Do you think IIT Guwahati certified course can help you in your career?
Introduction
The tech landscape is constantly evolving, & one of the most intriguing developments in recent times is machine learning. It's a field that's not just fascinating but also immensely practical. Among its various techniques, bagging stands out as a method that significantly improves the accuracy of machine learning models.
By the end of this article, you'll grasp what bagging is, how it contrasts with other ensemble methods, & its applications. You'll also get to dive into a practical example with a code walkthrough, ensuring a comprehensive understanding of this powerful tool in machine learning.
Ensemble Learning
Ensemble learning in machine learning is like assembling a dream team. Each team member (or model, in this case) might be good on their own, but together, they can achieve much more. This technique involves combining multiple models to produce a more powerful and accurate prediction.
Imagine you're trying to solve a complex puzzle. One approach could be to rely on the expertise of a single puzzle master. But what if you combine the skills of several puzzle masters, each bringing their unique perspective and expertise? That's ensemble learning in a nutshell – a blend of multiple models, each contributing to a more accurate and robust solution.
Ensemble methods are broadly categorized into two: bagging and boosting. Bagging, short for Bootstrap Aggregating, focuses on combining multiple models to reduce variance, thus improving stability and accuracy. On the other hand, boosting works by sequentially improving the predictions by focusing on mistakes of prior models.
The beauty of ensemble learning lies in its versatility and effectiveness. It's not just about putting together different models; it's about creating a symphony where each model plays a crucial role in achieving a harmonious and accurate prediction.
Bagging vs. Boosting: Understanding the Key Differences
In the world of ensemble learning, two superheroes emerge: Bagging and Boosting. Both are powerful, but they have different strengths and approaches to tackling problems.
Bagging, which stands for Bootstrap Aggregating, is like a team working on different parts of a problem independently and then combining their solutions. In machine learning, it involves creating multiple models (like decision trees), each trained on a random subset of the training data. The magic of bagging lies in its ability to reduce overfitting, a common problem where models perform well on training data but poorly on unseen data. By averaging out the biases and variances of various models, bagging achieves a more generalized and robust prediction.
Boosting, on the other hand, is like a relay race. Each model in the sequence tries to correct the errors of the previous one, passing the baton until the final model crosses the finish line with the least errors. Starting with a weak model, boosting focuses on sequentially improving it by giving more weight to misclassified instances. This method is particularly effective in reducing bias and increasing the precision of the model.
So, what's the main difference? Bagging is parallel, with each model built independently, while boosting is sequential, with each model building upon the previous one. Bagging is about reducing variance, and boosting is about reducing bias. Together, they form the foundation of ensemble learning, each with its unique strengths and applications.
How Bagging Works
Bagging, or Bootstrap Aggregating, is a clever ensemble technique in machine learning, but how exactly does it function? Let's break it down.
Creating Subsets
Bagging starts by creating multiple subsets of the original dataset. Picture this as taking several smaller snapshots from a big picture, each snapshot capturing different parts of it. These subsets are created through a process called bootstrapping, which involves random sampling with replacement. This means some instances may appear more than once in a subset, just like how a puzzle might have similar pieces in different areas.
Building Base Models
For each subset, a separate model is trained. These models are usually of the same type, like decision trees, but they're trained independently. It's akin to having several artists paint different parts of a landscape, each with their own style and perspective.
Aggregating Outputs
Once all models are trained, their outputs are combined. For classification tasks, this typically means a majority vote system. Think of it as a council of experts, each providing their opinion, and the final decision is made based on the most common recommendation. For regression tasks, it's usually an average of all the model predictions.
Enhanced Performance
The beauty of bagging lies in its collective wisdom. By aggregating predictions from multiple models, it reduces the chances of overfitting (being too tuned to the training data) and provides a more generalized, robust solution. It's the essence of 'strength in numbers' applied to machine learning.
Bagging is particularly effective with models that have high variance. A classic example is the decision tree, which can be quite sensitive to the specifics of the training data. By using bagging with decision trees, each tree might have high variance, but the aggregate of their outputs often leads to a more stable and accurate prediction.
Describe the Bagging Technique
Bagging, as we've learned, is all about creating stronger predictive models by combining the powers of weaker ones. But what makes it truly effective? Let's explore the characteristics that define the bagging technique:
Diversity Through Randomness
The core idea of bagging is to introduce diversity into the training process. By randomly creating subsets of the original data, each model gets a slightly different view of the problem. This diversity is crucial because it ensures that the models don't just repeat each other's mistakes. Instead, they learn from different aspects of the data, leading to a more well-rounded final prediction.
Parallel Processing
One of the beauties of bagging is that each model operates independently. This means that the training process can be parallelized, making bagging a time-efficient approach. If you have multiple processors at your disposal, you can train each model on a different processor simultaneously, speeding up the overall process.
Reducing Overfitting
Models, especially complex ones like decision trees, can sometimes fit too closely to the training data, capturing noise as if it were a significant pattern. This overfitting leads to poor performance on new, unseen data. Bagging helps mitigate this by averaging out the quirks of individual models, leading to a more general and robust performance on new data.
Flexibility with Model Choice
While decision trees are a popular choice for bagging (leading to the famous Random Forest algorithm), the technique is not limited to them. You can use bagging with any model, from neural networks to logistic regression. This flexibility allows for creative applications tailored to specific problems.
Improvement of Unstable Models
Bagging is particularly effective at improving the performance of 'unstable' models. These are models where small changes in the training data can lead to large changes in predictions. By averaging out these models, bagging smooths out the fluctuations and produces a more stable and accurate prediction.
Simplicity and Effectiveness
Despite its underlying complexity, implementing bagging is relatively straightforward. Many machine learning libraries offer built-in functions to handle the process, making it accessible even for beginners.
Bagging is a technique that doesn't seek to build a single perfect model but rather combines the strengths and balances the weaknesses of multiple models. It's a testament to the idea that sometimes, a collective effort can be much more powerful than a solitary endeavor.
What are the Implementation Steps of Bagging?
Implementing bagging in a machine learning project involves several key steps. Here’s how you can go about it:
Data Preparation: First and foremost, you need a dataset. In machine learning, data is king. You divide your dataset into training and testing sets. The training set is used to train your models, while the testing set is reserved for evaluating their performance.
Bootstrapping the Dataset
This step involves creating multiple subsets from your training data. Each subset is created through bootstrapping – randomly selecting samples from the dataset with replacement. This means some samples may appear more than once in a subset, while others might not appear at all.
Training Multiple Models
For each bootstrapped subset, train a separate model. If you're using decision trees (a common choice for bagging), you'll end up with a forest of trees, each trained on slightly different data. This is where the 'ensemble' in ensemble learning comes into play – each model brings something unique to the table.
Aggregating the Predictions
Once all models are trained, it’s time to put them to the test. When you make predictions, each model gives its output. These outputs are then aggregated to give a final prediction. For classification problems, this typically involves a majority voting system; for regression problems, you would usually average the outputs.
Evaluating Model Performance
Finally, evaluate the performance of your aggregated model on the testing set. This step is crucial to understand how well your bagging approach generalizes to unseen data. It’s the moment of truth, where you find out if your ensemble of models is truly better than a single model.
Fine-Tuning
Based on the performance, you might need to go back to the drawing board. Perhaps you need more models in your ensemble, or maybe your models need to be trained on more diverse subsets. The process of machine learning is iterative, and fine-tuning is part of the journey.
In machine learning libraries like scikit-learn, much of this process is streamlined. For instance, using the RandomForestClassifier or RandomForestRegressor classes, you can implement bagging with decision trees with minimal fuss.
Application of Bagging in Real-World Scenarios
Bagging, with its unique approach of combining multiple models, finds its application in various fields. Here’s a look at some of the areas where bagging makes a significant impact:
Finance and Risk Management
In the world of finance, predicting market trends and assessing risks is crucial. Bagging techniques, especially Random Forests, are widely used for credit scoring and evaluating the risk of loan defaults. By aggregating predictions from various models, financial institutions can make more informed decisions, balancing risks and rewards.
Healthcare Diagnostics
In healthcare, accurate diagnosis can be a matter of life and death. Bagging helps in creating predictive models that analyze patient data to diagnose diseases. For instance, identifying cancerous cells or predicting the likelihood of diabetes. These models can analyze vast amounts of data, from medical histories to lab results, providing doctors with valuable insights.
Image and Speech Recognition
Bagging is also employed in enhancing the accuracy of image and speech recognition systems. In image recognition, it helps in identifying objects within an image more accurately. In speech recognition, it improves the clarity and accuracy of transcribed text, even in noisy environments.
Fraud Detection
The ability to detect fraudulent activities, especially in online transactions, is vital for businesses. Bagging algorithms are adept at identifying patterns indicative of fraud by analyzing transaction data. This helps in preempting fraudulent transactions, saving companies millions of dollars.
Customer Segmentation and Targeting
In marketing, understanding customer segments is key to targeted advertising. Bagging models assist in analyzing customer data to identify distinct groups and preferences. This enables businesses to tailor their marketing strategies, leading to more effective campaigns.
Supply Chain Optimization
In supply chain management, predicting demand and optimizing inventory are essential tasks. Bagging methods are used to forecast product demand, helping businesses maintain the right inventory levels, reducing costs, and improving efficiency.
Environmental Modeling
Bagging is used in environmental science for tasks like climate modeling and predicting weather patterns. By analyzing large datasets, these models help in understanding complex environmental interactions, aiding in better decision-making for sustainability initiatives.
Advantages and Disadvantages of Bagging
Understanding both the strengths and limitations of bagging is essential for its effective application. Here’s a balanced view:
Advantages
Reduces Overfitting
One of the most significant benefits of bagging is its ability to reduce overfitting. By averaging the predictions from multiple models, bagging smooths out the errors that a single model might make, leading to more robust and generalizable results.
Improves Model Accuracy
Bagging often leads to an improvement in model accuracy, especially in cases where the base models have high variance. The combined predictions generally provide a more accurate output than any individual model.
Parallel Processing
Since each model in bagging is built independently, the process can be parallelized. This parallel processing capability makes bagging a time-efficient technique, especially with the computational power available today.
Versatility
Bagging can be used with various types of machine learning algorithms, not just decision trees. This versatility allows it to be applied to a wide range of problems and datasets.
Stability Against Outliers
Bagging is more stable in the presence of outliers and noise. The averaging process helps in negating the effect of anomalous data points, which might significantly impact a single model.
Disadvantages
Increased Computational Cost
Although parallel processing is a boon, bagging still requires more computational resources compared to training a single model. This can be a drawback when dealing with extremely large datasets or in resource-constrained environments.
Model Interpretability
As bagging involves multiple models, the final decision-making process can be less transparent and harder to interpret compared to a single decision tree or a linear model. This can be a challenge in fields where interpretability is crucial.
Not Effective for Biased Models
If the base models are biased, bagging may not improve the predictions. Bagging works best with models that have low bias and high variance.
Data Requirement
For bagging to be effective, a sufficiently large and diverse training dataset is necessary. In cases where data is limited, the performance gains from bagging might not be substantial.
Risk of Overfitting with Small Datasets
With smaller datasets, there’s a risk that bagging might lead to overfitting, as the bootstrapped samples might not be diverse enough.
Bagging Classifier Example: Hands-On with Code
For this example, let's consider a simple classification task using the Iris dataset, a classic in machine learning, which involves classifying iris plants into three species based on features like petal and sepal length.
Step 1: Importing Libraries and Dataset
from sklearn.ensemble import BaggingClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# Load the Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
Step 2: Splitting the Dataset
# Splitting the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Step 3: Implementing the Bagging Classifier
# Creating a decision tree classifier
tree = DecisionTreeClassifier(random_state=42)
# Implementing the bagging classifier with 100 decision trees
bagging_clf = BaggingClassifier(base_estimator=tree, n_estimators=100, random_state=42)
bagging_clf.fit(X_train, y_train)
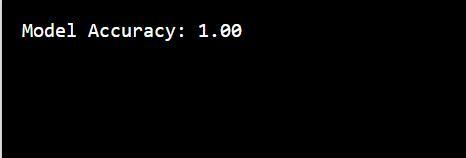
In this example, we've created a bagging classifier with 100 decision trees. Each tree is trained on a different subset of the training data. The model's accuracy is then evaluated on the test set.
This code provides a basic implementation of a bagging classifier. It showcases how bagging can be used to improve the performance of a simple decision tree classifier by combining the predictions from multiple trees.
Another Form for the Evaluation of Bagging Classifiers
Evaluating a machine learning model comprehensively involves looking beyond just accuracy. Here are some additional evaluation techniques:
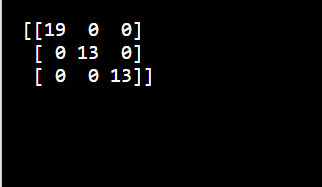
Confusion Matrix
A confusion matrix provides a detailed breakdown of predictions versus actual values. It helps in understanding the types of errors made by the classifier, such as false positives and false negatives.
Python
Python
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.datasets import load_iris
# Load the Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
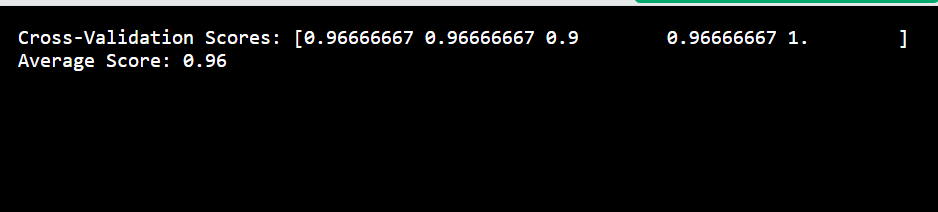
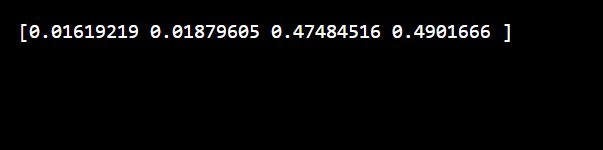
Cross-validation involves dividing the dataset into multiple parts and training the model several times, each time using a different part as the test set. This gives a more robust estimate of model performance.
Python
Python
from sklearn.model_selection import cross_val_score
scores = cross_val_score(bagging_clf, X, y, cv=5)
print(f"Cross-Validation Scores: {scores}")
print(f"Average Score: {scores.mean():.2f}")
You can also try this code with Online Python Compiler
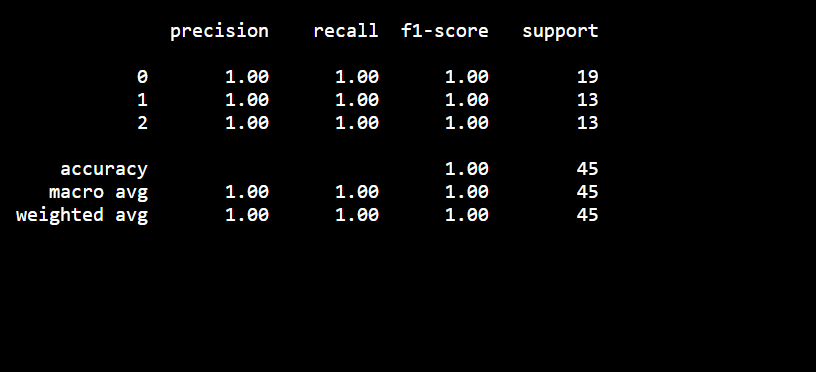
Precision measures the accuracy of positive predictions, recall measures the fraction of positives that were correctly identified, and the F1-score provides a balance between precision and recall.
Python
Python
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
# Load the Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
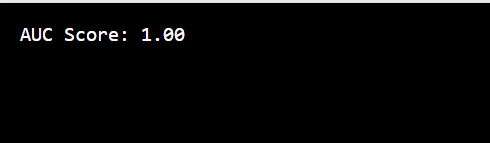
Receiver Operating Characteristic (ROC) and Area Under Curve (AUC): ROC curve and AUC are used for binary classification to evaluate the performance across different threshold settings.
Python
Python
from sklearn.metrics import roc_auc_score
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn.metrics import roc_auc_score
# Load the Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
These evaluation methods provide a holistic view of the model's performance, revealing strengths and areas for improvement. They are essential tools in a data scientist's toolkit for model assessment and refinement.
Frequently Asked Questions
What Makes Bagging Different from Other Ensemble Techniques?
Bagging stands out due to its approach of using parallel model training with bootstrapped datasets, focusing on reducing variance and overfitting. Unlike boosting, which sequentially corrects errors, bagging aggregates independent models to create a more generalized solution.
Can Bagging Be Used with Any Classifier?
Yes, bagging can be applied to most classifiers, though it's most effective with high-variance models like decision trees. The key is that the base models should be capable of capturing complex patterns in the data for bagging to enhance their performance.
Is Bagging Suitable for Small Datasets?
Bagging can be applied to small datasets, but its effectiveness might be limited. With less data, the bootstrapped samples may lack diversity, leading to models that aren't significantly different from each other. Larger datasets typically offer more room for bagging to demonstrate its strengths.
Conclusion
Throughout this article, we've journeyed through the intricate landscape of bagging in machine learning. From understanding its core principles and implementation steps to exploring its diverse applications, it's clear that bagging is a potent tool for enhancing model performance. Its ability to reduce overfitting and improve accuracy, while being flexible across various algorithms, makes it a valuable technique in a data scientist's toolkit.
































 8+ registered
8+ registered 

