Do you think IIT Guwahati certified course can help you in your career?
Introduction
Bottom-up parsing begins at the terminal symbols (leaf nodes) of a parse tree and ascends towards the root node, combining smaller units into larger ones until the entire structure is formed. This method is commonly used in syntax analysis to construct parse trees for input strings.
This parser compresses the non-terminals where it starts and moves backward to the starting symbol of the parse tree using grammar productions to draw the input string's parse tree.
In this technique, parsing starts from the leaf node of the parse tree to the start symbol of the parse tree in a bottom-up manner.
Bottom-up parsing attempts to construct a parse tree by reducing input string and using Right Most Derivation.
Bottom-up parsing starts with the input symbol and constructs the parse tree up to the start symbol using a production rule to reduce the string to get the starting symbol.
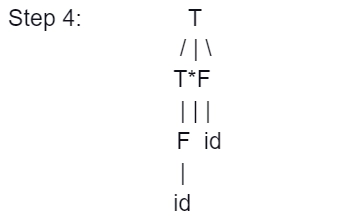
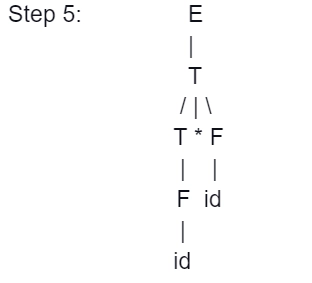
Example
E → T
T → T * F
T → id
F → T
F → id
Parse Tree representation of input string "id * id" is as follows:
Reduction Process in Bottom-Up Parsing
The reduction process in bottom-up parsing is a key operation where the parser works from input tokens towards the start symbol by reducing a sequence of symbols to a non-terminal using grammar rules. This process is essential in constructing a parse tree for a given input.
How Reduction Works in Bottom-Up Parsing?
Shift – Read the next input symbol and push it onto the stack.
Reduce – Replace a sequence of symbols on the stack with a non-terminal if it matches a production rule in the grammar.
Repeat – Continue shifting and reducing until the entire input is reduced to the start symbol of the grammar.
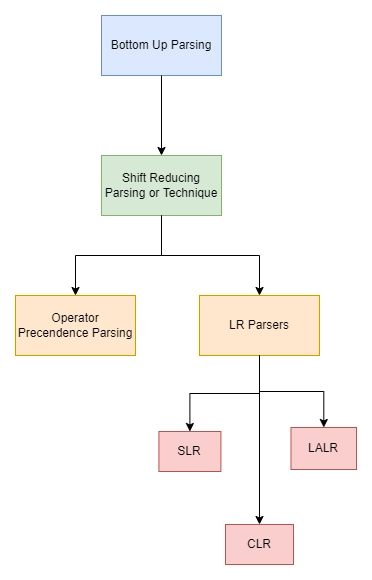
Classification of Bottom-up parsing
Bottom-up parsing has been classified into various parsing. These are as follows:
Shift-Reduce Parsing
Operator Precedence Parsing
Table Driven LR Parsing
Classification of Bottom-up parsing
Shift Reduce Parsing
Shift reduce parsing is a process to reduce a string to its grammar start symbol. It uses a stack to hold the grammar and an input tape to hold the string. Shift reduce parsing performs the two actions: shift and reduce. This is why it is known as shift-reduce parsing. The current symbol in the input string is pushed to a stack at the shift action. At each reduction, the symbols will be replaced by the non-terminals. The non-terminal is the left side of the output, and the symbol is the right side of the production.
Example
Grammar:
S → S+S
S → S-S
S → (S)
S → a
Input string: a1-(a2+a3)
Parsing table
Stack contents
Input String
Actions
$
a1-(a2+a3)$
Shift a1
$a1
-(a2+a3)$
Reduce by s->a
$S
-(a2+a3)$
Shift -
$S-
(a2+a3)$
Shift (
$S-(
a2+a3)$
Shift a2
$S-(a2
+a3)$
Reduce by S->a
$S-(S
+a3)$
Shift +
$S-(S+
a3)$
Shift a3
$S-(S+a3
)$
Reduce by S->a
$S-(S+S
)$
shift)
$S-(S+S)
$
Reduce by S->S+S
$S-(S)
$
Reduce by S->(S)
$S-S
$
Reduce by S->S-S
$S
$
Accept
There are two main categories in shift-reduce parsing as follows:
Operator-Precedence Parsing
LR-Parser
Operator Precedence Parsing
Operator precedence grammar is a category in the shift-reduce method of parsing. It is applied to a class of grammar operators. Operator precedence grammar must have the following two properties:
No RHS of any product has a∈.
Two non-terminals must not be adjacent.
Operator precedence can only be fixed between the terminals of the grammar. It generally ignores the non-terminal.
There are three operator precedence relations:
a ⋗ b means that terminal "a" has higher precedence than terminal "b."
a ⋖ b means that terminal "a" has lower priority than terminal "b."
a ≐ b means that the terminal "a" and "b" both have the same precedence.
Precedence table
Following is a precedence table according to which grammar of the operator precedence parsing works.
Parsing Action
The sequence in which parsing action is performed in operator precedence parsing is as:
At first, the $ symbol is added to both ends of the string.
Now we scan the input string from left to right until the character ⋗ is encountered.
Scanning is done towards leftover all the equal precedence until the first leftmost ⋖ is encountered.
Everything between leftmost ⋖ and rightmost ⋗ is a handle.
If it is $ on $, then it means parsing is successful.
Table-driven LR Parsing
LR parsing is also a category of Bottom-up parsing. It is generally used to parse the class of grammars whose size is large. In the LR parsing, "L" stands for scanning of the input left-to-right, and "R" stands for constructing a rightmost derivation in a reverse way.
"K" stands for the count of input symbols of the look-ahead that are used to make many parsing decisions.
Types of LR Parsers:
LR( 1 )
SLR( 1 )
CLR ( 1 )
LALR( 1 )
The L stands for scan operations of Bottom-up parsing left-to-right, and R stands for scan right-to-left in Bottom-up parsing.
LR bottom-up parsing parsers have several advantages of Bottom-up parsing like:
Used in many programming languages except Perl and C.
Efficient implementation.
In L-operations, they detect quickly any syntactic errors present in a bottom-up parsing example.
LR parsing is divided into four categories of Parsing:
LR (0) parsing
SLR parsing
CLR parsing
LALR parsing
Types of LR parser
LR algorithm
The LR algorithm requires input, output, stack, and parsing tables. In all types of LR parsing, input, output, and stack are the same, but the parsing table is different. The input buffer indicates the end of input data, and it has the string to be parsed. The symbol of "$ follows that string."A stack is used to contain the grammar symbols' sequence with the symbol $ at the stack's Bottom.
A parsing table can be defined as an array of two-dimensions. It usually contains two parts: the action part and the go-to part.
LR (1) Parsing
The various steps involved in the LR (1) Parsing are as follows:
A canonical collection of LR (0) items are created.
A data flow diagram is drawn.
An LR (1) parsing table is created.
Augment Grammar
Augmented grammar will be generated if we add one more product in the given grammar G. It helps the parser identify when to stop the parsing and announce the acceptance of the input.
LL vs. LR
LL (Left-to-Right, Leftmost Derivation) and LR (Left-to-Right, Rightmost Derivation) are two types of parsing techniques used in compiler construction and formal language theory. They belong to the broader category of shift-reduce parsing algorithms. Here's a comparison between LL and LR parsing:
Feature
LL Parsing
LR Parsing
Type
Top-down parsing
Bottom-up parsing
Derivation
Leftmost
Rightmost
Strategy
Predictive
Shift-reduce
Complexity
Simpler, easier to understand and implement
More complex, requires parsing tables
Power
Limited power, handles simpler grammars
More powerful, handles wider range of grammars
Lookahead
Often requires more lookahead symbols
Often requires fewer lookahead symbols
Error Handling
Less efficient at error recovery
More efficient at error recovery
Example
Recursive descent parsing
LR(0), SLR(1), LALR(1), CLR(1) parsing
Frequently Asked Questions
How does bottom-up parsing work?
Bottom-up parsers work by "shifting" symbols onto a stack till the stack top contains a right-hand side of a production, and then the stack is reduced by replacing the right-hand side of production with the left-hand side.
Write a drawback of the LR parser?
A major drawback of an LR parser is that it is too much work to construct an LR parser by hand.
What are the algorithms for constructing an LR parser?
There are mainly three such algorithms: SLR(1) - Simple LR Parser LR(1) - LR Parser LALR(1) - Look-Ahead LR Parser
What is the reduce step in shift-reduce parsing?
When the parser finds a complete grammar rule in RHS and replaces it with LHS, it is a reduced step.
What are the features of a simple LR Parser?
It works on the smallest class of grammar, and they have simple and fast calculations.
Conclusion
In this article, we have discussed the concepts of bottom-up parsing, shift-reduce Parsing, operator precedence parsing, and table-driven LR parsing and frequently asked questions.




























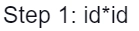





 9+ registered
9+ registered 
