Do you think IIT Guwahati certified course can help you in your career?
Introduction
Have you ever used any detection algorithm where it classifies? For example, let's think of classifying emails into “Spam” and “Not Spam”, so here we label them as Spam - 1 and Not spam-0. The most common examples of Binary Classification are Credit Card Fraud detection, Sentimental analysis. Let’s develop a simple sample model for Binary Classification to understand better.
Binary classification is the task of classifying the elements of a set into two groups on the basis of a classification rule.
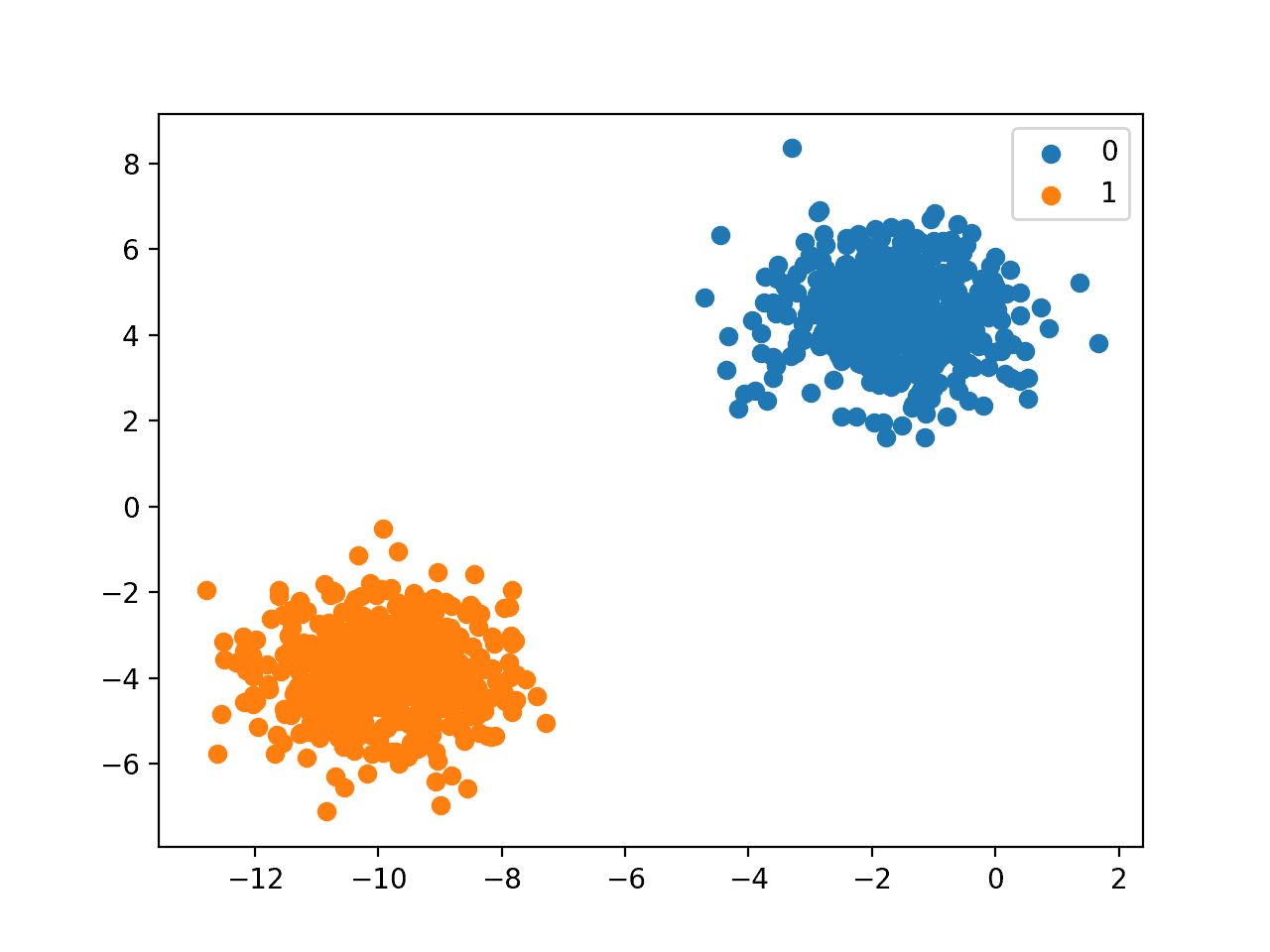
In the below graph, we have two classes ‘0’ and ‘1’, where 0→ is represented with blue and 1→ with orange color. Based on the classes a graph is plotted to differentiate two classes.
Building Binary Classifier:
The first and foremost step to build any model is to import libraries like pandas, sklearn. Keras and Tensorflow are mostly used libraries to build a model because they provide better accuracy and fewer entropy values.
from flask import Flask, render_template, request
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
You can also try this code with Online Python Compiler
So let’s take an easy example to implement a binary classification algorithm. Here we are going to consider the Spam classifier model. Here we have 87% of “Not Spam” and 13% of “Spam”.
Generally, whenever a data set is taken, it always needs to be cleaned. In terms of machine learning, we need to extract the important features from the dataset. To extract the features here we are using the CountVectorizer algorithm.
# Extract Feature With CountVectorizer
cv = CountVectorizer()
You can also try this code with Online Python Compiler
Naive Bayes classifiers are a collection of classification algorithms based on Bayes' Theorem. It is not a single algorithm but a family of algorithms where all of them share a common principle, i.e. every pair of features being classified is independent of each other.
Naive Bayes uses a similar method to predict the probability of different classes based on various attributes. This algorithm is mostly used in text classification and with problems having multiple classes.
To train the Spam Classifier we are using Naive Bayes as this is one of the best algorithms for classifying.
What do you mean by Binary Classification? Binary Classification helps to differentiate two classes by different means like plotting graphs, labeling, etc.
What is Binary text Classification? It is a supervised learning algorithm in which we try to predict whether a piece of text follows into some category.
List some Binary Classifiers? Naive Bayes, K- Nearest Neighbours, Support Vector Machine are some of the Binary Classifiers.
What is Binary Classification Data set? The goal of a binary classification problem is to create a machine learning model that makes a prediction in situations where the thing to predict can take one of just two possible values.
Key Takeaways
In this blog, we discussed
Binary Classification
Developing a Binary Classification Model
Understanding the Binary Classification Model
To learn more about Machine Learning, take this awesome course from CodingNinjas.

































 6+ registered
6+ registered 

