


























Introduction
Batch normalization, sometimes known as Batch Norm, is currently a commonly utilized approach in the realm of Deep Learning. It improves the learning speed of Neural Networks and provides regularization, avoiding overfitting.
Batch Norm is a critical component in the current deep learning practitioner's toolkit. It was quickly acknowledged as being transformative in generating deeper neural networks that could be trained faster once introduced in the Batch Normalization study.
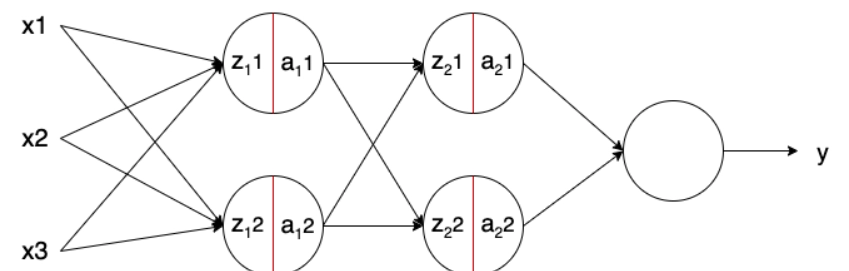
Batch Norm is a neural network layer that may currently be found in various topologies. It's frequently included as part of a Linear or Convolutional block, and it aids in network stabilization during training.
Let's start with normalization to understand better how Batch Norm works and why it's necessary.
Normalization
The term "normalization" refers to a pre-processing approach for standardizing data. Put another way, having multiple data sources inside the same range. Not normalizing the data before training can cause problems in our network, making it drastically harder to train and decreasing its learning speed.
Let's pretend we have a bike rental service. First, we want to estimate a reasonable price for each bike based on data from competitors. Each motorcycle has two characteristics: its age in years and the number of kilometers driven. These can have a wide variety of durations, ranging from 0 to 20 years, and a vast more minor range of distances driven, ranging from 0 to hundreds of thousands of kilometers. We don't want features with these disparities in ranges since the value associated with the higher range could lead our models to overvalue them.
To normalize our data, we have two options. Scaling it to a range of 0 to 1 is the easiest method:

x is the data point to normalize, m is the data set's mean, xmax is the most significant value, and xmin is the lowest. This technique is commonly employed in data inputs. In Neural Networks, non-normalized data points with broad ranges can induce instability. Significant inputs can cascade down to the layers, resulting in issues like ballooning gradients.
Another method for normalizing data is to apply the following formula to force the data points to have a mean of 0 and a standard deviation of 1:

Being x the normalized data point, m the data set's mean, and s the data set's standard deviation Each data point now has a normal distribution like a conventional normal distribution. With all of the features on this scale, none of them will be biased, allowing our models to learn more effectively.
This last technique is used in Batch Norm to normalize data batches throughout the network.

The effect of normalizing data can be seen in the image above. The original values (in blue) have been moved to the center of the graph (in red). As a result, all feature values are now on the same scale.

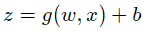




 8+ registered
8+ registered 

