


























Introduction
Big Data is a thing of the present and future. It has been a long struggle for businesses to find an approach that captures and analyzes their customers, products, and services. This approach is a competitive advantage for those who know how to properly utilize Big Data.
If you are looking for a job in data testing, you must consider becoming a Data Analyst. This quick guide on Big Data Testing Interview Questions will help a lot if you prepare for an interview regarding the same in the future. This article consists of the 30 most popular Big Data Testing Interview Questions, so let’s get started without wasting any time.

Big Data Interview Questions for Freshers
1. What is Big Data?
Ans: Any data source with at least three characteristics, the 3V’s - Extremely high Volumes, Extremely high Velocity, and Extremely wide Variety of data can be considered Big Data.
Big Data should not be confused with a single technology, but it is a combination of old and new technologies. It can be said to have the capability to manage enormous amounts of data at the right speed and within the right timeframe. Thus, allowing us to perform real-time analysis.
2. Mention some prominent uses of Big Data.
Ans: Uses of Big Data:
- Targeted Ads for compelling consumers based on past purchases, search histories, and viewing histories.
- Improved and informed decision-making is something that has led to a competitive advantage for companies with excellent data management capabilities.
- Risk Management is yet another use of Big Data Analytics. New risks are identified from previous data patterns.
- Big Data Analytics also helps with product development by providing insights on development decisions and progress measurement.
- Consumer data helps companies design their marketing strategies, which can act on trends and may lead to customer satisfaction.
3. State the different approaches to dealing with Big Data.
Ans: There are two approaches as far as Big Data processing is concerned.
- Batch Processing
- Stream Processing
The business requirements, associated concerns, and the available budget decide the approach to be determined for Big Data Processing.
4. Explain in brief the five V’s of Big Data.
Ans: The five V’s of Big Data are explained below.
- Volume – Represents the amount of data.
- Velocity – The rate at which data grows.
- Variety – Refers to the different data types.
- Veracity – Refers to the uncertainty of available data.
- Value –Term used for revenue generated by data.
5. Mention the differences between Big Data Testing and Traditional Database Testing.
Ans: To look into the differences between Big Data Testing and Traditional Database Testing, refer to the table below.
Traditional Database Testing | Big Data Testing |
| The validating tool required is excel based on macros or automotive tools with UI. | There are no specific and definitive tools. |
| Tools are very simple and do not require any specialized skills. | A Big Data Tester must be trained specially, requiring continuous updates. |
| The data is structured and compact. | Big Data includes structured as well as unstructured data. |
| Methods are time-tested and properly defined. | Methods are developing and are still improving continuously. Big Data requires R&D efforts too. |
6. How do you see Big Data Testing? Name some tools for Big Data.
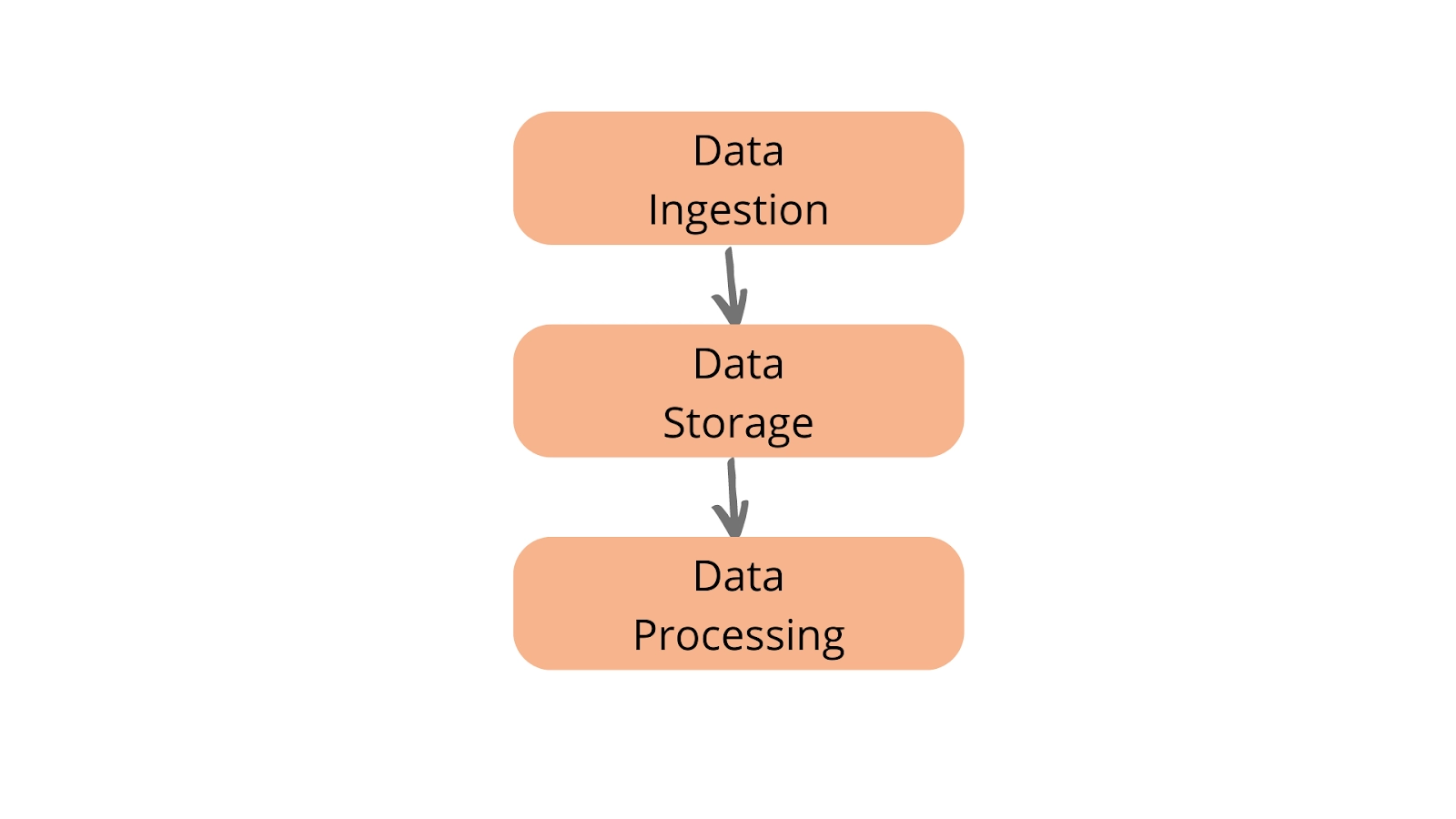
Ans: Big Data Testing includes advanced tools, specialized frameworks, and efficient methods to handle enormous amounts of datasets. Big data testing covers everything from the creation of data, storage, retrieval, and analysis to providing suggestions and feedback.
Some of the most commonly used tools for Big Data are MongoDB, MapReduce, Cassandra, Apache Hadoop, Apache Pig, Apache Spark, and many more.
7. What do you understand by the term Collaborative Filtering?
Ans: Collaborative Filtering refers to the cluster of technologies that forecast and predict which items a selected customer would like. This filtering is done depending on the preferences of the individuals.
8. What are the test parameters to be looked after while Big Data Testing?
Ans: The test parameters to be looked into while testing Big Data are listed below.
- Message Queue
- Map-Reduce
- JVM parameters
- Timeouts
- Caching
- Concurrency
- Logs
- Data Storage
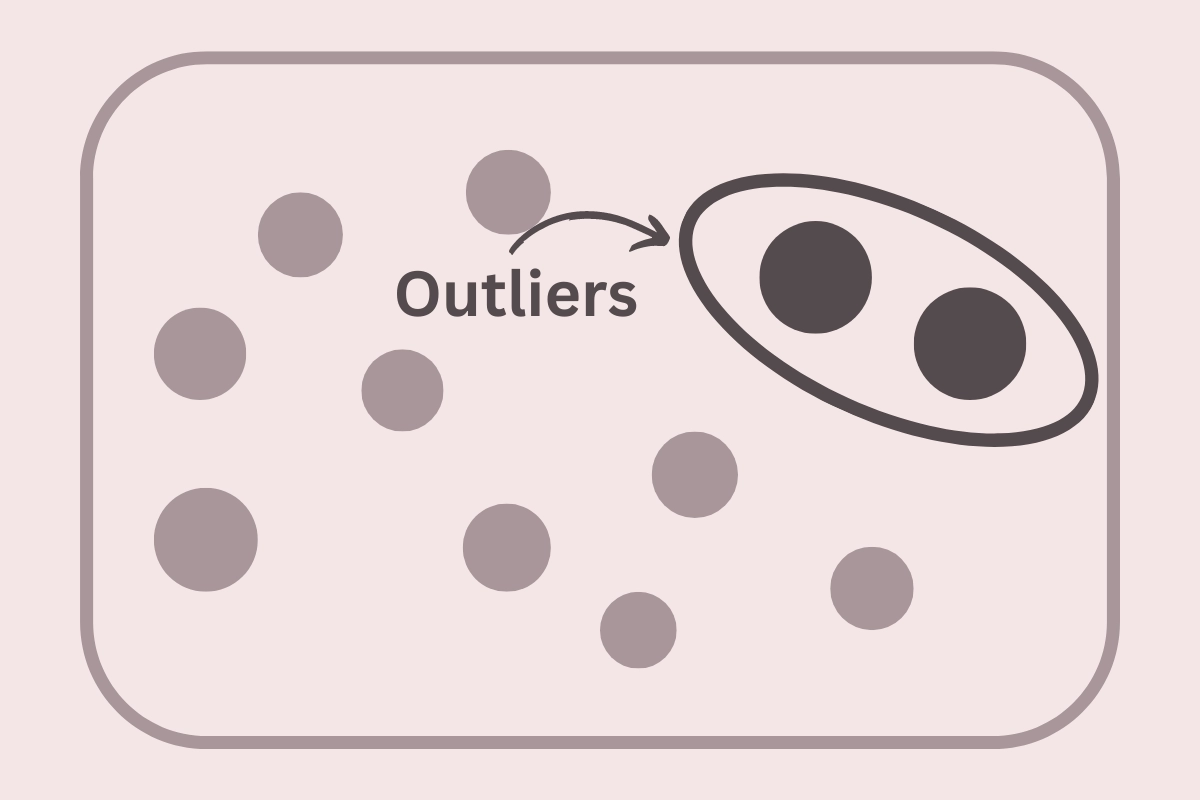
9. What is Clustering?
Ans: Grouping of similar kinds of objects into a set, known as a cluster. It is one of the essential steps in data mining. Some popular clustering methods are hierarchical, partitioning, density-based, model-based, etc.
10. How would you convert unstructured data to structured data?
Ans: There can be many ways to convert unstructured data to structured data. The two most prominent ways are mentioned below.
- Programming
Programming is the most popular method used for transforming unstructured data into a compact and structured format. You can change the data in any form using several programming languages, such as Python, Java, C++, C, etc.
- Data or Business Tools
Several Business Intelligence tools support drag-and-drop functionality that helps them convert unstructured data into structured data. The drawback is that most of these tools are paid for, and an individual has to be financially capable before using these tools.
11. State the needs of the Test Environment.
Ans: The most suitable test environment depends on the nature of the application. The various needs of the Test Environment are mentioned below.
- Appropriate space for processing, excluding a significant amount of storage space for test data.
- Efficient CPU Utilization and Minimum Memory are required for performance maximization.
- The data inside the scattered cluster.
12. How can we test the quality of data being processed?
Ans: Data quality becomes an important factor when it comes to Big Data Testing. Since the amount of data is massive, its quality must be up to the mark.
Data Quality Testing is a part of the examination of the database. It includes inspecting various factors like perfection, repetition, reliability, validity, completeness of data, etc.
13. Throw some light on the distributed cache.
Ans: Distributed Cache is a specialized service dedicated to the Hadoop MapReduce framework. It is used to cache the read-only text files, archives, and jar files whenever required. These files can be accessed and read later on each data node where the map or reduce tasks are running.
14. Define Big Data Analytics.
Ans: Big Data Analytics is gathering, Storing, Managing, and manipulating massive amounts of data at the right pace, at the right time, to gain the right insights.
It is a complex process that involves uncovering hidden patterns and helping firms to make informed decisions that result in commendable outcomes. Competitive advantage: why Big Data Analytics has gained popularity among various departments.
15. What are the challenges faced by Big Data Analysts?
Ans: Some of the challenges faced by Big Data Analyst are mentioned below.
- Much data comes in unstructured pictures, videos, etc., making it difficult for analyzers to manage.
- Creating new sources such as sensors, click-stream, smart devices, etc., now and then requires an evolution of technology, which takes time.
- A lot of data in various forms requires extremely good data quality maintenance.
- The complexity of the Big Data ecosystem leads to several security concerns that must be addressed appropriately.
- The high cost of hiring experienced data analysts and engineers and the lack of potential analytical skills in every other individual make it difficult for some firms to go with pace.


 8+ registered
8+ registered 

