Do you think IIT Guwahati certified course can help you in your career?
Introduction
The B+ Tree is a type of balanced binary search tree. It uses multilevel indexing, with leaf nodes holding actual data references. An important feature is that all leaf nodes in a B+ tree are kept at the same height.
Search is made efficient as the leaf nodes in a B+ Tree are linked in the form of singly-linked lists. You can see the difference between B trees and B+ tree structures, respectively, where records in the latter are stored as linked lists.
B+ Trees in DBMS store a huge amount of data that cannot be stored in the limited main memory. The leaf nodes are stored in secondary memory, while only the internal nodes are stored in the main memory. This is called multilevel indexing.
B++ Trees are a type of self-balancing tree data structure that are used to store and retrieve large amounts of data efficiently. They are similar to B-Trees, but with some additional features that make them better suited for use in Database systems. B++ Trees maintain a separate leaf node structure that is connected by a linked list, which allows for efficient range queries and sequential access to data. Additionally, B++ Trees have a higher fanout than B-trees.
A B+ tree is a self-balancing tree data structure primarily used in database and file systems. It provides an efficient way to store and retrieve data by maintaining balance across its nodes. B+ trees are an enhancement of B-trees, a balanced tree structure, but with a few distinct features that make them particularly well-suited for disk-based storage systems.
Here’s why B+ trees are commonly used:
Efficient Range Queries: Unlike binary search trees, B+ trees store all keys in leaf nodes in a sorted manner. Leaf nodes are linked, allowing sequential access, which makes range queries efficient (e.g., retrieving all entries in a certain range).
Fast Access to Disk-Based Storage: Since B+ trees minimize the depth of the tree, they reduce the number of disk I/O operations required to access data. Non-leaf nodes only contain keys (not actual records), which allows more keys to be stored per node, minimizing disk reads and reducing the search time.
Improved Memory Utilization: B+ trees use a large branching factor, which minimizes the height of the tree and enables more efficient use of memory, allowing them to store more data without increasing the tree’s depth significantly.
Balanced Structure: Like other balanced trees, B+ trees keep all leaf nodes at the same depth, ensuring uniform data retrieval times. This balance is maintained automatically with insertions and deletions.
High Insertion and Deletion Efficiency: In B+ trees, insertions and deletions require minimal reorganization, and since keys are sorted only in the leaf nodes, only those nodes (and sometimes their parents) need to be adjusted when the structure changes.
Implementation of B+ Tree in DBMS
In DBMS, a B+ tree is used for indexing large datasets. The key concepts involved in a B+ tree implementation include nodes, branching factor, and balancing mechanisms. Here’s an overview of how a B+ tree works in a DBMS context:
Nodes and Order:
A B+ tree has a defined order, which dictates the maximum number of children a node can have. For instance, an order-4 B+ tree allows a maximum of 4 children per node.
Internal nodes (non-leaf nodes) contain only keys for navigation, while leaf nodes contain actual data records or pointers to the records.
Insertion:
Inserting a new key follows a search for the appropriate leaf node. If the leaf node has space, the new key is added.
If the node is full, it splits, promoting the middle key to the parent node and creating a new leaf. This process continues up the tree as necessary, ensuring balance.
Deletion:
When a key is deleted, it’s removed from the leaf node. If this causes underflow (fewer keys than the minimum), neighboring nodes may lend keys. If that’s not possible, nodes may merge, and balancing continues up the tree if needed.
Range Queries:
Since all data records are stored in sorted order at the leaf level and leaf nodes are linked, range queries can be done quickly by traversing through the leaf nodes, making it very efficient.
Splitting and Merging:
Splits and merges happen as part of maintaining balance. Splitting involves dividing a full node and pushing one key up to maintain order. Merging occurs when nodes have too few keys, keeping the tree balanced without redundancy.
Search Operation:
Searching in a B+ tree involves traversing from the root to the leaf level, following keys in the internal nodes. Since B+ trees are balanced and have a shallow depth, this search process is efficient.
Properties of B+ Tree in DBMS
A B+ tree is a type of self-balancing search tree data structure that maintains sorted data and allows searches, insertions, and deletions in logarithmic time. Here are some key properties of B+ trees:
Balanced Structure: B+ trees are self-balancing, meaning that after every insertion or deletion operation, the tree automatically reorganizes itself to maintain balance. The balance ensures that the depth of the tree remains logarithmic, leading to efficient search, insert, and delete operations.
Node Structure: The tree is composed of nodes, where each node represents a range or interval of keys. Internal nodes contain pointers to child nodes and key values that act as separators for the ranges represented by their children. Leaf nodes store actual data and are linked together to support range queries efficiently.
Keys and Values: Each internal node has a set of keys that act as separators for the ranges represented by its child nodes. Leaf nodes store key-value pairs, and keys in leaf nodes are usually sorted.
Order of the Tree: The order of a B+ tree is a parameter that determines the maximum number of children a node can have. In a B+ tree of order m, an internal node can have at most m-1 keys and m children, and a leaf node can have at most m-1 key-value pairs. Higher-order trees generally lead to shallower trees but may require more memory.
Structure of B+ Tree in DBMS
Before we study the structure of B+ Trees, there are a few terms we need to understand:
Indexes
They are references to actual records in a database. Indexing helps the database search any given key in correspondence to the tree.
Leaf nodes
The leaf nodes or leaves are the bottommost nodes marking the end of a tree. We must note that all the leaf nodes are on the same level.
Depth of tree
It refers to the number of levels of nodes from the root to the leaves. The depth of a tree keeps increasing as more and more elements are added to the tree.
Order of B+ tree
This is the maximum number of keys in a record in a B+ Tree.
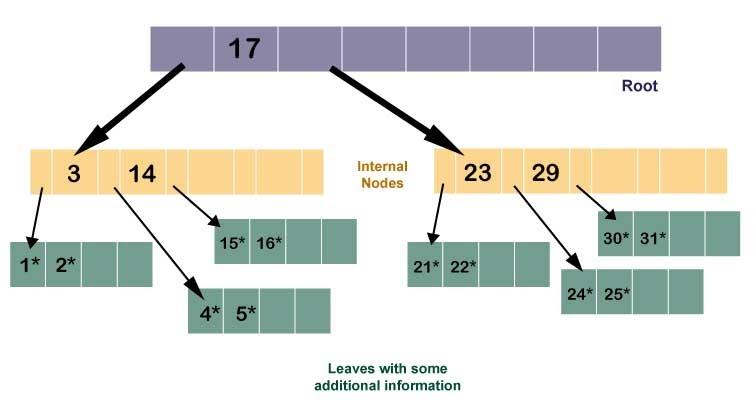
All the leaves are the same depth. All leaves in this tree are depth 2, assuming the root is at depth 0. A B+ tree is also a search tree, but in a binary search tree, there is only one search key and two child pointers at each node. On the other hand, in a B+ tree with order ‘d’, there are between ‘d’ and 2*d keys (meaning between 2 and 4 keys in our example tree) at each node (except probably the root). There are between d+1 and 2(d+1) child pointers.
Now in our B+ tree of order 2, the yellow internal nodes have between 2-4 keys; they each have at least a minimum of two. Each of the leaves in green has between 2-4 keys, the key values of which are shown with an asterisk (to indicate other information associated with a search key). There are pointers at the leaves, which point to the additional information associated with keys.
Searching a record in a B+ tree involves the following steps:
Start at the root node of the tree.
Compare the search key with the keys in the current node.
If the search key is less than the smallest key in the node, follow the leftmost pointer to the child node.
If the search key is greater than or equal to the largest key in the node, follow the rightmost pointer to the child node.
If the search key is between two keys in the node, follow the pointer to the child node corresponding to the key that is just greater than the search key.
Repeat steps 2-5 until a leaf node is reached.
Search for the record in the leaf node using the search key to locate the corresponding entry.
If the record is found, return it. If not, return a "record not found" message.
Because B+ trees are balanced and all leaf nodes are at the same level, the search time is O(log n), where n is the number of records in the tree.
Let's take an example.
Assume we have the following B+ tree, where each node can hold up to 3 keys:
To search for a record with a key of 45, we would start at the root node, which contains the keys 23, 34, and 45. Because 45 is greater than or equal to the smallest key in the node (23) and less than the largest key in the node (45), we would follow the middle pointer to the second child node.
In the second child node, we would find the key value of 45 in the leaf node. We would then use this key to locate the corresponding record in the leaf node and return the record to the user. If the key value was not found, we would return a "record not found" message.
Operations on B+ Tree in DBMS
Insertion in B+ Tree
Inserting a record in a B+ tree involves the following steps:
Search the tree to determine the appropriate leaf node for the new record.
If the leaf node has room for the new record (i.e., it has fewer than m-1 records, where m is the order of the tree), insert the new record in the correct position and update the pointers as necessary.
If the leaf node is full, split the node into two halves and promote the median key to the parent node.
Repeat step 2 for the appropriate leaf node in the new subtree.
Here's an example of inserting a record with a key value of 30 in a B+ tree with an order of 3:
Search the tree to determine the appropriate leaf node for the new record. In this case, the appropriate leaf node is the one that contains the key values 20 and 30.
Because the leaf node has room for the new record, we can simply insert it in the correct position:
If the leaf node were full, we would split it into two halves and promote the median key to the parent node.
We would then update the pointers in the parent node to reflect the new child nodes. If the parent node were full, we would repeat the split process until the tree was balanced.
Deletion in B+ Tree
Deleting a record from a B+ tree involves the following steps:
Search the tree to find the leaf node containing the record to be deleted.
Delete the record from the leaf node.
If the leaf node has more than the minimum number of records (i.e., at least ceil((m-1)/2) records, where m is the order of the tree), we are done.
If the leaf node has fewer than the minimum number of records, try to redistribute records from neighboring nodes. If redistribution is not possible, merge the node with a neighboring node.
Update the parent node keys and pointers as necessary.
Here's an example of deleting a record with a key value of 20 from a B+ tree with an order of 3:
Search the tree to find the leaf node containing the record to be deleted. In this case, the leaf node is the one that contains the key values 20 and 30.
Delete the record from the leaf node:
Because the leaf node has more than the minimum number of records, we are done.
If the leaf node had fewer than the minimum number of records, we would try to redistribute records from neighboring nodes. If redistribution was not possible, we would merge the node with a neighboring node. For example, if the node containing the key values 10 and 30 had been deleted instead, we would have to redistribute or
We would then update the parent node keys and pointers as necessary.
Properties of B+ Tree
B+ tree is a specialized Data Structure used for indexing and searching large amounts of data. Here are the key properties of a B+ tree:
All keys are stored in the leaves, and each leaf node is linked to its neighbouring nodes.
Non-leaf nodes contain only keys and pointers to child nodes.
Each node (except for the root) has at least ceil(m/2) keys, where m is the order of the tree.
All leaf nodes are at the same level, which ensures efficient range queries.
Each node (except for the root) has at least ceil(m/2) child pointers.
The root node may have fewer keys and child pointers than other nodes.
The tree is balanced, which means that the path from the root to any leaf node has the same length.
To understand B+ Trees better, we first need to understand multilevel indexing in more detail.
By now, we have learned how B+ Trees make a very convenient option for database users. Some of the advantages are listed right below:
The height of B+ Trees is balanced as compared to the B-Trees.
Keys are used for indexing in B+ Trees .
Users can access the data in B+ Trees directly and sequentially.
Since the data is stored only in leaf nodes, search queries are much faster.
Disadvantages of B+ Trees in DBMS
The following are some disadvantages of B+ trees:-
Increased complexity in insertion and deletion operations
Higher overhead in terms of memory usage
Slower tree traversal compared to binary trees
Less cache-friendly due to wide nodes
Application of B+ Trees
The applications of B+ trees are:
Database Indexing: B+ trees are widely used in database management systems for indexing. They provide efficient retrieval of records based on the values of the indexed columns.
File Systems: B+ trees are employed in file systems to organize and manage large amounts of data efficiently. They help in quick retrieval of file blocks and support sequential access.
Information Retrieval: B+ trees are used in information retrieval systems, such as search engines, to index and quickly locate relevant documents based on keywords.
Geographic Information Systems (GIS): GIS applications use B+ trees to index spatial data efficiently, facilitating spatial queries and range searches.
DNS Servers: Domain Name System (DNS) servers often use B+ trees to store and manage domain names, enabling fast lookups and updates.
File Databases: B+ trees are utilized in file databases, where they help organize and manage large volumes of data with efficient search and retrieval operations.
Caching Mechanisms: B+ trees can be employed in caching mechanisms to efficiently store and retrieve frequently accessed data, improving overall system performance.
Memory Management: B+ trees are used in memory management systems to efficiently organize and locate data in virtual memory.
Practice Problems on B+ Tree
The practice problems on B+ tree are:
Insertion Operation: Given a B+ tree of a certain order, practice inserting key-value pairs into the tree. Perform the necessary split operations to maintain the balance.
Deletion Operation: Practice deleting keys from a B+ tree. Perform the necessary merge and redistribution operations to ensure the tree remains balanced.
Search Operation: Given a B+ tree and a set of keys, practice performing search operations to locate specific keys within the tree.
Range Queries: Create a B+ tree and practice performing range queries. Identify and retrieve all key-value pairs within a specified range.
Sequential Access: Design a B+ tree and simulate sequential access operations. Traverse the tree in a way that efficiently retrieves keys in sorted order.
Duplicate Keys: Modify a B+ tree to handle duplicate keys. Practice inserting, deleting, and searching for key-value pairs with the same key.
Frequently Asked Questions
What is the B+ tree in database index?
In a database index, the B+ tree organizes and optimizes data retrieval. It's a self-balancing tree structure with keys only in the leaf nodes, facilitating efficient range queries and sequential access.
What is a key in a B+ tree?
In a B+ tree, a key is a unique identifier associated with each data entry or record. These keys are used to organize and store data in the tree's internal nodes and leaf nodes. The keys are typically sorted in ascending order to facilitate efficient searching and retrieval operations.
Why is B+ tree faster?
B+ trees are faster due to their balanced structure and optimized node splitting and merging operations. With each node containing multiple keys and pointers, B+ trees reduce disk I/O operations by storing more data per node, resulting in fewer disk accesses and faster search, insertion, and deletion operations.
Is the B+ tree balanced?
Yes, a B+ tree is balanced, as all leaf nodes are at the same depth, ensuring consistent access times for searches, insertions, and deletions.
What is B+ tree used for?
B+ trees are commonly used in databases and file systems. They excel in indexing, supporting efficient search, insertions, deletions, and range queries.
Conclusion
In this article, we learned about B+ trees in DBMS, their structure and working compared to B trees, and their advantages in a database. We also used examples to understand the concept better and learn to implement our knowledge of the same.






























 9+ registered
9+ registered 

