Do you think IIT Guwahati certified course can help you in your career?
Introduction
In today's data-driven world, we have been surrounded by vast amounts of data. Since the raw data we get contains noisy data in it. It may collect unwanted information like duplicate values, stopwords, different formatting, etc. It becomes very complex and challenging to analyze this noisy data. To solve this problem, there is a powerful technique known as Binning. Binning in Data Mining helps you to sort your data by dividing continuous variables into discrete categories or bins.
Data scientists, Business analysts, and machine learning enthusiasts use these techniques to sort their data. This article will discuss different aspects related to Binning in Data Mining.
Noise Data
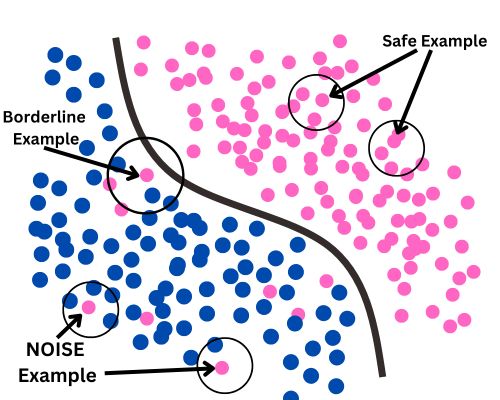
Noise data refer to irrelevant information present in the dataset. It does not carry any meaning, information, or pattern.
Noise data unnecessarily increases the storage capacity and can also cause hindrance in the result obtained. When the data is being transferred from source to destination, an implicit error can cause noise in data.
There might be some human-made mistakes while entering the data.
Noise in data can be caused because of the hardware-related issue.
There might be outliers present in the data. Outliers are the values that do not belong to the range of the majority datapoint in the dataset.
There might be some missing information or duplicate values present in the dataset that can also be considered noise.
However, there are many ways in which we can remove the noisy data. This process of eliminating noisy data is known as smoothing. There are different smoothing techniques like Binning, Regression, Outlier Analysis, and clustering. In this article, we are going to discuss what Binning is and also discuss what are different aspects related to Binning.
Binning in Data Mining
Binning in Data Mining is also known as discretization or bucketing. It is a data preprocessing technique used in data mining.The quantity of bins plays an important role in Binning in Data Mining. It is used to categorize data into discrete bins based on the range or values of data points. Binning methods use neighboring data points for smoothing them. This is called local smoothing. Binning is dividing a continuous variable into discrete categories by creating bins. There are different methods used to divide data into bins:
Equal Width Binning
Equal Width Binning is a data mining technique that divides a continuous variable into bins of equal widths or intervals. This approach aims to group data points into bins with the same range or width.
To understand this better, let's take an example of equal-width binning.
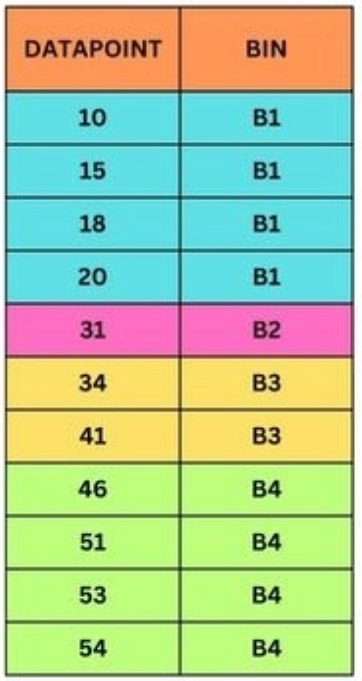
Step 1: Sort the dataset in ascending order: 10, 15, 18, 20, 31, 34, 41, 46, 51, 53, 54.
Step 2:Determine the width of each bin using the formula: w = (max-min) / N, where w is the width, max is the maximum value, min is the minimum value, and N is the number of bins.
In our example, the minimum value is 10, the maximum value is 54, and we choose four bins. So, the width (w) is calculated as (54 - 10) / 4 = 11. Now we have to add value to each bin which would be as follows:
So each bin would contain values in between their lower bound and upper bound. So the final bin for this dataset would have values like:
BIN 1 : [10, 15, 18, 20]
BIN 2 : [31]
BIN 3 : [34, 41]
BIN 4 : [46, 51, 53, 54]
Equal Width Binning is a straightforward approach in which continuous data is divided into discrete bins. It's important to consider the data's nature and the analysis's specific requirements when choosing the number of bins and applying equal-width binning.
Equal Frequency Binning
Equal Frequency Binning can be referred as Equal Depth Binning. It is a data binning technique that divides the values into bins having equal number of observations or frequency.This method's major goal is to ensure every bin has a comparable amount of data points. This helps us to present the information in a balanced manner.
Consider the following example for equal frequency binning.
First, we have to sort the data. If we have unsorted data, we need to convert it into sorted data and then apply the second step. In the second step, we have to find the frequency. To calculate the frequency, we can use the formula a total number of data points/number of bins.
In this case, the total number of data points is 12, and the number of bins required is 3. Therefore, the frequency comes out to be 4. Now let's add values into the bins.
BIN 1: 10, 15, 18, 20
BIN 2: 31, 34, 41, 46
BIN 3: 51, 53, 54, 60
This method is beneficial in the case of skewed or non-uniformed data. Equal Frequency Binning helps in representing a balanced distribution of the data points.
Data Smoothing
Data Smoothing is a preprocessing method that is used to reduce the noise from the dataset. They are applied after the binning process to simplify the data representation within the bin further. After partitioning, the developer can perform smoothing techniques like:
Smooth by bin mean - replace the noisy values in the bin with the bin mean value.
Smooth by bin median - replace the noisy values in the bin with the bin median value.
Smooth by bin boundaries- replace the noisy value in the bin with the bin boundaries value.
Outliers can also be solved with the binning technique. To detect outliers, we can use graphs or boxplots. We can also use clustering methods to identify outliers and then use smoothing techniques.
Look at the example below to understand how smoothing works in a dataset.
There is sorted data of the marks in the class of the students. We aim to categorize the students into groups and pay more attention to those who have received low marks.
Let's Consider following example, to better understand Equal Frequency Bin.
BIN 1: 4, 7, 13, 16
BIN 2: 20, 24, 27, 29
BIN 3: 31, 33, 38, 42
In this approach, the dataset is sorted and is divided into equal-frequency bins with a depth of 4. By using equal-frequency binning in this example, we have created three bins with an equal number of data points in each bin. This partitioning technique helps us in studying detailed analysis of the dataset.
Smoothing by Bin Mean Method
Let's Consider following example, to better understand Bin Mean Method.
BIN 1 : 10, 10, 10, 10 (mean: 10)
BIN 2 : 25, 25, 25, 25 (mean: 25)
BIN 3 : 36, 36, 36, 36 (mean: 36)
In this method, after smoothing, all the values are replaced with the mean value of the bin. It focuses on the average or central tendency within each bin. The smoothing by mean bin method can help in reducing the impact of the outliers or extreme values within each bin.
Smoothing by Bin Boundaries Method
Let's Consider following example, to better understand Bin Mean Method.
BIN 1: 4, 4, 16, 16 (min: 4 and max: 16)
BIN 2: 20, 20, 29, 29 (min: 20 and max: 29)
BIN 3: 31, 31, 38, 42 (min: 31 and max: 42)
In this method, after smoothing, each value is replaced with the minimum and maximum values of the bin. In this case, the values within the BIN 1 , the value 7 is near to value 4, so 7 will be replaced with the value 4. The value 13 is nearer to its maximum value so it will be replaced with 16.So the final value in the BIN 1 is [4, 4, 16, 16]. The same step have been repeated for all other bins. By using the smoothing by bin boundaries method, it helps in reducing the outliers value's impact and provides a clearer dataset for evaluation.
Advantages of Binning in Data Mining
There are many advantages of Binning in Data Mining such as:
Noise reduction: Rephasing helps reduce noise or non-linearities in the dataset.
Outlier identification: Rephasing assists in identifying outliers and missing values in numerical variables.
Hidden pattern discovery: Rephasing helps uncover hidden patterns within the dataset.
Ease of implementation and interpretation: Rephasing techniques are easy to implement and understand.
Overfitting prevention: Rephasing helps reduce the likelihood of overfitting in models.
Use Case of Binning in Data Mining
Here are some of the use cases where Binning can be used:
Customer Segmentation
Binning can be used in customer segmentation. A business can optimize its marketing strategies using the Binning method in customer segmentation.
We can use binning on continuous variables such as purchase amount, transaction, order placed, or category chosen. By separately creating these bins, it will help the business to make a target audience for a particular marketing campaign.
The binning process groups continuous data into discrete intervals (bins) to reduce noise, smooth data, and improve analysis in machine learning and statistics.
What is the meaning of binning of data?
Binning of data means dividing numerical values into fixed intervals (bins) to simplify patterns, reduce variability, and improve data preprocessing in analytics.
What is the difference between clustering and binning?
Clustering groups similar data points dynamically, while binning divides data into predefined fixed intervals without considering similarity among values.
Conclusion
Binning is a valuable technique in Data Mining. It allows us to transform continuous variables into discrete categories or bins. It simplifies data analysis, improves interpretability, and enables us to recognize patterns and trends. If you are working with a large dataset, data visualization is challenging, or when an algorithm and model require categorical data. In all these cases, Binning is helpful. In this article, we discuss different techniques involved in Binning. Standard techniques are Equal Width Binning and Equal Frequency Binning. We even explore other Data Smoothing techniques which are associated with Binning. Data Smoothing techniques are the bin mean method and bin boundary method. We even discuss some use cases of Binning in Data Mining. Overall, Binning is a versatile tool in data mining.
To learn more about this topic, check out the link below:






























 18+ registered
18+ registered 

