tier, and server tier are the three tiers into which the three-tier architecture splits the data warehouse environment. Applications and user interfaces are part of the client tier; middleware, or application servers, handle business logic and data processing; and the data warehouse is housed on the server tier. Because the appearance, application, and data layers are kept apart, it provides better scalability, flexibility, and maintainability.
Top-Down Approach
The Top-Down Approach in data warehouse architecture involves designing the data warehouse from a high-level perspective down to the details. It typically follows these steps:
Working of Top-Down Approach
Requirement Gathering: Identify and gather business requirements and goals.
Data Modeling: Design the overall structure of the data warehouse using conceptual and logical models.
Integration: Integrate data from various sources into the centralized data warehouse.
Implementation: Develop and deploy the data warehouse infrastructure.
Data Mart Creation: Optionally, create data marts for specific departments or functions.
Advantages of Top-Down Approach
Comprehensive View: Ensures that the data warehouse meets the overall organizational goals.
Consistency: Centralized design promotes consistency in data handling and reporting.
Scalability: Easier to scale and adapt to changing business needs.
Control: Provides better control over data quality and integrity.
Disadvantages of the Top-Down Approach
High Initial Cost The top-down approach requires a large investment at the beginning. Designing and building a central data warehouse from scratch needs significant time, tools, and skilled professionals, which may not be ideal for small organizations.
Longer Implementation Time This method takes a lot of time before any usable results are seen. Businesses may need to wait months or even years to start generating reports or gaining insights, which can delay decision-making.
Rigid Design Structure The design in a top-down model is fixed early in the process. If business needs change, it becomes difficult to adapt the system without major changes, leading to extra work and cost.
Complex Maintenance Since the central warehouse manages all data, maintaining it can be difficult. Any small change may affect the entire system, making updates and testing more complex.
Difficult to Scale Quickly Adding new subject areas or data sources is not always easy in this model. Scaling the system might involve heavy redesign and rework, slowing down business flexibility.
Delayed ROI (Return on Investment) Because of the long development cycle and upfront costs, businesses may not see immediate benefits. This delay can be a concern for companies needing fast insights and results.
Dependency on Centralized Team A top-down approach often requires centralized IT or data teams. This can slow down response time to specific department needs and limit agility in data handling.
Not Suitable for Agile Environments This approach doesn’t align well with agile or fast-changing development environments. It may hinder innovation or quick adaptation to new data requirements.
Bottom-Up Approach
Contrasting the Top-Down Approach, the Bottom-Up Approach focuses on building the data warehouse incrementally from detailed data sources to a comprehensive structure.
Working of Bottom-Up Approach
Data Source Identification: Identify and prioritize specific data sources.
Data Integration: Integrate data directly into data marts or operational data stores (ODS).
Schema Design: Develop schemas based on data requirements and usage patterns.
Aggregation: Aggregate data as needed for reporting and analysis.
Advantages of Bottom-Up Approach
Quick Implementation: Faster initial implementation due to incremental building blocks.
Flexibility: Allows for flexibility in accommodating diverse data sources and changing requirements.
User Focus: Aligns closely with end-user needs and specific departmental requirements.
Cost-Effective: Can be more cost-effective initially by focusing resources on immediate needs.
Disadvantages of the Bottom-Up Approach
Lack of Enterprise-Wide View This approach starts by building small data marts for individual departments. It often misses the bigger picture, leading to difficulties when trying to combine these isolated systems into a unified enterprise-level data warehouse.
Data Inconsistency Issues Since each data mart may use different formats or standards, inconsistencies can arise when integrating data across the organization. This impacts the accuracy and reliability of overall reports.
Integration Challenges Combining multiple data marts into a centralized warehouse can be complex. Different architectures, structures, and definitions make integration time-consuming and error-prone.
Limited Initial Scope Bottom-up models focus on immediate departmental needs, which may ignore future business requirements. As new needs arise, it becomes harder to adapt the system without redesign.
Duplicate Efforts Teams may duplicate similar data transformation or loading processes across multiple data marts. This leads to inefficient use of resources and possible conflicts in logic.
Scattered Data Governance Data quality and management can vary between departments. Without centralized governance, enforcing consistent security, privacy, and data standards becomes difficult.
Cost Overruns During Expansion While initial setup costs may be low, scaling up from departmental marts to a comprehensive warehouse often results in unexpected expenses, especially during integration.
Compromised Reporting Accuracy When reports rely on data from different, unaligned data marts, accuracy and consistency can suffer. This makes it hard to make reliable business decisions based on the output.
Advantages of Data Warehouse Architecture
1. Improved Decision-Making: By centralizing and harmonizing data from various sources, data warehouses provide a solid foundation for analytics and reporting. This enables historical analysis and trend forecasting, allowing businesses to make well-informed, data-driven decisions.
2. Data Quality and Consistency: Data warehouses ensure consistency across the organization by implementing data cleansing and quality checks. They also provide a single version of the truth, ensuring that all users access reliable and standardized data for accurate reporting and analysis.
3. Enhanced Business Intelligence: With support for a wide range of Business Intelligence (BI) activities, data warehouses facilitate advanced analytics, data mining, and machine learning. They empower users with self-service analytics and reporting capabilities, making it easier for non-technical users to interact with the data.
4. Performance and Scalability: Data warehouses optimize the performance of data retrieval and analysis, ensuring fast query responses even with large datasets. The scalable architecture of data warehouses grows to meet evolving data and analytics needs, supporting both ad-hoc queries and scheduled reporting efficiently.
5. Time and Cost Efficiency: By streamlining the ETL (Extract, Transform, Load) processes, data warehouses reduce the time and effort required for data preparation and analysis. This leads to lower operational costs and a lower total cost of ownership over time by maintaining a centralized, accessible data repository.
6. Improved Data Security and Governance: Data warehouses often come with robust data security protocols and governance frameworks. This ensures that data is protected from unauthorized access and compliance with regulatory requirements is maintained, reducing the risk of data breaches and ensuring data privacy.
7. Data Integration from Multiple Sources: Data warehouses allow integration of data from disparate systems, including internal databases, external sources, and cloud services. This creates a comprehensive view of the data, helping organizations overcome data silos and enabling more holistic insights for decision-making.
8. Support for Complex Queries: Data warehouses are optimized for complex queries and reporting, supporting sophisticated data analysis over large datasets. They provide users with the ability to run complex aggregations and multi-dimensional queries, which may be slow or inefficient in transactional databases.
9. Historical Data Storage: Since data warehouses store historical data, they allow businesses to track changes over time, conduct trend analysis, and perform forecasting. This is crucial for long-term business planning, budgeting, and strategic decision-making.
Disadvantages of Data Warehouse Architecture
1. High Initial Costs: Data warehouses require significant investment in hardware, software, and specialized expertise. The upfront costs for setting up and configuring the necessary infrastructure can be substantial, making it a costly venture for organizations, especially smaller ones.
2. Complex Implementation: Setting up a data warehouse requires thorough planning, design, and expertise. The integration with existing systems and processes, as well as the customization to meet specific business requirements, can be a complex and time-consuming task.
3. Data Latency: Data in a data warehouse is typically not available in real time, as the ETL (Extract, Transform, Load) processes involve batch processing. This introduces a delay in data availability, making it less suitable for applications that require real-time data.
4. Potential Overhead: Maintaining a data warehouse requires additional systems, processes, and resources. This can increase operational overhead, necessitating dedicated teams for management, monitoring, and troubleshooting, which can be resource-intensive.
5. Limited Historical Data: Depending on the storage capacity and design, a data warehouse may have limitations on how much historical data it can store. Older data may be pruned or archived, which can limit long-term trend analysis and forecasting.
6. Data Silos and Incomplete Integration: While data warehouses aim to integrate data from multiple sources, there may still be challenges in fully integrating all systems. Data silos from certain departments or legacy systems can hinder the completeness of the data and limit the warehouse’s ability to provide comprehensive insights.
7. Performance Issues with Large Volumes of Data: As the volume of data grows over time, the data warehouse may experience performance issues, especially if not properly optimized. Query performance can slow down when dealing with large datasets, requiring additional tuning or investments in more powerful hardware.
8. Limited Flexibility for Changing Requirements: Once a data warehouse architecture is set up, making significant changes or adding new data sources can be difficult. The architecture may not be flexible enough to easily accommodate evolving business needs or the integration of new data types or systems.
9. Difficulty in Handling Unstructured Data: Most data warehouses are optimized for structured data, meaning they may struggle to handle unstructured data (such as text, images, or social media content). This can limit the ability to leverage diverse data sources for analytics.
Frequently Asked Questions
What are the 3 models of data warehouse?
The three data warehouse models are as follows: Enterprise Data Warehouse (EDW): All organizational data is centrally stored. Data Mart: An EDW subset specialized to specific divisions or operational tasks. Operational Data Store (ODS): An operational data integration and reporting database that is updated in real-time or almost real-time.
What is process architecture in data warehouse?
The design and organization of data processing processes and activities inside the data warehouse environment is known as process architecture in the context of data warehousing. To ensure effective data integration and delivery, it includes data extraction, transformation, loading (ETL), scheduling, monitoring, and management.
What is data warehouse architecture in data mining?
In data mining, data warehouse architecture refers to how data warehouses are set up and arranged to make data mining procedures more efficient. To extract useful insights from massive datasets, it consists of parts including data sources, ETL procedures, data storage, data mining algorithms, and display layers.
What are the classification of data warehouse architecture?
Data warehouse architecture is classified into three main types:
Single-Tier Architecture: A minimal design where data is stored in one layer.
Two-Tier Architecture: Separates data storage and user access layers.
Three-Tier Architecture: Includes data source, storage, and presentation layers for scalable and efficient data management.
Conclusion
Data warehouse architecture plays a crucial role in structuring data to support efficient analysis, reporting, and decision-making. By organizing data across multiple layers and ensuring integration, consistency, and scalability, it provides organizations with a powerful tool for business intelligence.





























 9+ registered
9+ registered 

