


























Introduction
Azure Databricks is a cloud-based service that helps you analyze and process big data. It's like a powerful computer program that can help you turn large amounts of data into useful information. This can help you make better decisions, improve your products and services, and make your business more efficient.
Think of Azure Databricks as a digital notebook where you can run and store your data analysis projects. You can use it to import data from various sources, clean and process that data, and then run calculations and visualizations to gain insights. You can also use it to build and train machine-learning models.
In short, Azure Databricks is a tool that makes it easier to work with big data and extract insights from it, all in a secure and collaborative environment.

In this article, we are going to discuss Azure Databricks Interview Questions.
Most Asked Azure Databricks Interview Questions
1. What is Databricks?
Databricks is a company founded in 2013 and headquartered in San Francisco, California. It is the creator of the Apache Spark-based platform called "Databricks", which is a cloud-based platform for data engineering, machine learning, and collaborative data science.

Databricks provides a collaborative environment for data engineers, data scientists, and business analysts to work together on data projects. It offers a web-based notebook environment, which makes it easy to develop, run, and share data analysis projects.
The platform also provides tools for ingesting, transforming, and preparing data and advanced analytics capabilities such as graph processing, time-series analysis, and geospatial analysis.
Also read, project manager interview questions
2. What is Azure Databrick?
Azure Databricks is a tool that helps you work with and analyze big data in the cloud. It's like an online notebook where you can store and run your data projects. You can use it to import data from different sources, clean and process the data, and then use that data to get insights and make decisions. It also has features for building and training machine learning models.
Think of Azure Databricks as a tool that makes working with big data easier and more efficient. It provides a secure and collaborative environment where you can work with others on your data projects and extract meaningful insights from the data.
3. What are the advantages of using Azure Databricks?
Azure Databricks is a powerful platform for processing big data and provides several advantages, including
- Scalability: Azure Databricks allows you to quickly and easily scale your cluster resources up or down as needed, making it easy to handle large data sets and meet your computing needs.
- Integration with Azure services: Azure Databricks integrates seamlessly with other Azure services, such as Azure Blob Storage, Azure Data Lake Storage, and Azure SQL Database, allowing you to store, access, and analyze your data easily.
- Apache Spark-based: Azure Databricks is built on Apache Spark, a powerful and widely used open-source big data processing framework. This allows you to leverage Spark's rich ecosystem of libraries and tools to process and analyze your data
Must Read Apache Server
4. Define caching.
The term cache refers to the practice of temporarily storing information. When you visit a frequently visited website, your browser retrieves the information from the cache rather than the server. This saves time and reduces the load on the server. This is precisely known as caching.
5. Is it safe to clear the cache?
Yes, clearing the cache is acceptable because any program does not require the information.
6. Is it necessary to store the outcome of an action in a different variable?
It is not required to store the outcome of an action in a different variable. It would be entirely dependent on the intended use.
7. Should you get rid of any unused Data Frames?
Cleaning Data Frames is not necessary unless you use a cache, which consumes a significant amount of data on the network.
8. How do you troubleshoot Azure Databricks issues?
The best place to begin troubleshooting with Azure Databricks is with the documentation, which contains solutions to a variety of common issues. Databricks support can be contacted if additional assistance is required.
9. Is Azure Key Vault a viable replacement for Secret Scopes?
Azure Key Vault can be used as a replacement for secret scopes in Azure DevOps, but it depends on your specific use case and requirements. In general, if you need to store secrets that you need to access from multiple Azure DevOps organizations or other cloud-based services, you may find Azure Key Vault more convenient.
However, secret scopes may be a more convenient solution if you only need to manage secrets for a single Azure DevOps organization and don't need to access them from other services.
10. What languages does Azure Databricks support?
Python, Scala, and R are examples of programming languages that can be used. SQL can be used with Azure Databricks as well.
Click on the following link to read further: Javascript Interview Questions and Answers
11. What are the major features of Azure Databricks?
Some key features of Azure Databricks include:
- Collaborative Workspaces: Azure Databricks provides a collaborative environment for data engineers, data scientists, and business analysts to work together on the same project.
- Data Ingestion and Preparation: It provides tools for ingesting and transforming data from various sources, including cloud data stores like Azure Data Lake Storage and relational databases like Azure SQL Database.
- Machine Learning and AI: Azure Databricks provides a platform for building and deploying machine learning models, with integrations for popular machine learning frameworks like TensorFlow and PyTorch.
- Advanced Analytics: It supports advanced analytics, including graph processing, time-series, and geospatial analysis.
12. What are some issues you can face with Azure Databricks?
Like any technology platform, Azure Databricks can face certain issues you need to be aware of.
Some common issues include:
- Cost: Azure Databricks can be expensive, especially if you have large data sets and need to provision a large cluster to process them. Careful planning and management of your cluster resources are important to keep costs under control.
- Complexity: While Azure Databricks provides a lot of powerful features, the platform can also be complex to set up and use, especially if you're new to Apache Spark and big data processing. This can make it challenging for some users to get started and get the most out of the platform.
- Integration with other tools: Integrating Azure Databricks with other tools and technologies can also be challenging, especially if those tools are not natively supported by the platform. You may need to write custom code or use third-party solutions to connect Databricks to other systems.
- Performance: Performance can also be an issue with Azure Databricks, especially if you have large data sets or complex queries. You may need to tune your cluster configuration or write optimized Spark code to ensure optimal performance.
- Data security: Securing and managing sensitive data can be challenging in any big data platform, and Azure Databricks is no exception. You'll need to carefully plan and implement security measures, such as encryption, access controls, and data masking, to keep your data secure.
13. In Databricks, what is the difference between an instance and a cluster?
In Azure Databricks, an instance is a single virtual machine (VM) that runs Apache Spark, and a cluster is a collection of instances that work together to process and analyze data.

An instance provides the computational power and memory needed to run Spark jobs and store data in memory. You can run multiple instances in parallel to process large data sets, and each instance can be used to run multiple Spark tasks in parallel.
A cluster, on the other hand, is a collection of instances that work together as a single unit to process and analyze data. When you create a cluster, you specify the number of instances you want to include, as well as the amount of memory and CPU resources each instance should have.
In short, an instance is a single unit of computational power in Databricks, while a cluster is a group of instances that work together to process big data.
14. What is the management plane in Azure Databricks?
The management plane in Azure Databricks refers to the set of features and tools that are used to manage and configure the platform.
It provides a set of tools and features that you can use to manage your Spark clusters, Spark jobs, libraries, secrets, and configurations, ensuring that your big data processing runs smoothly and effectively.
15. What is the control plane in Azure Databricks?
The control plane in Azure Databricks refers to the underlying infrastructure and components that manage and orchestrate the processing of big data.
It provides the underlying infrastructure and components that run big data processing and makes it possible to process and analyze large data sets efficiently and effectively.
Spark applications are managed by the control plane.
16. What exactly is the data plane in Azure Databricks?
The data plane in Azure Databricks refers to the components responsible for the storage, processing, and retrieval of data within the platform.
This includes features like Databricks file system (DBFS), tables, and Delta lake for storing data, as well as the Spark engine for processing it.
In simple terms, the data plane provides a foundation for data management and data processing in Azure Databricks, making it possible to store, process, and analyze large amounts of data in a fast and efficient manner. This is the part of Azure Databricks that is responsible for handling and transforming the raw data into actionable insights.
By using the data plane in Azure Databricks, you can simplify the process of working with big data, as well as reduce the time it takes to turn data into meaningful insights. Additionally, the data plane provides a variety of tools and features to help you manage and process data, making it possible to work with data at scale.
17. What is the use of Kafka in Azure Databricks?
Apache Kafka is an open-source, distributed streaming platform that can be used in Azure Databricks to ingest, process, and store large amounts of real-time data. In Azure Databricks, you can use Kafka as a source or sink for data, which enables you to build streaming data pipelines to process data in real-time.
18. What is the major reason behind using Kafka in Azure Databricks?
Kafka is used in Azure Databricks to provide a scalable and reliable way to stream data into the platform. You can use it to publish real-time data streams, such as logs, events, or metrics, to a Kafka cluster, and then use Spark Streaming to process and analyze the data. Additionally, you can use Kafka to store the processed data in Delta Lake, which provides a scalable and reliable data lake for big data.
19. What are some of the key use cases of Kafka in Azure Databricks?
Some of the key use cases of Kafka in Azure Databricks include:
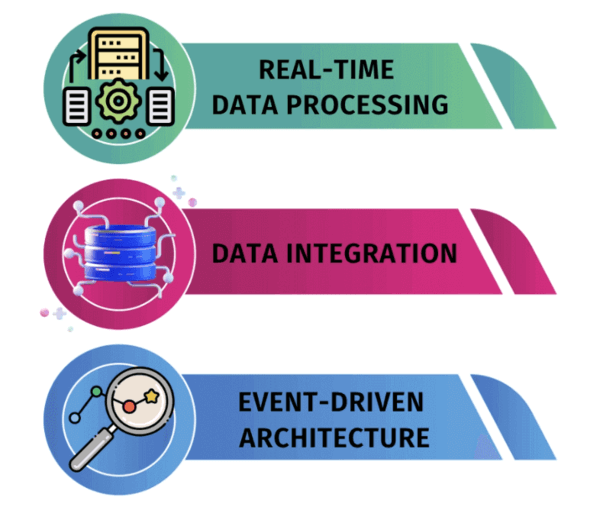
- Real-time data processing: By using Spark Streaming in Azure Databricks, you can process real-time data from a Kafka stream in near real-time. This enables you to gain real-time insights from your data.
- Data integration: You can use Kafka to integrate data from multiple sources and stream it into Azure Databricks for processing and analysis. This can help you build a comprehensive data pipeline for big data.
- Event-driven architecture: You can use Kafka to publish events, such as changes to data or user interactions, and then process these events in real-time using Spark Streaming in Azure Databricks.
20. What is the benefit of using Kafka in Azure Databricks?
The use of Kafka in Azure Databricks enables you to build scalable, reliable, and high-performance data pipelines for big data, helping you to turn real-time data into actionable insights.
21. What is DBU in Databricks?
In Databricks, "DBU" is a unit of measurement for Databricks cluster usage, specifically for resource allocation and billing purposes. A DBU is a blended unit of compute and memory resources, representing the computational power of a virtual machine. Databricks customers can provision and run their Apache Spark workloads on Databricks clusters, and their usage of those clusters is measured and billed in DBUs.
DBUs allow Databricks customers to pay for only the resources they use, rather than having to allocate and pay for entire virtual machines. This makes it easier for customers to scale their cluster resources up or down as needed without having to worry about the complexities of managing individual virtual machine instances.
22. How would you use Azure Databricks to process big data?
Azure Databricks is a powerful platform for processing big data, and here's a high-level overview of how you might use it:
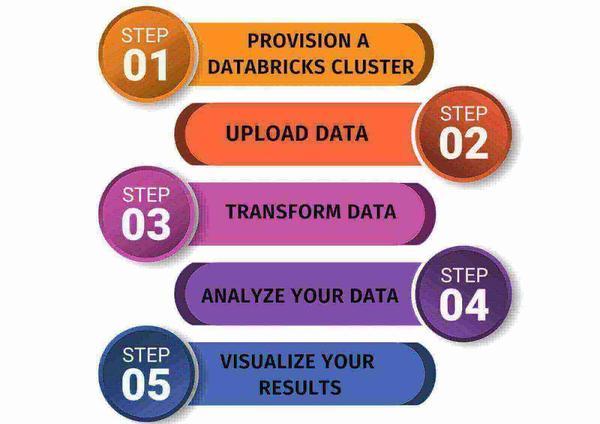
- Provision a Databricks cluster: To get started, you'll need to create a Databricks cluster, which is a collection of virtual machines that run Apache Spark. You can provision clusters in the Azure portal or through the Databricks REST API.
- Upload your data: You can upload your data to Databricks by storing it in Azure data stores such as Azure Blob Storage, Azure Data Lake Storage, or Azure SQL Database and then accessing it from your Databricks cluster.
- Transform your data: Once your data is uploaded, you can use Spark SQL, Spark Streaming, and other Spark libraries to transform it into a suitable form for analysis. Depending on your needs, this might involve filtering, aggregating, or pivoting your data.
- Analyze your data: Databricks provides a wide range of analytics tools and machine learning algorithms that you can use to analyze your data. For example, you might use Spark MLlib to train machine learning models or use Databricks' built-in SQL analytics functions to perform ad-hoc queries on your data.
- Visualize your results: Finally, you can use Databricks' built-in visualization tools, or export your results to other visualization tools, such as Power BI, to view and explore your results.
23. Can you give an example of a data analysis project you've worked on using Azure Databricks?
Sample Answer: Imagine you have a retail company that wants to analyze customer purchase data to understand their buying behavior and improve their sales and marketing strategies.
You could use Azure Databricks to perform the following steps:
- Data ingestion: You can use Azure Databricks to ingest the customer purchase data from various sources, such as a relational database, Amazon S3, or Kafka.
- Data cleaning and transformation: You can use Spark in Azure Databricks to perform data cleaning and transformation, such as removing missing values, duplicates, and converting data types.
- Data storage: You can store the cleaned and transformed data in Delta Lake, which provides a scalable and reliable data lake for big data.
- Data analysis: You can use Spark SQL, machine learning libraries, and visualization tools in Azure Databricks to perform data analysis and uncover insights. For example, you can use Spark SQL to aggregate data by customer segments and compute key metrics, such as the average purchase value and the frequency of purchases. You can also use machine learning algorithms, such as regression or clustering, to predict customer behavior and segment customers based on their purchase history.
- Data visualization: You can use the built-in visualization tools in Azure Databricks to create interactive dashboards, charts, and graphs to visualize the results of your analysis.
Using Azure Databricks, you can simplify the process of working with big data and turn the customer purchase data into actionable insights that can help the retail company improve its sales and marketing strategies.
24. How would you ensure the security of sensitive data in an Azure Databricks environment?
Ensuring the security of sensitive data in an Azure Databricks environment is crucial to protecting sensitive information and complying with data protection regulations.
Here are some steps that you can follow to secure sensitive data in Azure Databricks:
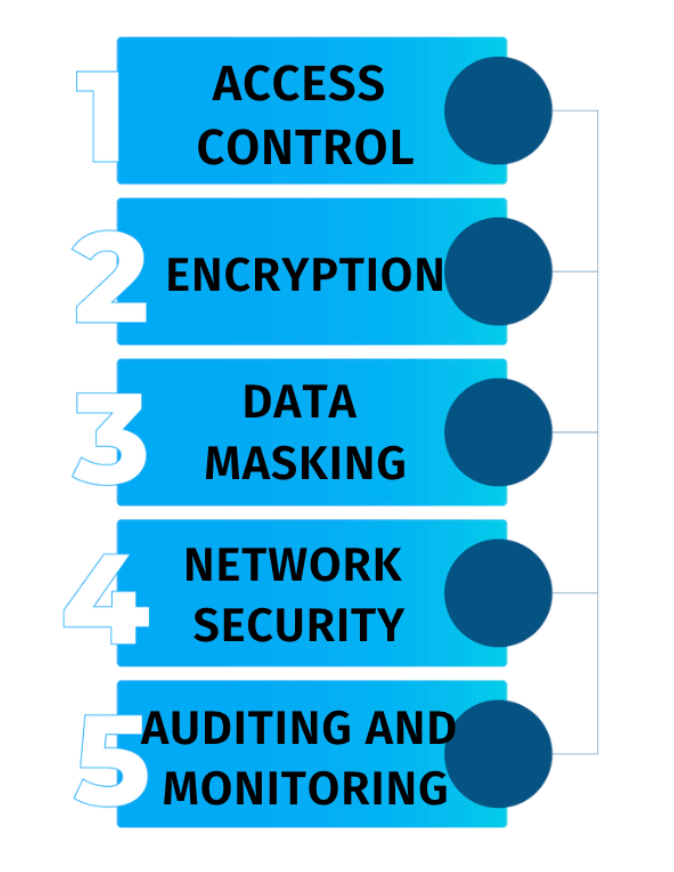
- Access control: You can use Azure Active Directory (AD) to manage access to Azure Databricks and control who can access the data. You can also use role-based access control (RBAC) to assign different access levels to users and groups.
- Encryption: You can use encryption to protect sensitive data at rest and in transit. Azure Databricks supports encryption at rest using Azure Key Vault and Azure Storage Service Encryption. You can also encrypt data in transit using SSL/TLS.
- Data masking: You can use data masking techniques, such as anonymization, pseudonymization, and encryption, to protect sensitive data fields, such as social security numbers and credit card numbers.
- Network security: You can use virtual networks and firewall rules to secure the network connection between Azure Databricks and other Azure services and control access to the data from the internet.
- Auditing and monitoring: You can use Azure Monitor to track activities and detect potential security threats in Azure Databricks. You can also use Azure Log Analytics to analyze logs and monitor the security of the data.
25. Can you explain the concept of collaborative workspaces in Azure Databricks?
Collaborative workspaces in Azure Databricks provide a collaborative environment for data engineers, data scientists, and business analysts to work together on big data projects. With collaborative workspaces, you can share notebooks, data, and models and collaborate in real-time on the same project.
Collaborative workspaces in Azure Databricks provide a unified environment for data engineers, data scientists, and business analysts to work together on big data projects, helping to simplify the collaboration process and ensure that everyone has access to the latest data, models, and insights.
26. Which of these two options, a Databricks instance or a cluster, is superior?
In general, if you're looking for a fully managed platform for your big data and AI workloads, a Databricks instance may be the superior option. If you're looking for a scalable and flexible platform for running Spark jobs, a cluster may be the superior option.
Ultimately, the choice between a Databricks instance and a cluster will depend on your specific use case and requirements. You may find that using both a Databricks instance and clusters is the best solution for your needs.
27. Which cloud service category does Microsoft's Azure Databricks fall under: SaaS, PaaS, or IaaS?
Microsoft Azure Databricks belongs to the Platform as a Service (PaaS) category of cloud services.

- In PaaS, the cloud provider manages the infrastructure and provides a platform for building, deploying, and running applications and services. The provider takes care of the underlying infrastructure, such as servers, storage, and networking, allowing customers to focus on building and deploying their applications and services.
- With Azure Databricks, customers can build and run big data and machine learning workloads on a fully managed cloud-based platform that runs on top of Apache Spark.
- The platform provides a suite of tools and services for data processing, machine learning, and collaboration, and the underlying infrastructure is managed by Microsoft.
- By using a PaaS like Azure Databricks, customers can avoid the costs and complexity of managing their own infrastructure and focus on building and deploying their applications and services.
28. What are the differences between Microsoft Azure Databricks and Amazon Web Services Databricks?
Microsoft Azure Databricks and Amazon Web Services (AWS) Databricks are both cloud-based platforms for data engineering, machine learning, and analytics that run on top of Apache Spark. However, there are some differences between the two platforms.
Cloud Provider

The main difference between the two platforms is the underlying cloud provider. Microsoft Azure Databricks runs on the Microsoft Azure cloud platform, while AWS Databricks runs on the Amazon Web Services cloud platform.
Integration with Other Services
Another difference is the level of integration with other cloud services offered by the provider. Microsoft Azure Databricks integrates with other Azure services, such as Azure Active Directory, Azure Blob Storage, and Azure Data Lake Storage. AWS Databricks integrates with other AWS services, such as Amazon S3, Amazon DynamoDB, and Amazon Redshift.
Pricing

The pricing for the two platforms can also differ, depending on the specific services used and the amount of resources consumed. Customers should compare the pricing for both platforms based on their specific use case and requirements.
29. What is Serverless Database Processing in Azure?
Serverless database processing in Azure refers to the ability to process database workloads without having to provision and manage infrastructure. This allows you to scale your database processing resources as needed, without having to worry about capacity planning and management.
- In Azure, serverless database processing is provided by Azure Functions and Azure Synapse Analytics (formerly SQL Data Warehouse).
- With Azure Functions, you can create serverless functions that can be triggered by various events, including database updates. This allows you to process data in real-time as it arrives in your database, without having to provision and manage infrastructure.
- With Azure Synapse Analytics, you can process large amounts of data using a combination of on-demand and provisioned resources.
- Azure Synapse provides a serverless experience for big data and data warehousing workloads, allowing you to scale your processing resources as needed without having to worry about capacity planning and management.
30. What is the most efficient way to migrate data from an on-premises database to one hosted on Microsoft Azure?
The most efficient way to move information from an on-premises database to one hosted on Microsoft Azure will depend on the specific requirements and constraints of the migration. However, some of the most common methods for migrating data from on-premises databases to Azure include:
Azure Data Factory: Azure Data Factory is a cloud-based data integration service that can be used to copy data from an on-premises database to Azure. This method provides a simple and efficient way to move data to Azure, and supports various data sources and formats.
Azure Database Migration Service: Azure Database Migration Service is a fully managed service that simplifies and automates the process of moving on-premises databases to Azure. This service supports various database platforms, including SQL Server, Oracle, and MySQL, and provides a simple and efficient way to move large amounts of data to Azure.
Backup and Restore: You can also use backup and restore to move your on-premises database to Azure. This method involves taking a backup of your on-premises database and restoring it to a database in Azure. This method provides a simple and reliable way to move your data to Azure, but may require additional effort to manage the backup and restore process.
BCP (Bulk Copy Program): BCP is a command-line tool that is used to import or export large amounts of data to or from a SQL Server database. This method can be used to move data from an on-premises SQL Server database to an Azure SQL database.
Azure Arc: Azure Arc is a new service that allows you to manage resources running on-premises, in other clouds, or at the edge, from a single control plane in Azure. You can use Azure Arc to move information from an on-premises database to an Azure database, by first deploying the database on-premises and then migrating it to Azure.
Each of these methods has its own pros and cons, and the best method for your migration will depend on your specific requirements and constraints. You should carefully consider the data volumes, frequency of updates, complexity of the data, and other requirements when choosing a migration method.

 9+ registered
9+ registered 

