Do you think IIT Guwahati certified course can help you in your career?
Introduction
Dynamic Programming (DP) is a problem-solving approach that breaks down complex problems into smaller, overlapping sub-problems, each with optimal solutions. It's commonly used for a range of problems like subset sum, knapsack, and coin change. DP can also be applied to trees for specific problem-solving.
Let us get started!
What is Dynamic Programming?
Dynamic Programming is a technique for problem-solving in which we break down complex problems into simpler subproblems. It is often used for optimization.
The basic concept of dynamic programming is storing subproblems' solutions so they can be reused (repeatedly) and this technique is called Memoization.
Memoization is much faster than recomputing them each time they are needed. This reduces the overall time complexity of the problem.
A recursive structure and the overlapping subproblems property typically identify dynamic programming problems.
Some common problems solved with the help of Dynamic Programming are:
A tree is a non-linear data structure. It consists of nodes that are placed in a hierarchical structure. The tree node at the top is called the root node. The bottommost nodes of the tree are called leaf nodes. Leaf nodes do not have child nodes.
The tree also has a node depth, defined as the number of edges from a node to the root node.
The height is defined as the maximum depth of the leaf node.
DP with Trees
Now, let’s address the primary concern of this blog - Dynamic Programming with Trees. There are many ways to utilize trees in dynamic programming.
Trees can represent the subproblems in a DP solution, with the root node representing the original problem and the leaf nodes representing the smaller subproblems. The subproblems can then be solved individually, and their results are integrated.
Trees can also be used in dynamic programming to use the tree traversal to visit the nodes of the tree in a specific order and use the values stored at each node to compute the solution to the original problem.
In general, DP with trees involves breaking down a problem into smaller subproblems that can be solved independently and using the solutions to these subproblems to solve the original problem.
Problem Statement
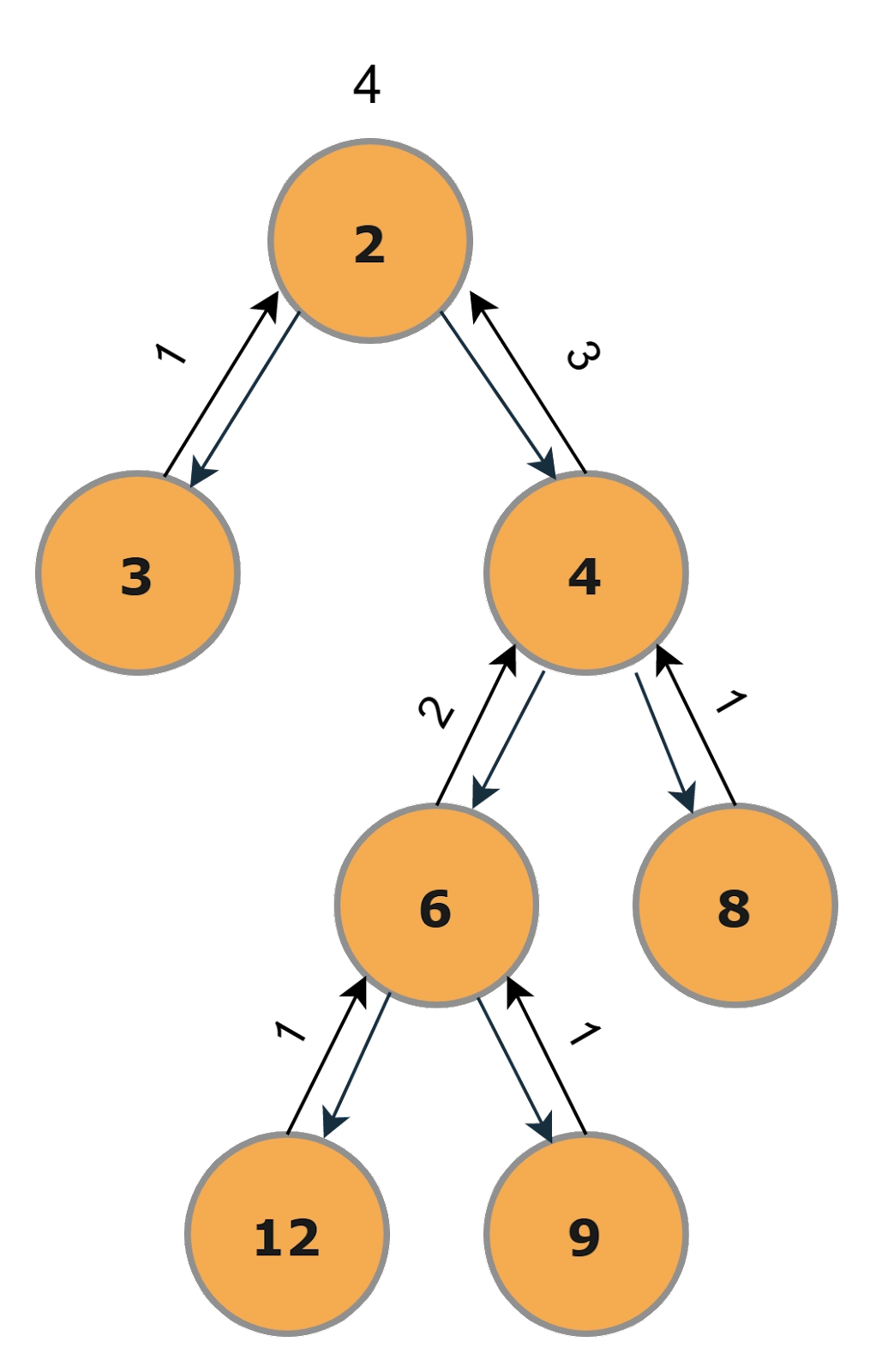
We are given a binary tree of N nodes, and our task is to find the diameter of the Binary tree. The diameter is the maximum distance between two nodes.
Let us understand the problem with the help of a sample example.
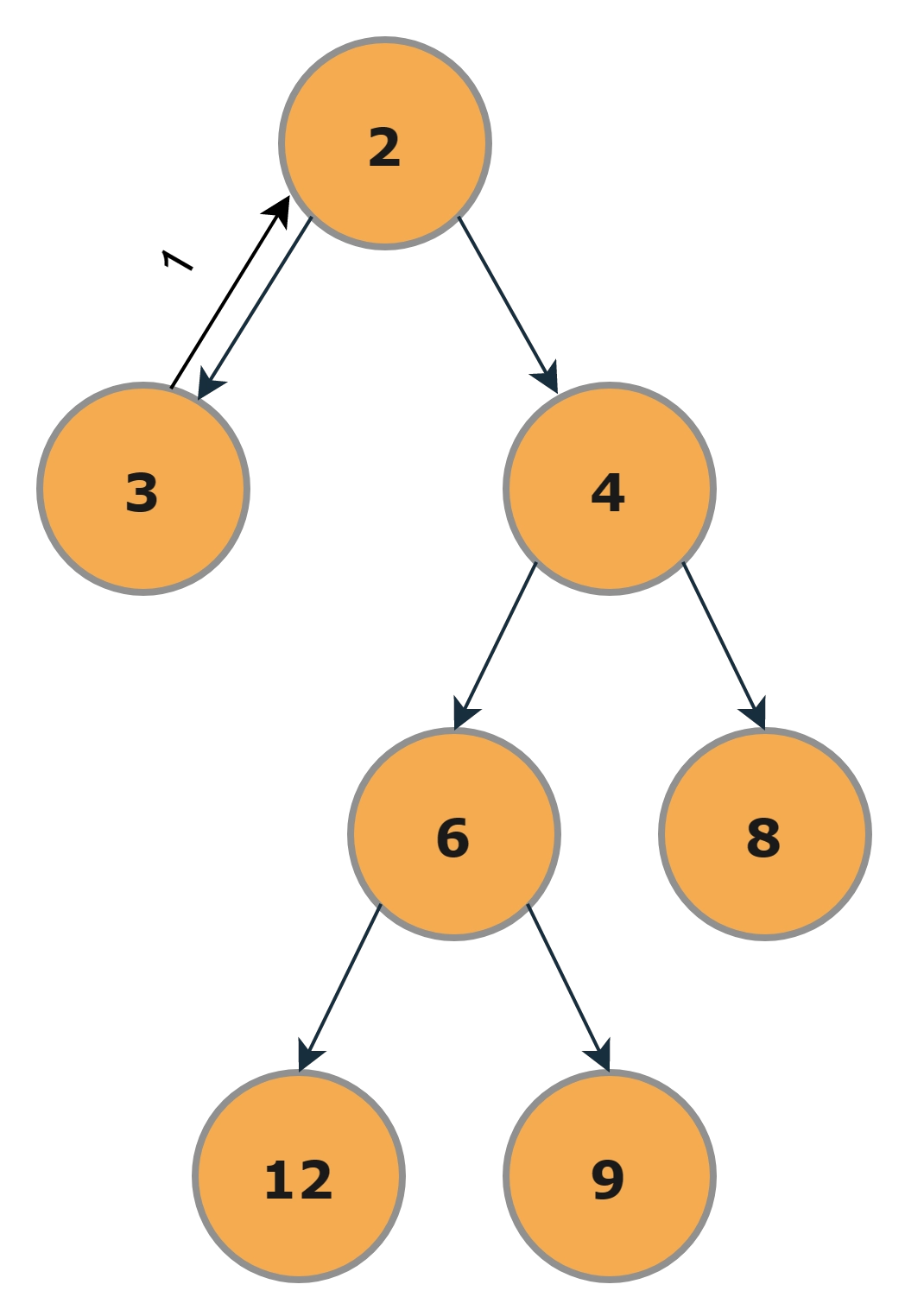
Sample Example
Input
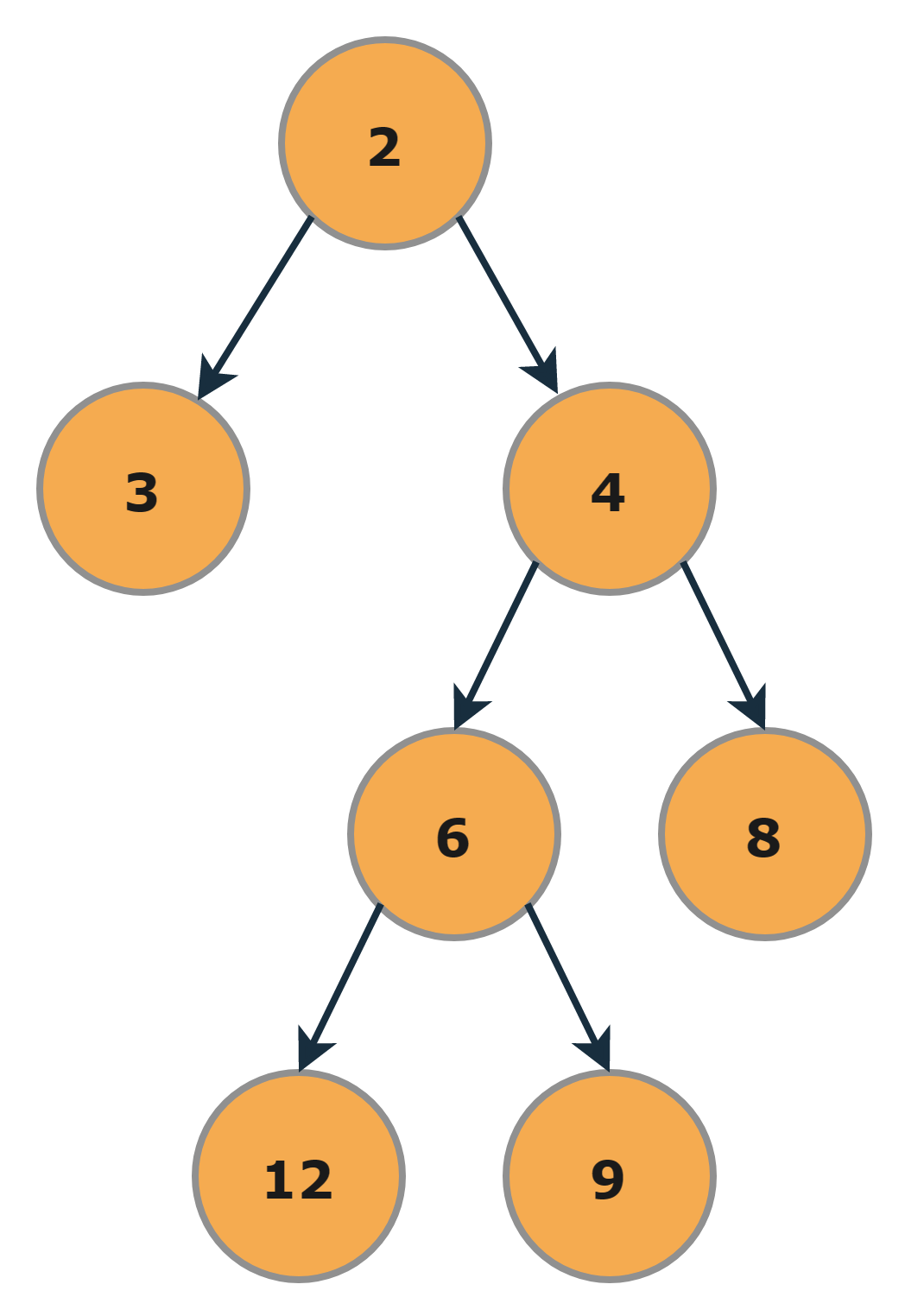
Output
OR
In the above binary tree, the tree's diameter would be 4. The path of the diameter that will yield the above result can be either 3 --> 2 --> 4 --> 6 --> 12 or 3 --> 2 --> 4 --> 6 --> 9.
Brute Force approach
The basic approach that instantly comes to mind after reading this problem statement is to find the height of every left and right subtree and simultaneously update and keep track of the max sum of the height of the left and right subtree. The time complexity of this approach would be O(N*N) since, for all the N nodes, we would have to call the height function, which will again take O(N) time to find out the max height of that particular subtree.
Implementation in C++
C++
C++
#include <iostream> #include <queue> using namespace std;
// class to represent the binary tree class TLL { public: int data; TLL *left; TLL *right;
TLL(int value) { data = value; left = right = NULL; } };
// function to find the height of a tree int height(TLL *root) { if (!root) return 0;
// finding the height of the left subtree int left = height(root->left);
// finding the height of the right subtree int right = height(root->right);
// returning the max height and including the current node return max(left, right) + 1; }
// function to find out the diameter of a tree void getDiameter(TLL *root, int &diameter) { if (!root) return;
// getting the max height of the left subtree int left_height = height(root->left);
// getting the max height of the right subtree int right_height = height(root->right);
// updating the diameter variable with the max value diameter = max(left_height + right_height, diameter);
// calling for left subtree getDiameter(root->left, diameter);
// calling for right subtree getDiameter(root->right, diameter); }
int main() { // creating a new binary tree TLL *root = new TLL(2); root->left = new TLL(3); root->right = new TLL(4); root->right->left = new TLL(6); root->right->right = new TLL(8); root->right->left->left = new TLL(12); root->right->left->right = new TLL(9);
int diameter = 0;
getDiameter(root, diameter);
cout << "The diameter of the given tree is: " << diameter << endl; }
You can also try this code with Online C++ Compiler
We are repetitively calculating the height of subtrees, and in this process, we calculate the height for the same subtree repeatedly.
But do we need to calculate the height at each step?
Or can we use some previously stored results?
So we can optimize the above approach using DP:
Instead of doing the same calculations again and again, we can take the help of DP and apply it to trees, i.e., DP on trees.
Thus instead of calling the height() function (which is used to find the height of a binary tree) every time, the primary idea behind this solution is to determine the height of the subtree within the same recursive function.
Algorithm
Let's look at the algorithm for a better understanding.
We will be doing the postorder traversal, we will process the left subtree and right subtree and in the end we will process the root.
If the root is NULL, we will return 0 from there, so this would be our base case.
Make recursive calls for left and right subtrees and store the height obtained from the trees in different variables.
After getting the max height of the left and right subtrees, update the diameter variable if (left_height + right_height > diameter).
In the end, return the maximum of left_height and right_height and add 1, because we will also include the current node.
After the recursion is terminated, print the diameter variable containing the tree's diameter.
Dry Run
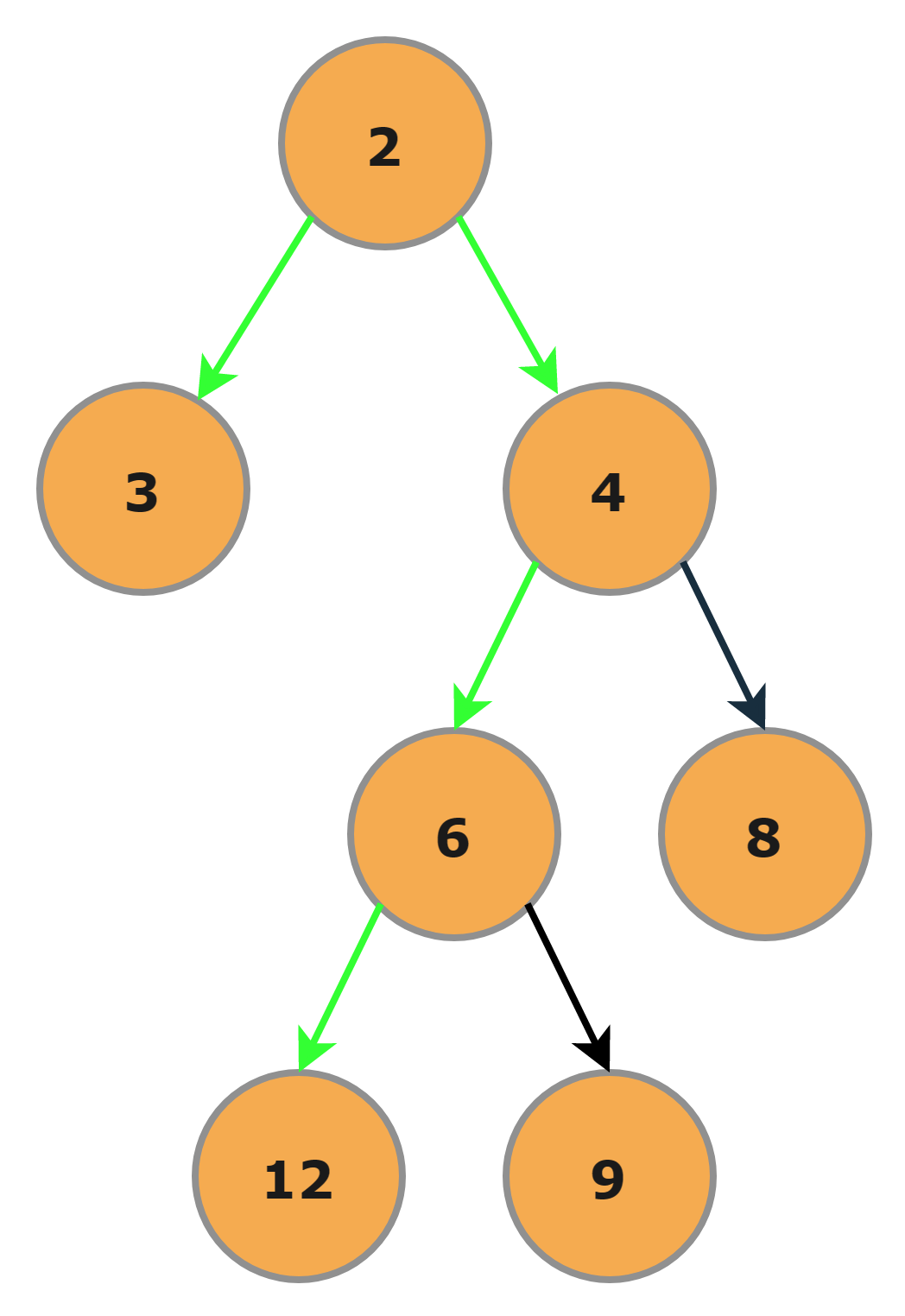
Here in the DP approach, we will be doing the Postorder traversal, i.e., we will first process the left subtree, then the right subtree, and in the end, we will process the root.
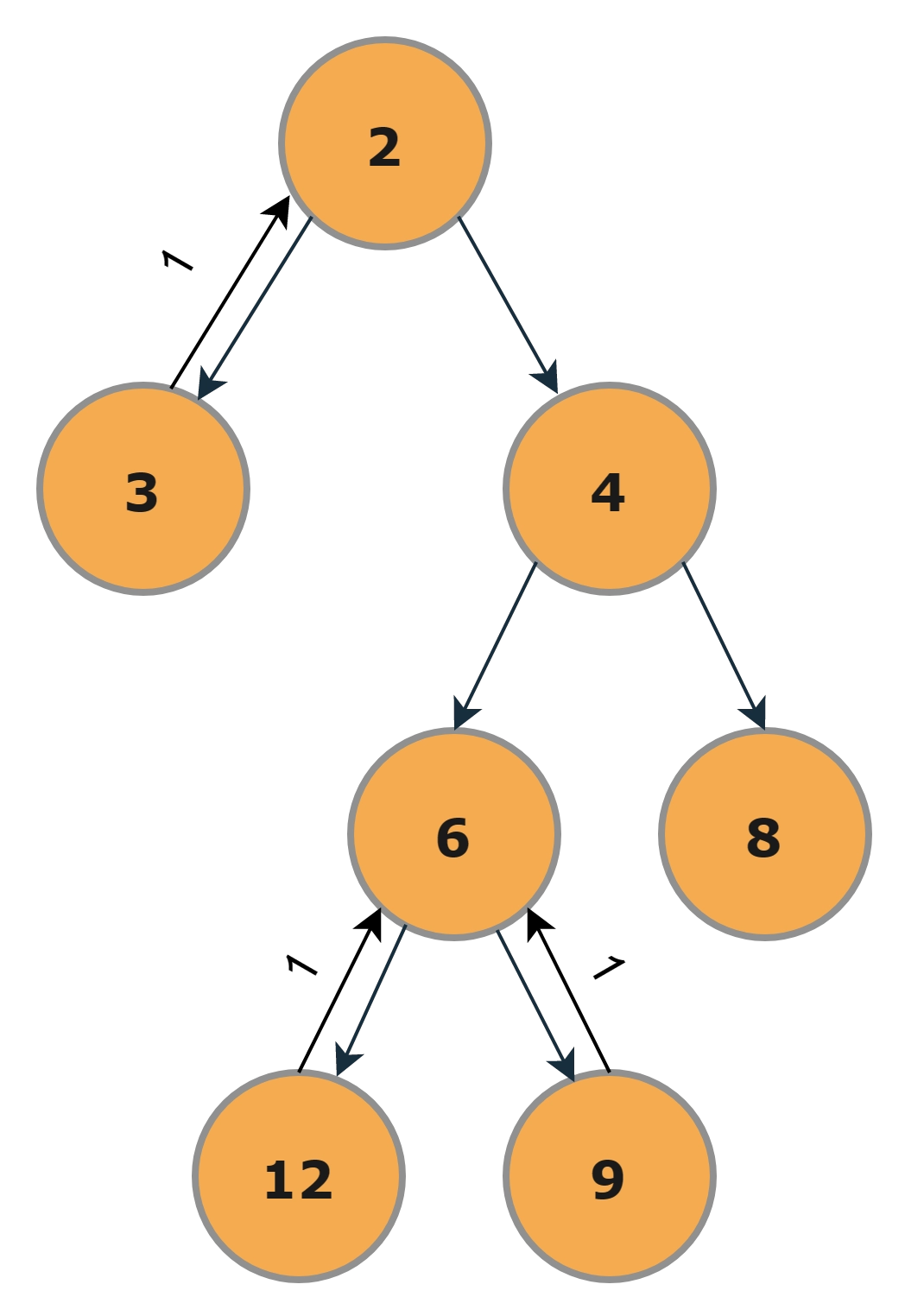
Step-1
First, processing the left subtree, which only contains a single node 3. So it will return the height as 1 because it is the leaf node.
Step-2
Now processing the right subtree, we will process the left subtree (With Root as 6) first in the right subtree, and both the children of the left subtree(With Root as 6) would return 1 since they are the leaf nodes.
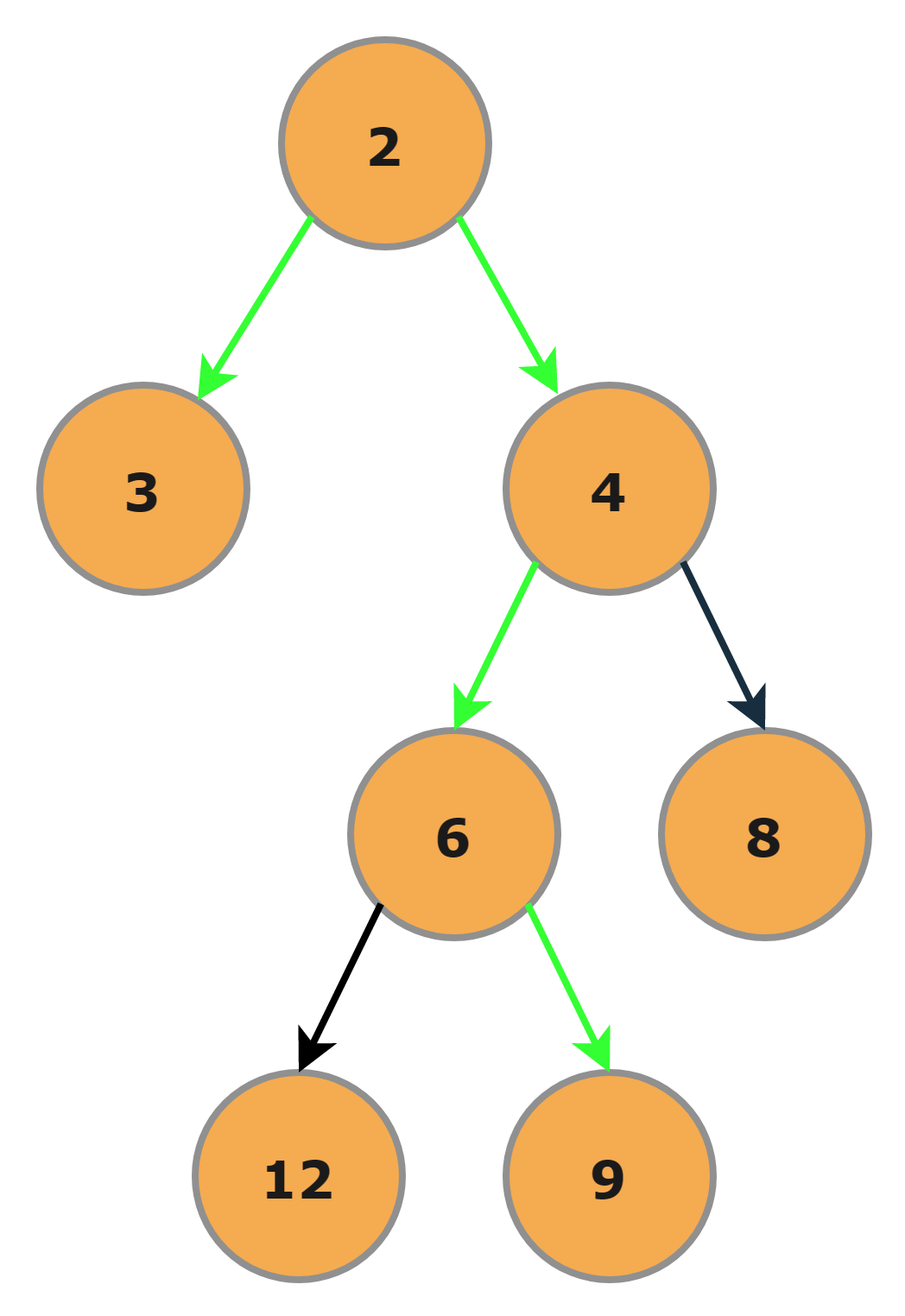
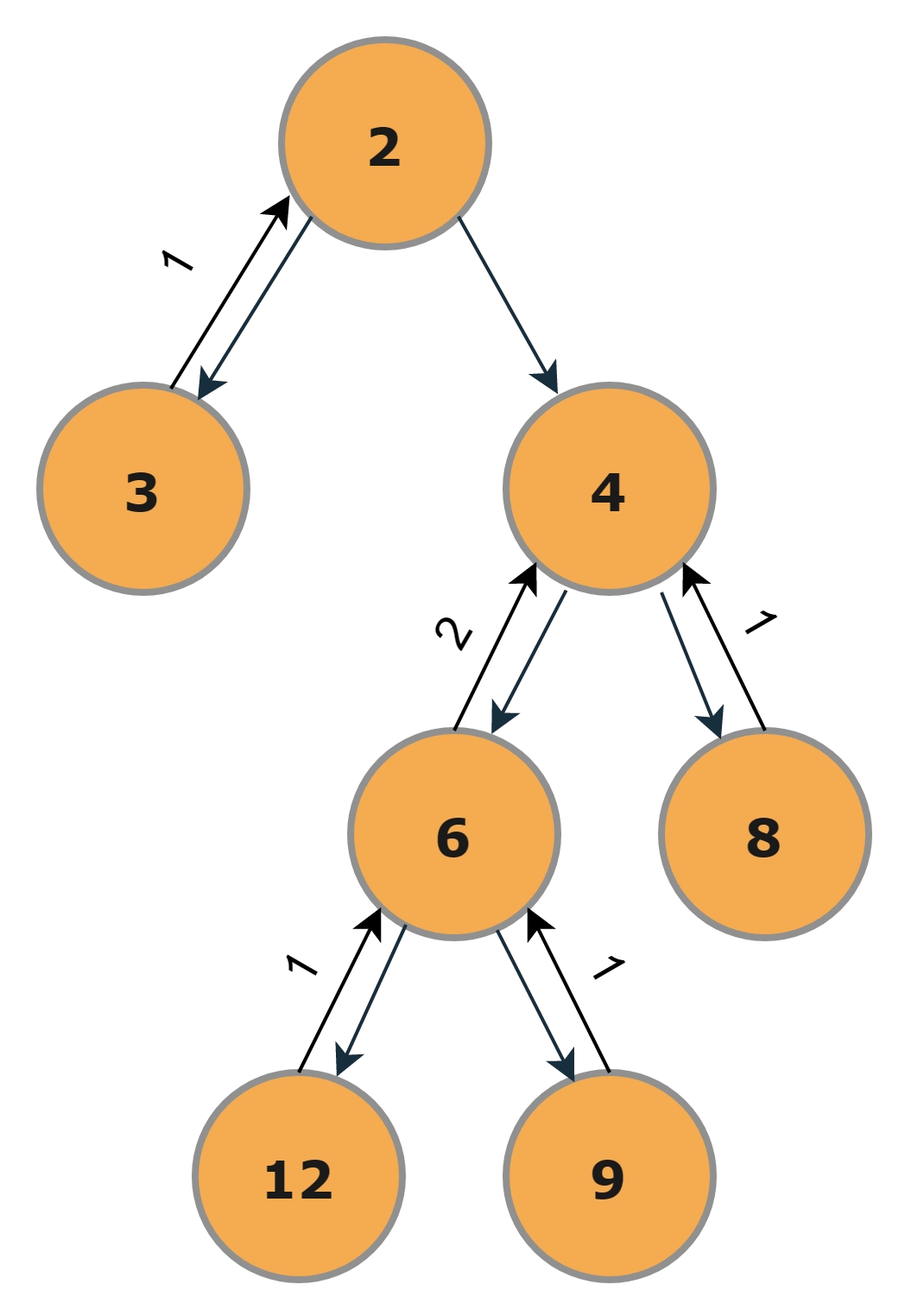
Step-3
In the right subtree, we will process both the left and right child. The left will yield 2 because it consists of one more level of nodes beneath it, and the right will yield 1 because it is the leaf node.
Step-4
Now the right subtree(With Root as 4) will be processed, and 3 will be returned as the height = (max(left_height,right_height)+1). Here left_height=2 and right_height=1.
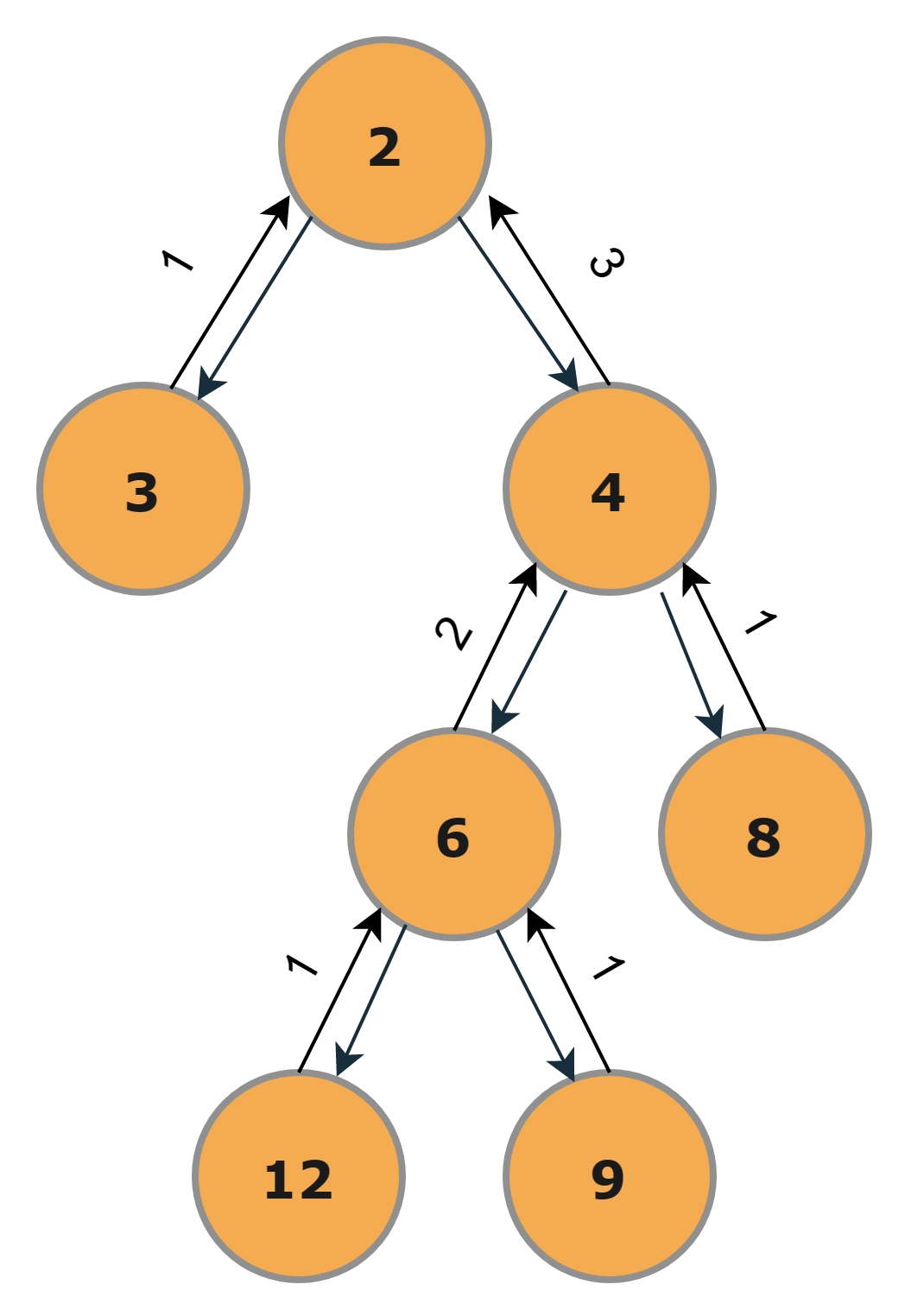
Step-5
Now the main root will be processed here, and the final answer 4 will be returned because the left_height of the root is 1 and the right_height is 3 so final will be (max(1,3)+1).
Implementation in C++
C++
C++
#include <iostream> #include <queue> using namespace std;
// class to represent the binary tree class TLL { public: int data; TLL *left; TLL *right;
TLL(int value) { data = value; left = right = NULL; } };
// function to find out the diameter of a tree int getDiameter(TLL *root, int &diameter) { if (!root) return 0;
// getting the max height of the left subtree int left_height = getDiameter(root->left, diameter);
// getting the max height of the right subtree int right_height = getDiameter(root->right, diameter);
// updating the diameter variable with the max value diameter = max(left_height + right_height, diameter);
// returning the max height of the current tree return max(left_height, right_height) + 1; }
int main() { // creating a new binary tree TLL *root = new TLL(2); root->left = new TLL(3); root->right = new TLL(4); root->right->left = new TLL(6); root->right->right = new TLL(8); root->right->left->left = new TLL(12); root->right->left->right = new TLL(9);
int diameter = 0;
getDiameter(root, diameter);
cout << "The diameter of the given tree is: " << diameter << endl; return 0; }
You can also try this code with Online C++ Compiler
// class to represent the binary tree class TLL { int data; TLL left; TLL right;
// constructor to initialize the node TLL(int value) { data = value; left = null; right = null; } }
public class Main { static int diameter = 0; // static variable to store the diameter of the tree
// function to find the diameter of the tree static int getDiameter(TLL root) { if (root == null) return 0;
// get the max height of the left subtree int leftHeight = getDiameter(root.left); // get the max height of the right subtree int rightHeight = getDiameter(root.right);
// update the diameter variable with the max value diameter = Math.max(leftHeight + rightHeight, diameter);
// return the max height of the current tree return Math.max(leftHeight, rightHeight) + 1; }
public static void main(String[] args) { // creating a new binary tree TLL root = new TLL(2); root.left = new TLL(3); root.right = new TLL(4); root.right.left = new TLL(6); root.right.right = new TLL(8); root.right.left.left = new TLL(12); root.right.left.right = new TLL(9);
getDiameter(root); System.out.println("The diameter of the given tree is: " + diameter); } }
You can also try this code with Online Java Compiler
The time complexity is O(N), here N is the number of nodes in the tree.
Since we are traversing all the tree nodes only once, which takes O(N) time, thus the overall time complexity will be O(N). Thus we have reduced the time complexity from O(N*N) to O(N) just by storing the height of every subtree and then reusing it.
Space complexity
The space complexity is O(N), here N is the number of nodes in the tree.
Since we are using recursion, in the worst case (Skewed Trees), all nodes of the given tree can be stored in the call stack. So the overall space complexity will be O(N).
DP finds applications in optimization, combinatorial, graph algorithms, and string problems.
What is the difference between DP and Divide and Conquer?
In divide and conquer, we solve the subproblems independently, and they do not depend on each other. In dynamic programming, the solution to each subproblem depends on the answers to smaller subproblems, which are interdependent.
What is the difference between a tree and a binary tree?
Both tree and binary tree are non-linear data structures, but the binary tree can have at most two child nodes, whereas a tree can have any number of nodes.
How is a binary search tree different from a heap?
A binary search tree will always have a lower value in the left node and the more excellent value in the right node. This is not the case with the heap.
How do we calculate the time complexity of dynamic programming?
The time complexity of Dynamic programming is O(k*n), k is the number of states that need to be operated, and n is the time complexity of each operation on each form.
Conclusion
In this article, we have discussed the introduction to dynamic programming (DP) on trees. Dynamic Programming (DP) on Trees provides powerful tools for solving complex problems efficiently. By applying DP techniques to tree structures, developers can streamline computations and achieve significant performance improvements. Mastering DP on trees requires problem-solving skills and creativity, empowering developers to tackle diverse challenges in computer science.































 9+ registered
9+ registered 

