BFS Algorithm
The algorithm used is similar to that of the BFS Search. The only difference is to use PriorityQueue instead of Queue to store the costs of nodes with the lowest evaluation function value.
The first is to create an empty PriorityQueue, Suppose, PriorityQueue pq;
Then Insert "element" in pq, pq.insert(element) and until the PriorityQueue is empty, we do u = PriorityQueue.DeleteMin and
Run an if-else statement where
If u is the goal, then we exit.
else
For each neighbour v of u
If v = "Unvisited"
Then Mark v = "Visited"
And do pq.insert(v)
and Mark u "Examined".
Implementation in C++
C++
#include <bits/stdc++.h>
using namespace std;
typedef pair<int, int> pi;
vector<vector<pi>> graph;
// Function to add edges to a graph
void addedge(int x, int y, int cost)
{
graph[x].push_back(make_pair(cost, y));
graph[y].push_back(make_pair(cost, x));
}
//Driver Code
int main()
{
//Number of Nodes
int v = 14;
graph.resize(v);
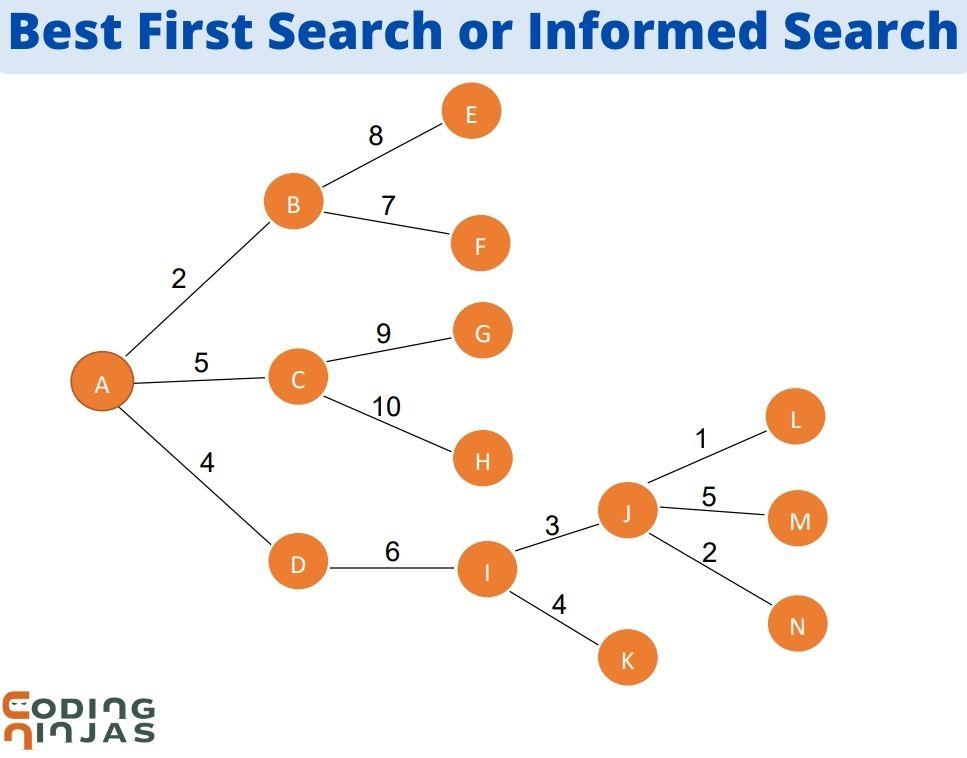
addedge(0, 1, 2);
addedge(0, 2, 5);
addedge(0, 3, 4);
addedge(1, 4, 8);
addedge(1, 5, 7);
addedge(2, 6, 9);
addedge(2, 7, 10);
addedge(3, 8, 6);
addedge(8, 9, 3);
addedge(8, 10, 4);
addedge(9, 11, 1);
addedge(9, 12, 5);
addedge(9, 13, 2);
int source = 0;
int target = 7;
int n=v;
vector<bool> visited(n, false);
// Priority Queue is sorted by the first value of the pair.
priority_queue<pi, vector<pi>, greater<pi> > pq;
pq.push(make_pair(0, source));
int s = source;
visited[s] = true;
while (!pq.empty()) {
int x = pq.top().second;
// Displaying the path having the lowest cost.
cout << x << " ";
pq.pop();
if (x == target)
break;
for (int i = 0; i < graph[x].size(); i++) {
if (!visited[graph[x][i].second]) {
visited[graph[x][i].second] = true;
pq.push(make_pair(graph[x][i].first,graph[x][i].second));
}
}
}
return 0;
}

You can also try this code with Online C++ Compiler
Output:
0 1 3 2 8 9 11 13 10 12 5 4 6 7
Implementation in Java
Java
import java.util.ArrayList;
import java.util.PriorityQueue;
class CodingNinjas
{
static ArrayList<ArrayList<edge> > adj = new ArrayList<>();
// Function for adding the edges to a graph
static class edge implements Comparable<edge>
{
int v, cost;
edge(int v, int cost)
{
this.v = v;
this.cost = cost;
}
@Override public int compareTo(edge o)
{
if (o.cost < cost) {
return 1;
}
else
return -1;
}
}
public CodingNinjas(int v)
{
for (int i = 0; i < v; i++) {
adj.add(new ArrayList<>());
}
}
//Function to apply Best- First Search
static void best_first_search(int source, int target, int v){
PriorityQueue<edge> pq = new PriorityQueue<>();
boolean visited[] = new boolean[v];
visited = true;
pq.add(new edge(source, -1));
while (!pq.isEmpty()) {
int x = pq.poll().v;
//Displaying the path having the lowest cost.
System.out.print(x + " ");
if (target == x) {
break;
}
for (edge adjacentNodeEdge : adj.get(x)) {
if (!visited[adjacentNodeEdge.v]) {
visited[adjacentNodeEdge.v] = true;
pq.add(adjacentNodeEdge);
}
}
}
}
void addedge(int u, int v, int cost)
{
adj.get(u).add(new edge(v, cost));
adj.get(v).add(new edge(u, cost));
}
// Driver Code
public static void main(String args[])
{
int v = 14;
CodingNinjas graph = new CodingNinjas(v);
graph.addedge(0, 1, 2);
graph.addedge(0, 2, 5);
graph.addedge(0, 3, 4);
graph.addedge(1, 4, 8);
graph.addedge(1, 5, 7);
graph.addedge(2, 6, 9);
graph.addedge(2, 7, 10);
graph.addedge(3, 8, 6);
graph.addedge(8, 9, 3);
graph.addedge(8, 10, 4);
graph.addedge(9, 11, 1);
graph.addedge(9, 12, 5);
graph.addedge(9, 13, 2);
int source = 0;
int target = 9;
best_first_search(source, target, v);
}
}
You can also try this code with Online Java Compiler
Output:
0 1 3 2 8 9
Complexities Analysis
Time Complexity- The worst-case time complexity is O(b^d+1), where b is the branching factor and d is the depth of a tree. In the worst case, we may have to visit all nodes before we reach the goal.
Space Complexity- The worst-case space complexity is O(b^d), where b is the branching factor and d is the depth of a tree.
Let's see some FAQs related to the Best First Search or Informed Search.
Types of Best-First Search Algorithms
There are two types of best first search algorithms:
- Greedy Best-First Search
- A* Search Algorithm
Approach 1: Greedy Best-First Search
Greedy Best-First Search expands the node that appears to be closest to the goal based solely on a heuristic function, h(n). This function estimates the distance from the current node to the goal without considering the cost it took to get there.
- Heuristic Function (h(n)): Represents an estimate of the remaining cost or distance to the goal from node n.
- Priority Queue: Nodes are stored in a priority queue, sorted by their h(n) values, with the lowest h(n) being prioritized for expansion.
Characteristics of Greedy Best-First Search:
- Non-Optimal: Greedy Best-First Search does not guarantee finding the shortest path to the goal.
- Fast but Prone to Mistakes: It focuses only on minimizing h(n), which might lead it down a non-optimal path.
C++
#include <iostream>
#include <unordered_map>
#include <vector>
#include <queue>
#include <string>
using namespace std;
// Graph representation using adjacency list
unordered_map<string, vector<string>> graph = {
{"A", {"B", "C"}},
{"B", {"D", "E"}},
{"C", {"F"}},
{"D", {}},
{"E", {"F"}},
{"F", {}}
};
// Heuristic values for each node
unordered_map<string, int> heuristic = {
{"A", 6}, {"B", 4}, {"C", 4},
{"D", 3}, {"E", 2}, {"F", 0}
};
// Greedy Best-First Search implementation
vector<string> greedyBestFirstSearch(const string& start, const string& goal) {
priority_queue<pair<int, string>, vector<pair<int, string>>, greater<>> openSet;
openSet.push({heuristic[start], start});
unordered_map<string, string> cameFrom;
cameFrom[start] = "";
while (!openSet.empty()) {
auto [_, current] = openSet.top();
openSet.pop();
if (current == goal) {
// Construct path from start to goal
vector<string> path;
for (string at = goal; !at.empty(); at = cameFrom[at])
path.push_back(at);
reverse(path.begin(), path.end());
return path;
}
for (const string& neighbor : graph[current]) {
if (cameFrom.find(neighbor) == cameFrom.end()) {
cameFrom[neighbor] = current;
openSet.push({heuristic[neighbor], neighbor});
}
}
}
return {}; // Return empty path if goal is not reachable
}
int main() {
string start = "A";
string goal = "F";
vector<string> path = greedyBestFirstSearch(start, goal);
if (!path.empty()) {
cout << "Path found: ";
for (const string& node : path)
cout << node << " ";
} else {
cout << "No path found from " << start << " to " << goal;
}
return 0;
}
You can also try this code with Online C++ Compiler
Output
Path found: A B E F
Approach 2: A* Search Algorithm
A Search* is an extension of Greedy Best-First Search that combines h(n) with another function, g(n), which represents the actual cost from the start node to the current node. A* uses a combined function f(n) = g(n) + h(n) to select the next node for expansion.
- Heuristic Function (h(n)): Estimates the remaining cost to the goal.
- Cost Function (g(n)): Represents the cost accumulated from the start node to the current node.
- Evaluation Function (f(n)): A* selects nodes by minimizing f(n) = g(n) + h(n).
Characteristics of A* Search:
- Optimal and Complete: A* guarantees the shortest path if h(n) is admissible (i.e., it never overestimates the actual cost to the goal).
- Memory Intensive: A* maintains a more extensive set of nodes in memory than Greedy Best-First Search, as it needs to track both g(n) and h(n) values.
C++
#include <iostream>
#include <unordered_map>
#include <vector>
#include <queue>
#include <string>
#include <limits>
using namespace std;
// Graph representation with costs
unordered_map<string, vector<pair<string, int>>> graph = {
{"A", {{"B", 1}, {"C", 3}}},
{"B", {{"D", 1}, {"E", 4}}},
{"C", {{"F", 2}}},
{"D", {}},
{"E", {{"F", 1}}},
{"F", {}}
};
// Heuristic values for each node
unordered_map<string, int> heuristic = {
{"A", 6}, {"B", 4}, {"C", 4},
{"D", 3}, {"E", 2}, {"F", 0}
};
// A* Search implementation
vector<string> aStarSearch(const string& start, const string& goal) {
priority_queue<pair<int, string>, vector<pair<int, string>>, greater<>> openSet;
unordered_map<string, int> gScore;
unordered_map<string, string> cameFrom;
for (const auto& node : heuristic)
gScore[node.first] = numeric_limits<int>::max();
gScore[start] = 0;
openSet.push({heuristic[start], start});
while (!openSet.empty()) {
auto [_, current] = openSet.top();
openSet.pop();
if (current == goal) {
// Construct path from start to goal
vector<string> path;
for (string at = goal; !at.empty(); at = cameFrom[at])
path.push_back(at);
reverse(path.begin(), path.end());
return path;
}
for (const auto& [neighbor, cost] : graph[current]) {
int tentative_gScore = gScore[current] + cost;
if (tentative_gScore < gScore[neighbor]) {
cameFrom[neighbor] = current;
gScore[neighbor] = tentative_gScore;
int fScore = tentative_gScore + heuristic[neighbor];
openSet.push({fScore, neighbor});
}
}
}
return {}; // Return empty path if goal is not reachable
}
int main() {
string start = "A";
string goal = "F";
vector<string> path = aStarSearch(start, goal);
if (!path.empty()) {
cout << "Path found: ";
for (const string& node : path)
cout << node << " ";
} else {
cout << "No path found from " << start << " to " << goal;
}
return 0;
}
You can also try this code with Online C++ Compiler
Output
Path found: A C F
Frequently Asked Questions
What is the Best-First Search Concept?
Best-First Search is a search algorithm that selects paths based on a heuristic function, expanding the most promising nodes first to reach the goal.
Is Best-First Search Greedy or Beam Search?
Best-First Search is typically a greedy search, focusing on the most promising path by evaluating nodes with a heuristic, without limiting to a fixed width like Beam Search.
Best First Search uses which data structure?
Priority Queue is used for the best first search as Priority Queue maintains the fringe in ascending order of f values.
What is the advantage of the best first search?
Best-first search allows us to take advantage of both algorithms. With the help of the best-first search, we can choose the most promising node at each step.
Is Informed Search Complete?
It may or may not be complete as Informed Search is also known as Heuristic Search.
Why is A * better than Best First Search?
A* achieves better performance by using heuristics to guide its search and combines the advantages of Best-first Search and Uniform Cost Search.
Conclusion
This article discusses the problem of Best First Search or Informed Search with their examples and implementation. We had also seen some FAQs related to them.
After reading about the above problem, Best First Search or Informed Search, are you not feeling excited to read/explore more articles on Data Structures and Algorithms? Don't worry; Coding Ninjas has you covered. See Graph, Binary Tree, BFS vs DFS, Check for Balanced Parentheses in an Expression, and Stack to learn.
Refer to our Guided Path on Code360 to upskill yourself in Data Structures and Algorithms, Competitive Programming, JavaScript, System Design, and many more!































 9+ registered
9+ registered 
