Do you think IIT Guwahati certified course can help you in your career?
Introduction
The awk command in Unix is a text processing tool used for manipulating and analyzing text files. It is particularly useful for processing structured data, such as columns and rows in CSV files or log files. awk takes each line of input, splits it into fields based on a specified delimiter, and allows you to perform various operations on the data
In this blog, we will explore the potential of the awk command in unix. We will cover the basics, its syntax, and some examples for clarity. By the end of this blog, you'll have a solid understanding of the awk command.
What is the Awk command in Unix?
Awk command in Unix is a scripting language for text processing and pattern search. It requires no compiling and lets users use variables, numeric and string functions, and logical operators. We can generate reports by manipulating and analyzing some files. Awk is an abbreviation for Aho, Weinberger, and Kernighan. These are the names of its creators.
Awk command in Unix is a utility that enables a programmer to write small and effective programs that define text patterns to be searched for in a document and also describes the action to be taken when a match is found. It explores one or more files to see if they contain lines matching the specified patterns and then performs the associated actions.
Note: You can use this command in UNIX or UNIX-like OS such as Linux.
Features of AWK command
The awk command in Unix has several useful features for text processing:
Pattern Matching: You can specify conditions or patterns to match lines in your data.
Field Separation: It can automatically split each line into fields based on a delimiter (e.g., space, tab).
Variables: You can define and manipulate variables to store and compute data.
Built-in Functions: awk offers many built-in functions for common tasks (e.g., math, string manipulation).
Formatting Output: It helps format and display data neatly.
Looping: You can use loops to iterate through lines or perform repetitive tasks.
Input and Output from Files: It reads data from files or standard input (e.g., pipes), and it can also append output to files.
Control Structures: It supports if-else and loops for more complex logic.
Awk Command Syntax
Awk commands in Unix consist of patterns and actions. An awk scans input files line by line, comparing each line against the specified patterns. The corresponding pre-defined action(s) are executed when a pattern matches. The following is a simple awk program to demonstrate its syntax:
In the above command, 'matching_pattern' represents the condition/pattern to match, and 'action' depicts the actions to be performed when the specific pattern is found.
Awk Command Examples
As in the former section, we discussed the syntax for an awk command in Unix. Let's now see some examples based on it. First, we will create a .txt file containing basic information to test different awk commands. The following commands are to create a new .txt file using the Ubuntu terminal.
$cat > Student_Data.txt
This creates a text file named 'Student_Data'; when you enter this command, the terminal will ask you to enter the information you want to save in that file. Let's add some information.
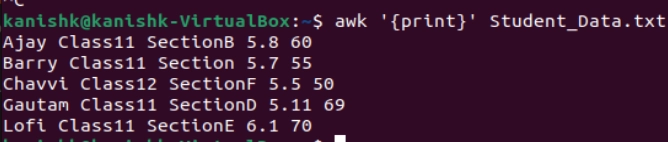
Using the default awk command in Unix, it will print every line of data from the specified file. This statement defines no pattern, so actions are applicable on every line. The following command does the same for "Student_Data.txt," we created above.
$ awk '{print}' Student_Data.txt
The output for the command is shown in the following image:
Search For A Pattern
Suppose we need to get the student's information that belongs to 'SectionB' or 'SectionF.' Then we will use the awk command in unix in the following way:
$ awk '/SectionF/ {print}' Student_Data.txt
The output for the above-mentioned command is shown in the following image:
You can also print the lines which start a particular letter. For example,
$ awk '/^L/ {print}' Student_Data.txt
The output for the above is as follows:
Split Line Into Fields
For each record, the awk command in Unix divides it into multiple columns separated by whitespace and stores it in $n variables. The following points tell us about these variables.
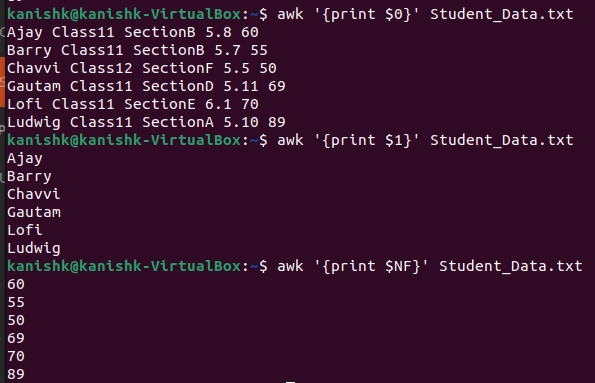
$0:- It represents the whole line. That is {print $0} means print that whole line.
$1,$2,....$n:- These represent different columns; a line with 5 words goes to $5.
$NF:- It is similar to $n, representing the last column.
Let's use some of these commands in our example.
Data Manipulation
Awk commands also process and manipulate data using arithmetic operations. Let's discuss one example of the same.
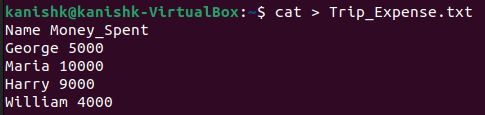
Suppose we create a text file named 'Trip_Expense.txt' that contains the information about money spent by every individual on the trip. We want to calculate the total amount spent.
First, create the text file.
$cat > Trip_Expense.txt
Now, we can calculate the total money spent using the following command.
In this example, the value in the "$2" column gets added to the "total" variable for every record/line. Using the "END" variable, we printed the final value in the "total" variable at the end.
Built-In functions
Some built-in functions are mentioned below:
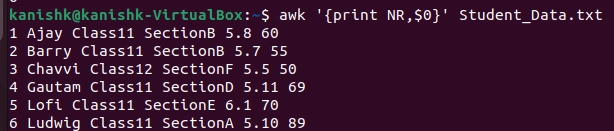
NR: It keeps a current count of input lines. The Awk command performs the pattern-action statements once for each line.
$ awk '{print NR,$0}' Student_Data.txt
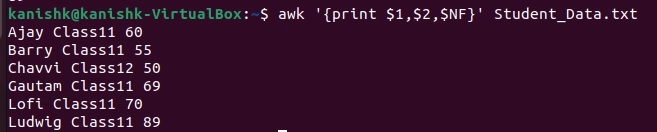
NF: It counts the fields within the current input line. So, it represents the last column.
$ awk '{print $1,$2,$NF}' Student_Data.txt
FS: It contains the field separator character, which divides fields on the input line. The default is "white space," but it can be reassigned.
We will create a text file named "Student.txt" using the touch command. Then, we can open and edit the text file using the nano command. The following image shows the data present in the Student.txt file.
The following shows the usage of the FS command.
$ awk 'BEGIN {FS = ","} {print}' Student.txt
RS: It stores the current record separator character. The default record separator character is a new line.
We will create a text file named "Student.txt" using the touch command. Then, we can open and edit the text file using the nano command. The following image shows the data present in the Student.txt file.
The following shows the usage of the RS command.
$ awk 'BEGIN {RS = ";"} {print}' Student.txt
OFS: It stores the output field separator, which separates the fields when printed. The default is a blank space.
$ awk 'OFS = ","{print $1,$2}' Student_Data.txt
ORS: It stores the output record separator, which separates the output lines when printed. The default is a newline character.
$ awk 'BEGIN {OFS = ";"}{print} END {print "\n"}' Student_Data.txt
Miscellaneous Example
In this part, we will see one more example of the Awk command in Unix.
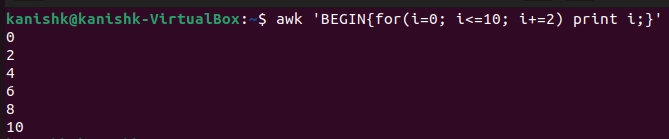
If you want to print even numbers from 0 to n(replace n with desired value), then we can use the following command (here n = 10):
$ awk 'BEGIN{for(i=0; i<=10; i+=2) print i;}'
Frequently Asked Questions
Q. What is the full form of awk?
The full form of awk is "Aho, Weinberger, and Kernighan." It's named after its creators, Alfred Aho, Peter Weinberger, and Brian Kernighan, who developed the tool for text processing in Unix.
Q. Why is awk file used?
An AWK file, often with a .awk extension, is used to store AWK scripts. It contains a series of commands and patterns to process and manipulate text data efficiently using the AWK tool.
Q. Is awk better than grep?
AWK and grep serve different purposes. grep is for searching and filtering text, while AWK is for text processing and manipulation. Which is better depends on your specific task.
Conclusion
We hope this article was insightful and you learned something new. In this blog, we learned about the Awk command in Unix. It is a powerful tool for text processing and manipulation. We discussed its syntax and also discussed many different examples for better understanding. We saw that we could also create loops and conditional statements with it, and it uses with many built-in functions. If you want to learn more about Unix, do visit








































 8+ registered
8+ registered 

