Do you think IIT Guwahati certified course can help you in your career?
Introduction
Welcome readers! We hope you are doing well.
Did you ever try to learn Azure Data Factory but due to some circumstances, you could not make it? Don’t worry, Coding Ninjas is there to help you out.
Today in this article, we will discuss the Azure Data Factory with a proper explanation. This article will give you enough knowledge about the Azure Data Factory. So follow the article till the end.
So, without wasting more time, let’s start our discussion.
What is Azure Data Factory
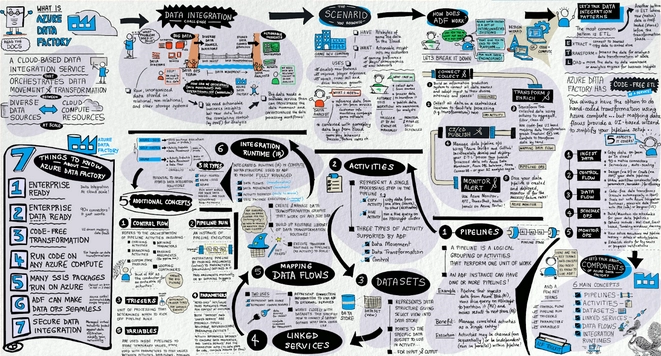
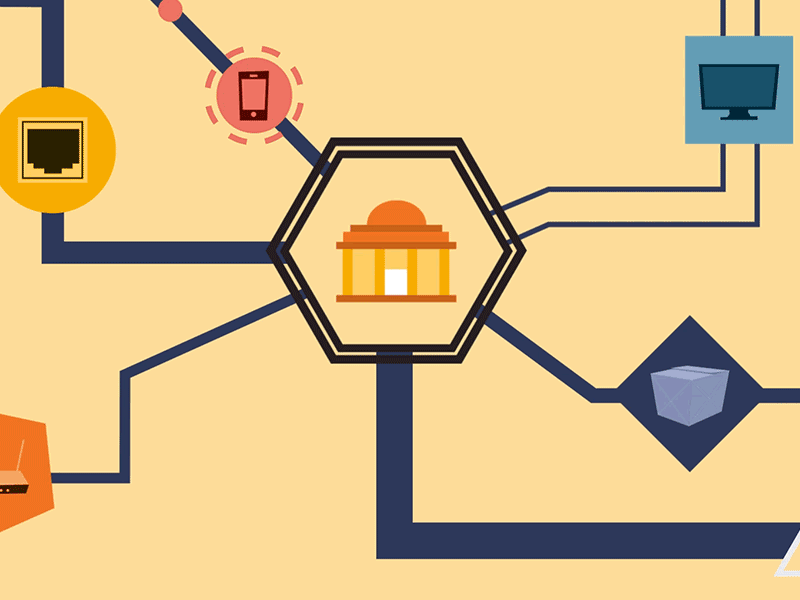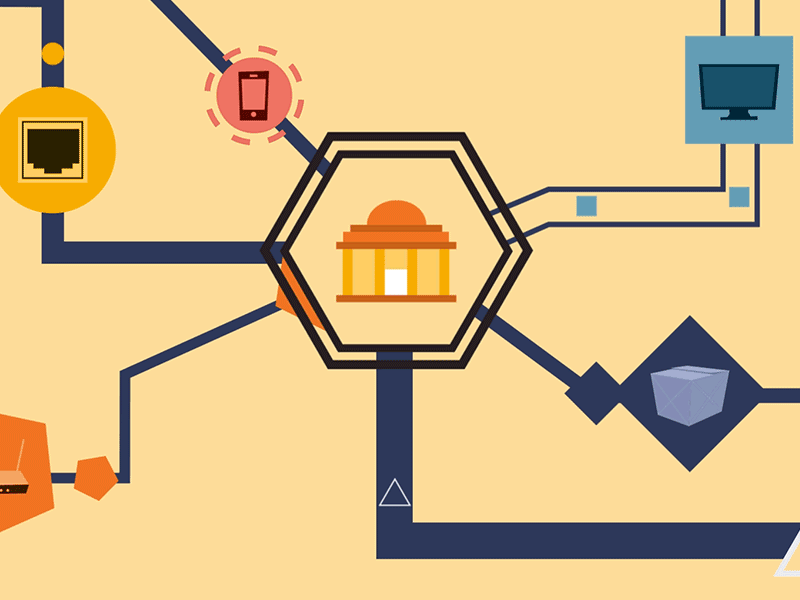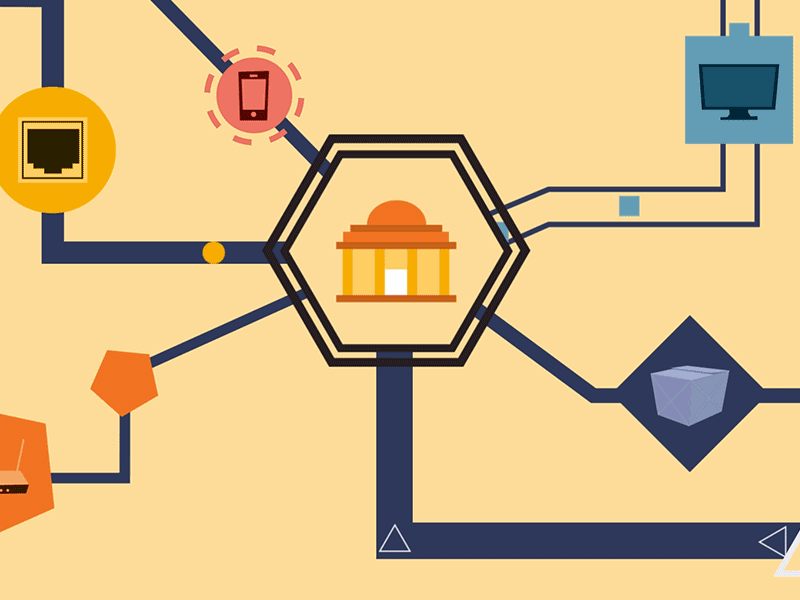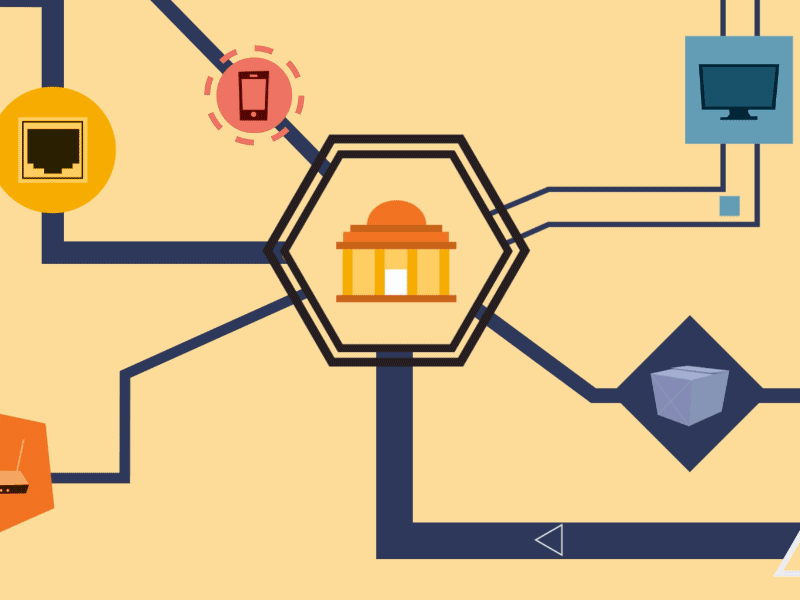
Azure Data Factory is a cloud-based, serverless and fully managed data integration service offered by the Azure platform of Microsoft to enable data integration from many different sources. It allows us to create and schedule data-driven workflows(also known as pipelines) in the cloud. The Azure Data Factory is perfect for building hybrid ETL(extract-transform-load), ELT(extract-load-transform) and data integration pipelines on the cloud.
How does Azure Data Factory Work?
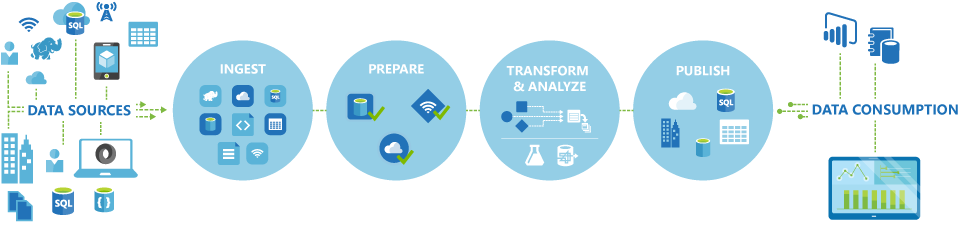
The Azure Data Factory(ADF) works in four steps:
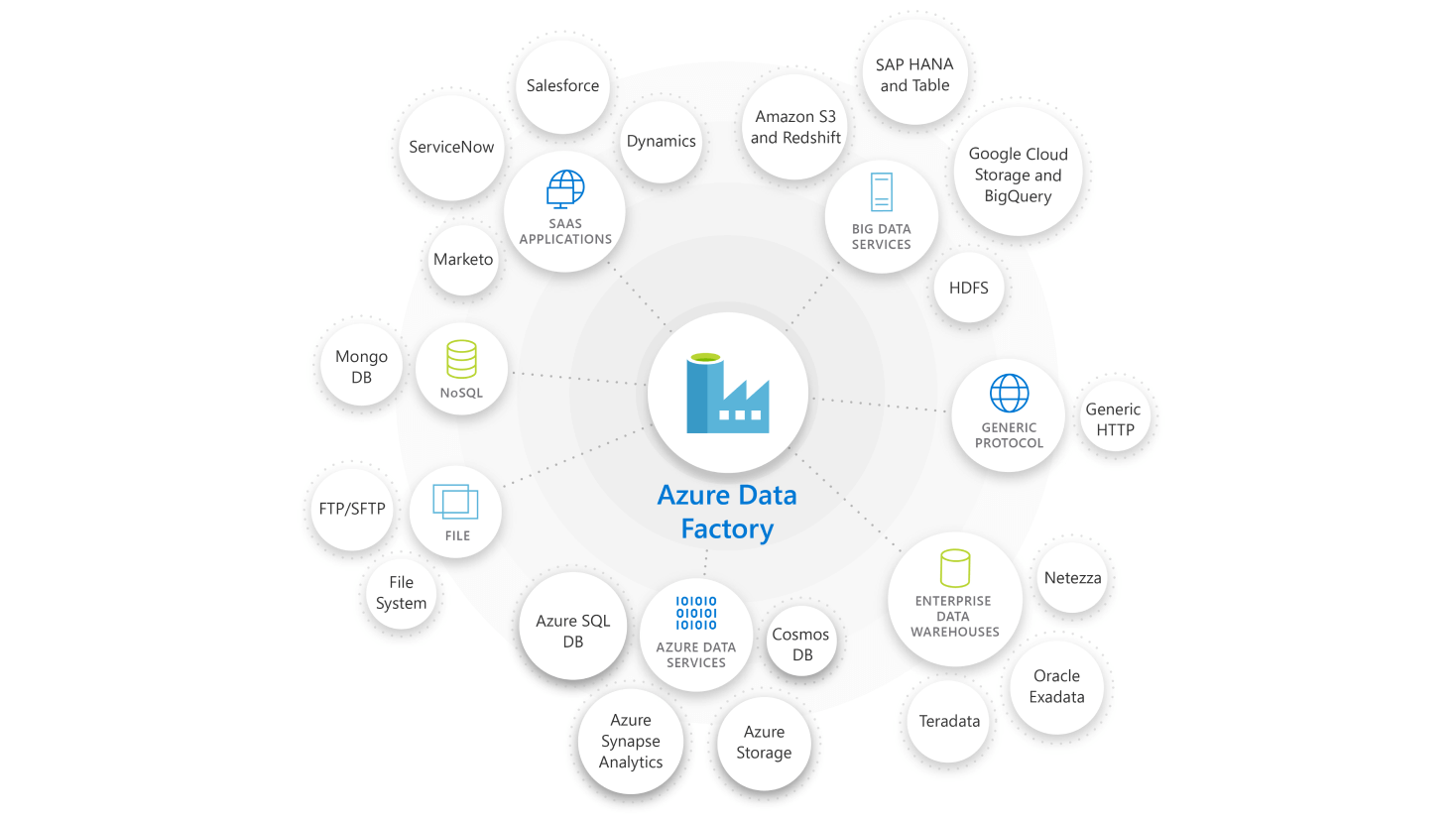
Connect & Collect: The organisations have various types of data stored in different locations such as on-premises, in the cloud etc. They all arrive at different intervals and speeds. The first step is connecting to all the data and processing sources, such as databases, Software as a Service(SaaS) services, file shares etc. Then, move the data to a centralised location for further processing.
Transform: After moving the data to a centralised data store in the cloud, transform the collected data using the ADF(Azure Data Factory) mapping data flow or by using compute services such as HDInsight Hadoop, Spark, Machine Learning and Data Lake Analytics.
Publish: After refining the raw data into a business-ready consumable form, send it to a destination data storage such as Azure Data Warehouse, Azure SQL Database, Azure Cosmos DB or analytics engine.
Monitor: Azure Data Factory(ADF) has in-built support for monitoring the data integration pipeline on the Azure portal via Azure monitor, Azure Monitor logs, health panels, API and PowerShell.
Key Components
Following are the key components of the Azure Data Factory:
Pipelines
Activities
Datasets
Linked Services
Triggers
Data Flows
Integration Runtimes
The components work together to perform data-driven workflows to move and transform data with different steps mentioned earlier.
Let’s now discuss each of these components separately.
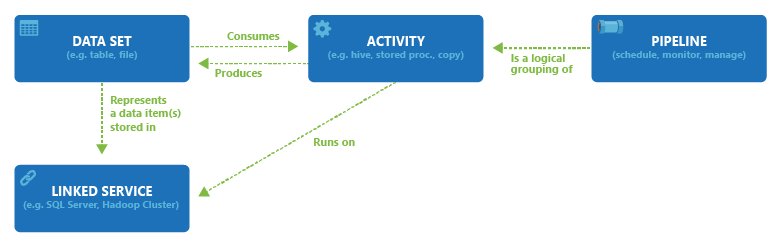
Pipelines
Pipelines are the logical grouping of activities that perform a unit of work. An Azure data factory can have one or more pipelines. The activities in the pipeline altogether perform a task.
For example, a pipeline containing a group of activities ingest data from the Azure blob. Then it runs a Hive query on an HDInsight cluster for data partitioning.
The main benefit of performing a task by the activities is that it allows you to manage a group of activities together instead of managing them individually. Either you can chain the activities in a pipeline to operate sequentially, or they can operate parallelly.
Activities
The activity denotes a processing step in a pipeline. For example, a copy activity copies data from one data store to another, and a hive activity runs a Hive query on an Azure HDInsight cluster to transform the data.
The Azure Data Factory(ADF) supports three types of activities:
Data movement activities
Data transformation activities
Control activities
Datasets
The datasets represent the data structures within the data stores. It just references the data that you want to use in your activities.
Linked Services
The linked services define the information needed for Data Factory to connect to external resources. They are much similar to connection strings.
The linked services in the Data Factory are mainly used for two purposes:
To represent a data store.
To represent a compute resource for hosting the execution of an activity.
Triggers
In Azure Data Factory, Triggers represent the unit of processing. It initiates the execution of the pipeline. It also determines when a pipeline execution needs to be kicked off.
There are three different types of triggers in Azure Data Factory:
Schedule Trigger: This type of trigger invokes a pipeline at a specific time and frequency.
Tumbling Window Trigger: This type of trigger works on a periodic interval.
Event-based Trigger: This type of trigger invokes the pipeline to respond to a blob-related event.
Data Flows
Data Flows are the special activities that allow the development of a data transformation logic visually without writing code. Using the visual editor, you can transform the data in multiple steps. They are executed inside the ADF pipeline on the Azure Databricks cluster for scaled-out processing using Spark. ADF controls all the data flow execution and code translation.
Mapping data flows: In Azure Data Factory(ADF), the mapping data flows are the visually designed data transformations. It is used to create and manage graphs of data transformation logic that can be used to transform data of any size without writing code. You can build and execute a reusable library of data transformation routines from your ADF pipelines.
Control flow: It is an orchestration of the pipeline activities. It includes chaining activities in a sequence, branching, defining parameters at the pipeline level and passing the arguments while invoking the pipeline on-demand. It also includes custom state passing and looping containers, i.e. (for-each iterators).
Integration Runtimes
In Azure Data Factory, we previously discussed the activity, which is nothing but an action to be performed. We also discussed the linked services as a target data store or a compute service.
An integration runtime provides the bridge between the activity and the linked services. It provides a computing environment where the activity either runs on or gets dispatched from.
Benefits
Some of the benefits of the Azure Data Factory are mentioned below:
Azure Data Factory is a cloud-based solution that works with both on-premise and cloud-based data stores, giving cost-effective and scalable solutions.
You can easily migrate the ETL workloads to the Azure cloud from the on-premises data stores.
Azure Data Factory comes up with many default connectors with close to all on-premise data sources, including MySQL, SQL Server, and Oracle DBs, which makes it effortless for different activities.
Azure Data Factory has Mapping Data Flows to create and manage graphs of data transformation logic that can be used to transform data of any size without writing code.
It can run the SSIS(SQL Server Integration Service) package in an Azure-SSIS integration runtime.
Azure Data Factory gives managed virtual networks to simplify your networking and protect against data exfiltration.
Frequently Asked Questions
What do you mean by Azure Data Factory?
Azure Data Factory is a cloud-based, serverless and fully managed data integration service offered by the Azure platform of Microsoft to enable data integration from many different sources.
Is Azure Data Factory an ETL tool?
Yes, Azure Data Factory is a cloud-based ETL and data integration service offered by the Azure platform of Microsoft to enable data integration from many different sources.
Is Azure Data Factory PaaS or SaaS?
The Azure Data Factory is a Microsoft PaaS solution that enables data transformation and load. It also supports data movement between the on-premise and cloud data sources.
What is the main difference between the Azure Data Factory and SSIS?
The main difference between the Azure Data Factory and the SSIS(SQL Server Integration Service) is that SSIS is an on-premises tool and is mostly suited for on-premises use cases. On the other hand, the Azure Data Factory(ADF) is a cloud-based tool typically suited for cloud-based use cases.
Conclusion
In this article, we have extensively discussed the Azure Data Factory.
We started with a brief introduction to the article. Then we discussed the followings:






























 18+ registered
18+ registered 

