


























Introduction
Have you ever wondered how tech unicorns that have large volumes of big data stores and data lakes manage all kinds of data sources (Relational, NoSQL, Datasets, data dumps etc. so effectively, securely and efficiently!?
It is mostly due to the AWS Lake Formation service.
In this article, we will cover what the AWS Lake Formation service is and try to understand its significance, uses, configurations and so on.
Let's start with "What is AWS Lake Formation service and how it can be used to serve high-end business requirements at scale"?
Definition
AWS Lake Formation is a managed data lake service which eliminates the large overhead of maintaining multiple types of databases and data stores after moving them from source to a data repository. It allows one to create data lakes which used to be a difficult and tedious feat of many weeks in a matter of just a few days.
The architecture of AWS Lake Formation service:
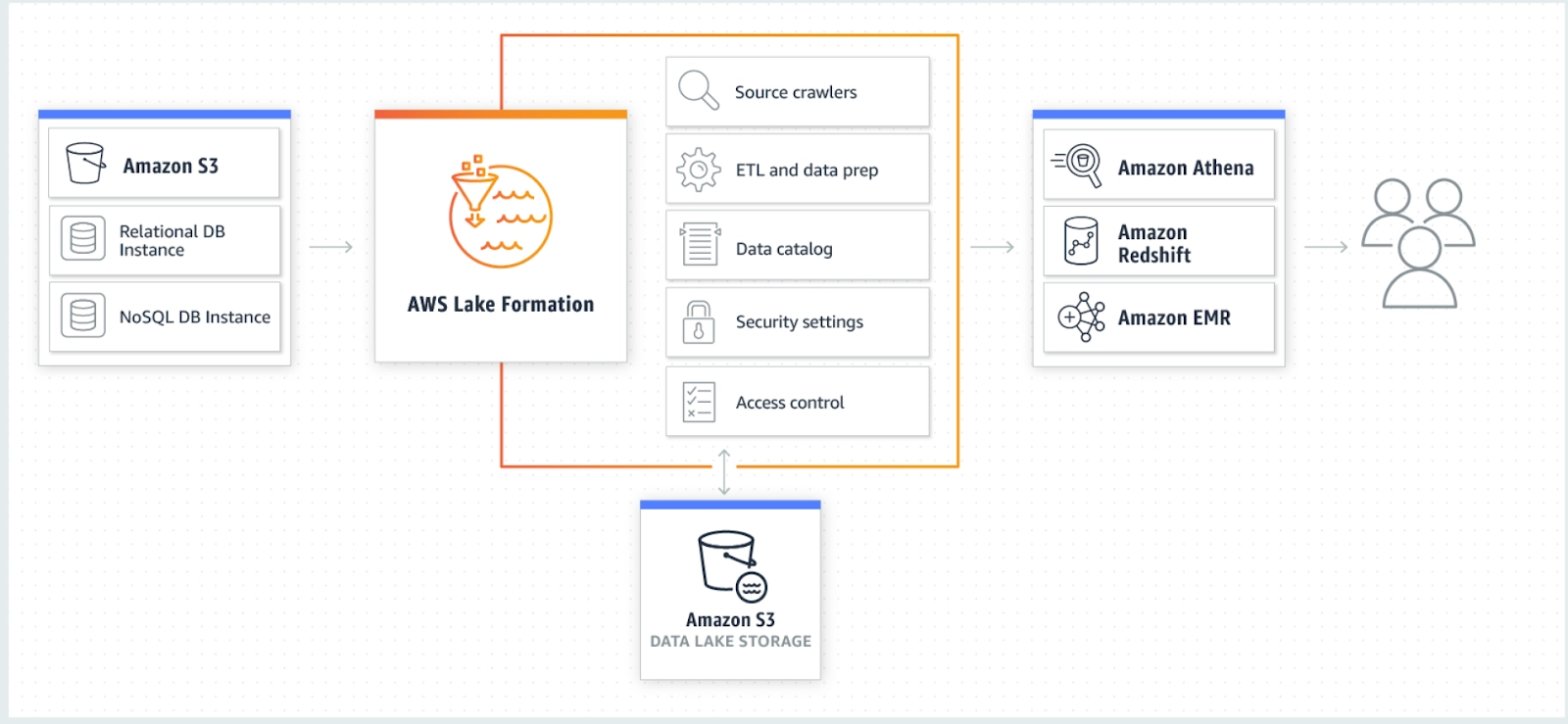
The AWS Lake Formation service can help build, secure, reliable and managed data lakes. First, it identifies existing data stores of various kinds such as in S3 or relational and NoSQL databases and moves the data into your S3 data lake inside the Lake Formation which can then be crawled, catalogued, and prepared for analytics. Also, it provides the users with secure self-service access to the data through their choice of analytics services. Various other types of AWS services and third-party applications can also access data through the lakes formed. Lake Formation manages all overhead tasks such as maintaining data pipelines, moving data from sources after crawling, security and access control management and can be easily integrated with the data stores and services such as Amazon EMR, Amazon Redshift, and Amazon Glue etc.
Creating a data lake using the Lake Formation service is as simple as defining data sources and what access and security policies the user wants to apply to it. Lake Formation then helps one collect and catalogue data from a variety of databases and object storage, move data into a new Amazon Simple Storage Service (S3) data lake after automatically cleaning and classifying the data using ML algorithms, and then securing access to all the sensitive data using granular controls at the column, row, or even cell-levels. Users can access a centralized data catalogue that describes available datasets and their appropriate usages. They then can use these datasets with their choices of analytics and ML services, such as Amazon EMR for Apache Spark, Amazon Redshift, Amazon Athena, and Amazon QuickSight. The AWS Lake Formation builds on the capabilities that are also available in the AWS Glue service.


 9+ registered
9+ registered 

