



























Introduction
In this blog, we will learn about AWS Glue in-depth, so let's begin with a brief introduction to AWS glue. AWS Glue is a serverless ETL solution. ETL stands for extract, transform, and load, and it refers to three procedures often used in Data Analytics and Machine Learning. It gives businesses a data integration tool that prepares data from multiple sources and organizes it in a central repository where it can be used to make business decisions. Data analysis and categorization is one of its primary capabilities.
How It Works
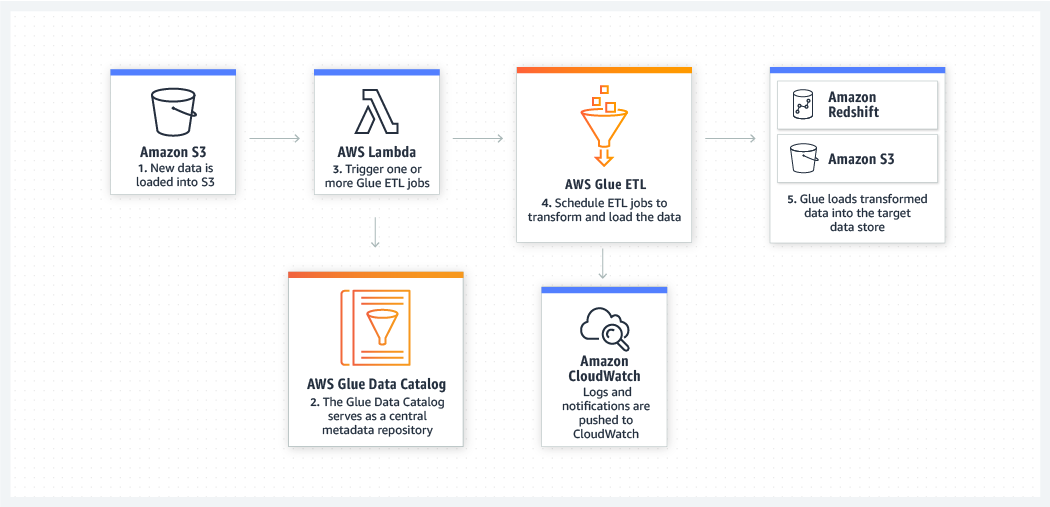
AWS Glue manages all ETL data transfer and transformation into Data Lakes like Amazon S3 and Data Warehouses like Amazon Redshift using other AWS services. It uses APIs to collect data from many sources and then transform it to complete Data Integration tasks.
ETL jobs can be scheduled or have trigger events configured to launch them. It generates code depending on the user's input and then extracts and transforms data automatically using the code. The code in the scripts can be changed as needed. The metadata from the job is then written to Data Catalog, which serves as a metadata repository.
Since we have discussed AWS glue and how it works, let's move on to its architecture.
The following are the many components of the AWS Glue Architecture:
1) Amazon Web Services Management Console
The AWS Management Console is a web application for managing AWS resources in your browser. It includes the following features:
- Crawlers, jobs, tables, and connections are examples of AWS Glue objects.
- Creates a working layout for crawlers.
- Job trigger events and timelines are created.
- Searches and filters Glue objects to Amazon Web Services.
- Scripts for transformation scenarios are edited.
2) AWS Glue Data Catalog
AWS Glue Data Catalog provides a centralized standard metadata storage solution for data tracking, querying, and transformation.
3) AWS crawlers
Crawlers and classifiers scan data from various sources, classify it, detect schema information, and store it in the AWS Glue Data Catalog.
4)AWS ETL Operations
The ETL program generates Python or Scala code for data cleaning, enrichment, duplicate removal, and other complex data transformation tasks.
5) Jobs Scheduling System
A flexible scheduling system is in charge of starting jobs based on different events or timetables.
AWS Glue Concepts
In AWS Glue, you define tasks to extract, transform, and load (ETL) data from a data source to a target. The following are typical actions you take:
-
You construct a crawler to populate your AWS Glue Data Catalog with metadata table definitions for data storage sources. When you aim your crawler at a data store, the crawler generates table definitions in the data catalog. You define Data Catalog tables, and data stream attributes manually for streaming sources.
The AWS Glue Data Catalog also contains other metadata that is required to define ETL operations, in addition to table definitions. When you describe a job to alter your data, you use this metadata.
-
AWS Glue may build a script for data transformation. You can also use the AWS Glue console or API to provide the script.
- You can run your job on-demand or schedule it to begin when a specific event occurs. A timer or an event can be used as the trigger. A script extracts data from your data source, alters it, and loads it to your data target when your job executes. In AWS Glue, the script runs in an Apache Spark environment.

Now that we have seen the concepts of AWS glue let's look at some key features.




 8+ registered
8+ registered 

