Do you think IIT Guwahati certified course can help you in your career?
Introduction
Welcome Ninjas. This blog will look into a commonly used concept of Natural Language Processing, NLP, i.e., Bag Of Words. But before directly jumping to the primary concern of the blog, let us get started with what NLP is.
Just as the name suggests, it processes the natural language, the Natural language of whom? Of Human beings. It refers to the ability and capability of computers to understand human language, spoken or written. NLP combines computational linguistics with ML, deep learning, and statistical learning models.
Introduction to Bag of Words Model
Bag of Words is a technique of text modeling based on NLP (natural language processing). It is used widely for feature extraction with text data.
This technique summarizes the frequency of words (Term Frequency) within a document and the word counts. We will further learn about the limitations of Bag Of Words in the blog. One of them is that any information regarding the order of words is not considered.
Modeling with Bag-of-Words
Without preprocessing
Let's first implement a bag of words withoutPreprocessing. Take a look at the following example:
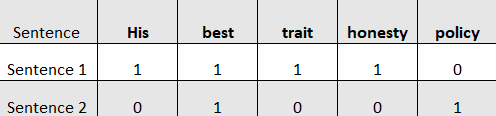
Sentence 1: His best trait is honesty
Sentence 2: Honesty is the best policy
As we are not doing any preprocessing, we would consider the stop words and the case of the letters. So, in this case 'honesty' and 'Honesty' are two different words.
First, we list of all the words available in both sentences.
His
best
trait
is
honesty
Honesty
the
policy
Now, we count the frequencies of words in each sentence,
Hence, for sentence 1=[1,1,1,1,1,0,0,0]
And for sentence 2=[0,1,0,1,0,1,1,1]
With Preprocessing
We first convert all the words to lowercase and remove the stopwords, if any. After that, sentence 1 and sentence 2 become:
Sentence 1: his best trait honesty
Sentence 2: honesty best policy
As we can see, now the vocabulary has only five words. Now, we do the scoring as we did before.
Hence, for sentence 1=[1,1,1,1,0]
And for sentence 2=[0,1,0,0,1]
Out of the above two approaches, we use the latter one in the Bag of Words model, as in machine learning, we might have large datasets, and it is challenging to interpret without preprocessing.
Implementation in Python
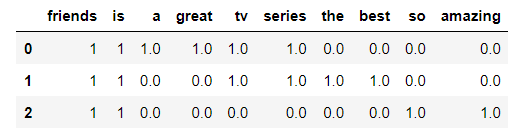
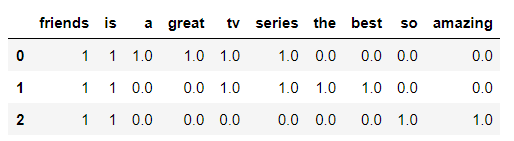
Let's analyze the reviews of the series 'Friends'.
Review 1= 'Friends is a great tv series!'
Review 2= 'Friends is the best tv series!'
Review 3=' Friends is so amazing!'
For implementing in Python, first, we import the required libraries:
import pandas as pd
import numpy as np
import collections
import re
You can also try this code with Online Python Compiler
To compare the results obtained, we use Scikit-learn's CountVectorizer, firstly, instantiate a CountVectorizer object. Then, we return the document-term matrix representing the frequency of each word in the document.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform([d1,d2,d3])
print(vectorizer.get_feature_names())
df_bow_sklearn = pd.DataFrame(X.toarray(),columns=vectorizer.get_feature_names())
df_bow_sklearn.head()
You can also try this code with Online Python Compiler
Although, the Bag of words model is very simple and easy to implement but also offers flexibility in customizing the text data to a large level. But, it still faces some drawbacks:-
The Bag of Words method for large documents will form vectors of large dimensions and might contain null values.
Most of the time, the Bag of words fails to make sense of the data; for example, the two sentences: "I like vanilla and hate chocolate" and "I like chocolate and hate vanilla" contain the exact words but have different meanings. Bag of Words will lead to similar vectorized representations.
Frequently Asked Questions
What do you mean by the Term Frequency?
Term Frequency (TF) measures the frequency of a term as it appears in a document.
What do you mean by the term Inverse Document Frequency?
Inverse Document Frequency (IDF) measures the importance of a term.
Is it important to calculate the IDF Value?
Yes, it’s important to calculate the IDF value because TF does not provide enough information to understand the importance of words.
Conclusion
We hope this blog successfully helped you understand the concept of Bag of Words in Natural Language Processing and how it can be implemented easily in Python.
If you found this blog interesting and insightful, refer to similar blogs:




































 9+ registered
9+ registered 

