Do you think IIT Guwahati certified course can help you in your career?
Introduction
In this article, we will go throughBreath First Traversal Applications. An approach that is frequently used to find the vertex position in a graph is called agraph traverse. An advanced search algorithm can quickly and accurately evaluate the graph and record the order of vertices visited. This method makes it possible to traverse a graph rapidly without becoming stuck in an endless loop.
Breath-First Search Algorithm (BFS)
The algorithm known as breadth-first search (BFS) is used to traverse structures, search trees, and graph data. TheBreadth-first search is the full name for BFS.
The program accurately visits and accurately marks all of the important nodes in a graph. This algorithm explores every node that is adjacent to the single node it has chosen (the initial or source point in a graph). Recall thatBreath-First Search connects to each of these nodes individually.
The algorithm goes toward the closest unvisited nodes and analyses them after it has visited and marked the initial node. AfterEacheach node is marked. Up in a graph, until every node in the graph has been successfully visited and marked, these iterations will continue.
The design of the Breath-First Search algorithm
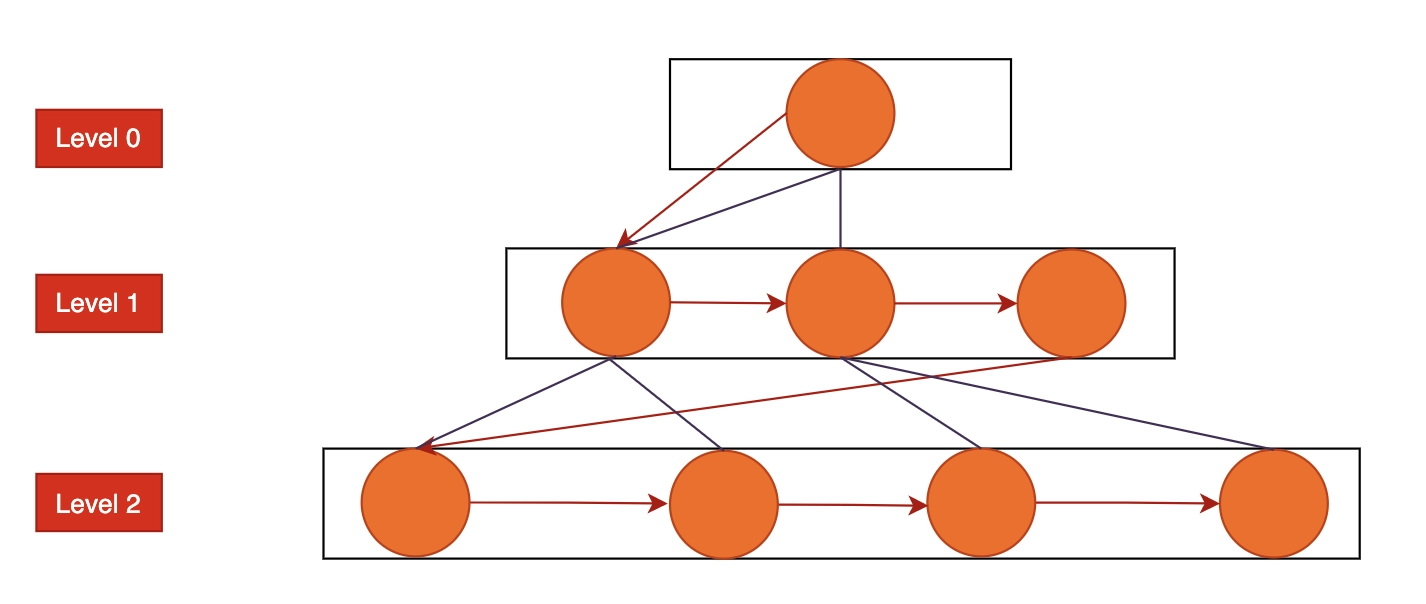
You can designate any node within the data's multiple tiers as the first or starting node to start traversing. The node will be visited by the Breath-First Search, which will then add it to the queue and mark it as visited.
The Breath-First Search will now mark the nearby and unvisited nodes by visiting them. Additionally, the queue receives these values. The queue operates using a FIFO approach.
Similar steps are taken to examine, mark, and add to the queue the remaining nearest and unvisited nodes on the graph.
Why is Breath-First Search Algorithm needed
The Breath-First Search Algorithm should be used to search your dataset for various purposes. This algorithm should be your first choice because of some of the essential features, including
Breath-First Search helps examine a graph's nodes and create the shortest route between them.
Breath-First Search can navigate a graph in the fewest iterations possible.
The Breath-First Search algorithm has a straightforward and reliable architecture.
Unlike other algorithms, the Breath-First Search algorithm's output is highly accurate.
Breath-First Search iterations are smooth. Hence there is no chance that this algorithm will become stuck in an endless loop.
Breath-First Search Algorithm
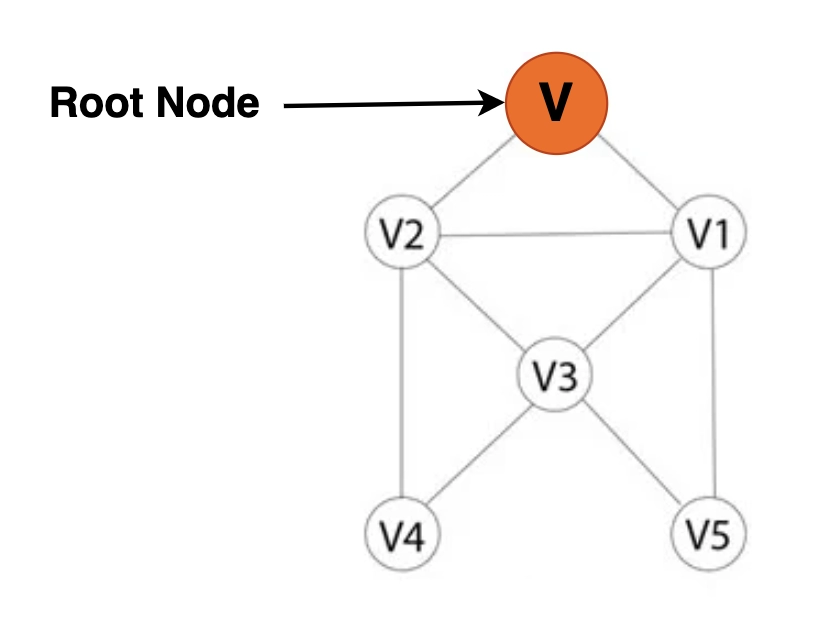
Step 1: In a graph, each vertex or node is known. You may designate the node as V, for example.
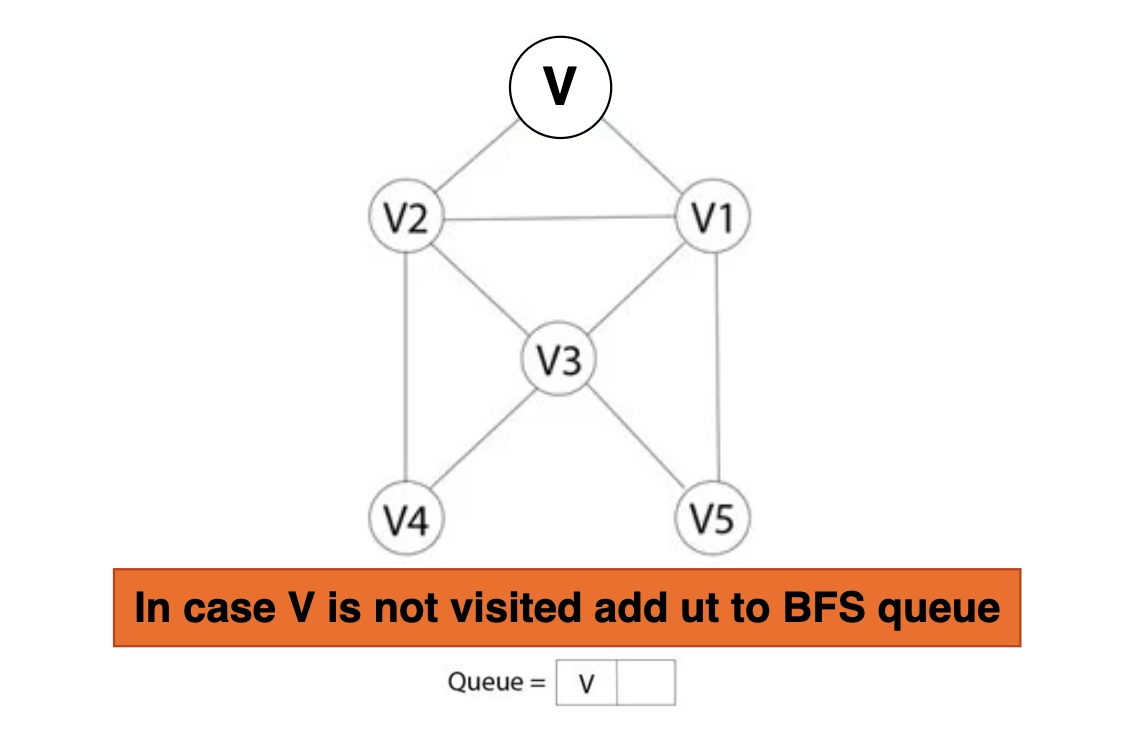
Step 2: Add vertex V to the Breath-First Search Queue if vertex V cannot be accessed.
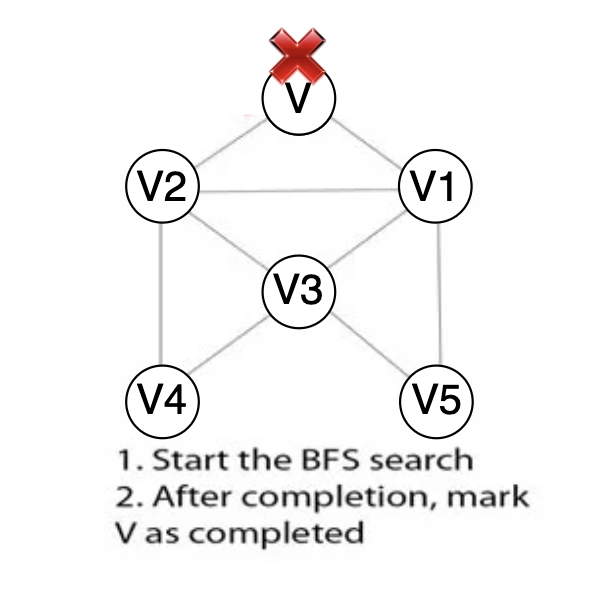
Step 3: After beginning the Breath-First Search search, mark vertex V as visited.
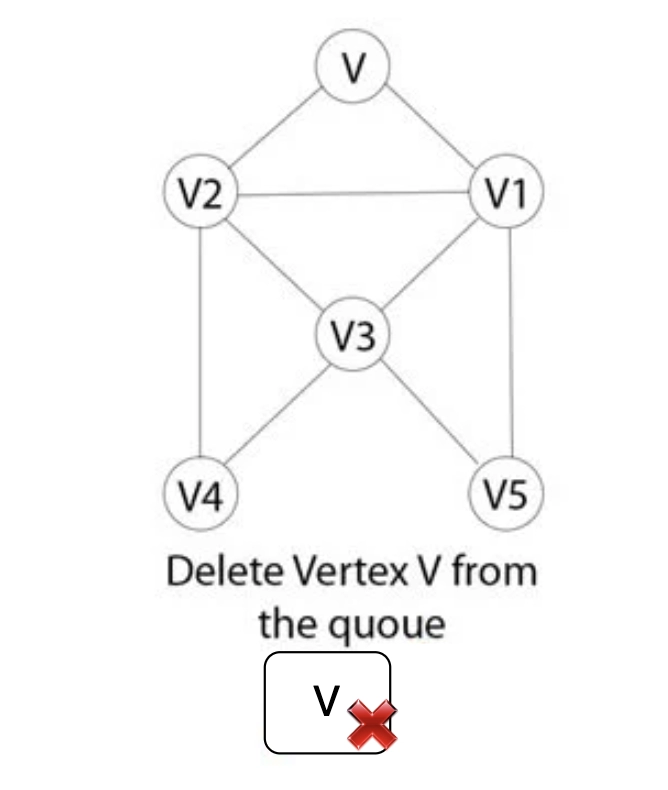
Step 4: Since the Breath-First Search queue is still not empty, the graph's vertex V should be taken out of the queue.
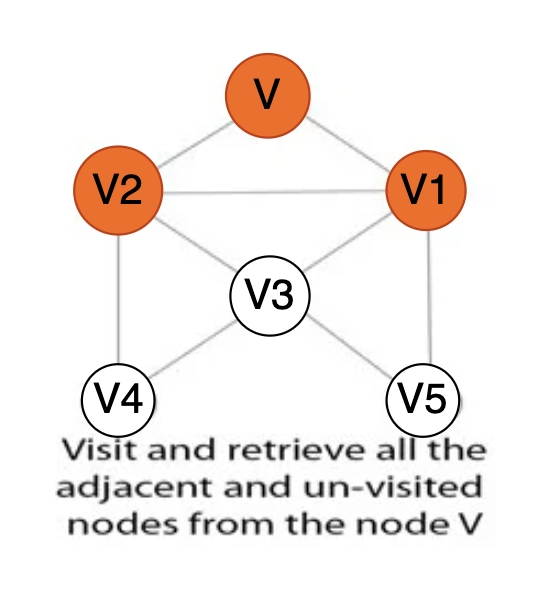
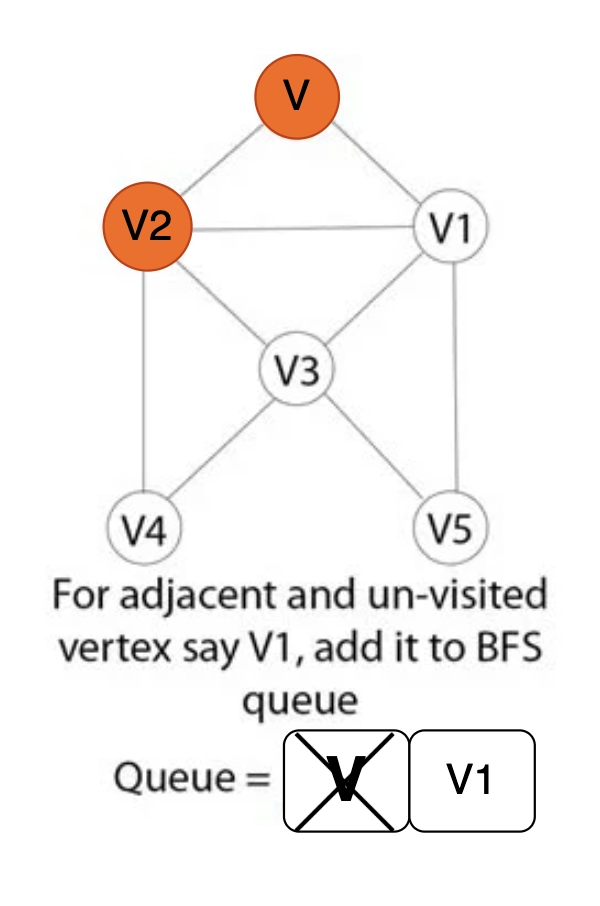
Step 5: Get every other vertex in the graph that is close to the vertex V.
Step 6: If a neighboring vertex, let's say V1, has not yet been visited, add V1 to theBreath-First Search queue.
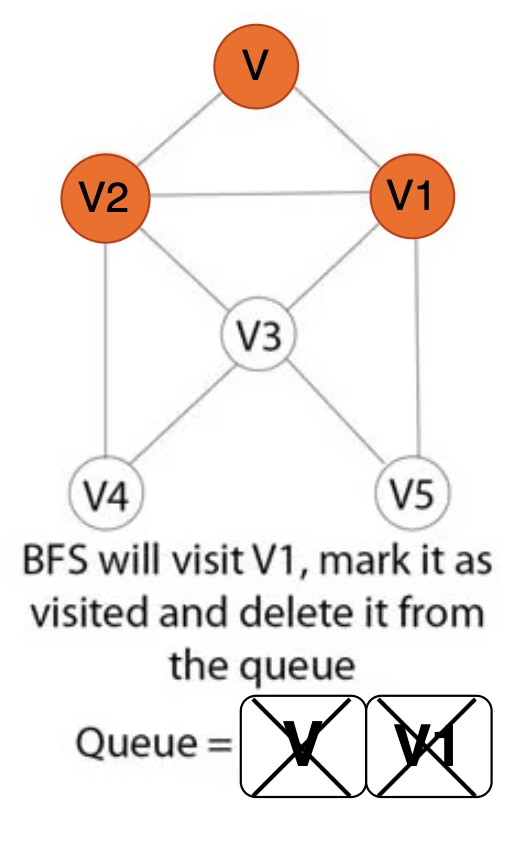
Step 7: Once Breath-First Search has visited V1, it will be marked as visited and removed from the queue.
Breath-First Search Algorithm Rules
The following are key guidelines for using theBreath-First Search algorithm:
Breath-First Search employs a queue (FIFO-First in, First out) Data Structure.
Any node in the graph can be designated as the root, and you can traverse the data from there.
Breath-First Search iterates through every node in the graph and keeps eliminating them as finished.
The Breath-First Search visits a nearby unvisited node, finishes it, and adds it to a queue.
In the event that no neighboring vertex is located, remove the preceding vertex from the queue.
Until every vertex in the graph has been successfully explored and tagged as complete, the Breath-First Search algorithm iterates.
Breath-First Search does not introduce loops while traversing data from any node.
C++ implementation
#include <iostream>
#include <map>
#include <set>
#include <queue>
/* a section of the OpenGenus Foundation's Cosmos */
void BFS(int start, // the node where we are right now
std::map<int, std::set<int>>& list, // each node's adjacency list
std::map<int, bool>& visited, // the state that each node has visited.
std::map<int, int>& distance // how far you are from the "start" node
) {
// Clear the distance map to the point that it only contains nodes that we can truly access from the "start"
distance.clear();
// The pairs of numbers in this queue will be of the type (nodeNumber, distance)
std::queue<std::pair<int, int>> Q;
// Mark as visited and add the first node with distance 0 to the queue.
Q.push(std::make_pair(start, 0));
visited[start] = true;
// until there are no more ndoes to process, repeat the method.
while (!Q.empty()) {
// Pick up the node at the front of the line and remove it.
auto entry = Q.front(); Q.pop();
int node = entry.first;
int dist = entry.second;
// Add this node's distance to the distance map (this is the minimal distance to this node)
distance[node] = dist;
// iterate through the current node's neighbours
for (auto neighbour : list[node]) {
if (!visited[neighbour]) {
// Make the neighbouring node visible as visited.
visited[neighbour] = true;
Q.push(std::make_pair(neighbour, dist + 1));
}
}
}
}
void addEdge(int a, int b, std::map<int, std::set<int>>& list) {
list[a].insert(b);
list[b].insert(a);
}
int main() {
/*
In this graph, perform a breadth-first search:
*/
std::map<int, std::set<int>> list;
std::map<int, bool> visited;
std::map<int, int> dist;
addEdge(1, 2, list);
addEdge(1, 3, list);
addEdge(2, 3, list);
addEdge(2, 4, list);
addEdge(2, 5, list);
addEdge(4, 7, list);
addEdge(5, 6, list);
addEdge(6, 7, list);
addEdge(8, 9, list);
// Initialize all nodes as unvisited
for (int i = 1; i <= 8; i++) visited[i] = false;
// carry out a Breath-First Search from node "1"
BFS(1, list, visited, dist);
// Print the distance to all visited nodes
for (auto entry : dist) {
std::cout << "Distance from 1 to " << entry.first << " is " << entry.second << std::endl;
}
return 0;
}
Output
Distance from 1 to 1 is 0
Distance from 1 to 2 is 1
Distance from 1 to 3 is 1
Distance from 1 to 4 is 2
Distance from 1 to 5 is 2
Distance from 1 to 6 is 3
Distance from 1 to 7 is 3
Complexity
Time complexity
O(V+E): The time complexity of Breath-First Search is O(V+E), where V is the number of vertices when the whole graph is traversed, and E is the Edge.
Reason: Since breadth-first search must, in the worst scenario, take into account all routes to all potential nodes, its time complexity is O(|E| + |V|). The complexity arises from the fact that every vertex and edge in the worst-case scenario will be analyzed.
Space Complexity
O(V): The Space complexity of Breath-First Search is O(V), where V is the number of vertices when the whole graph is traversed.
Reason: In the worst case, Since only the first time a vertex is reached is its distance nil, each vertex is only enqueued once at most and is only visited once. So the required space is O(V). Check out this problem - No of Spanning Trees in a Graph
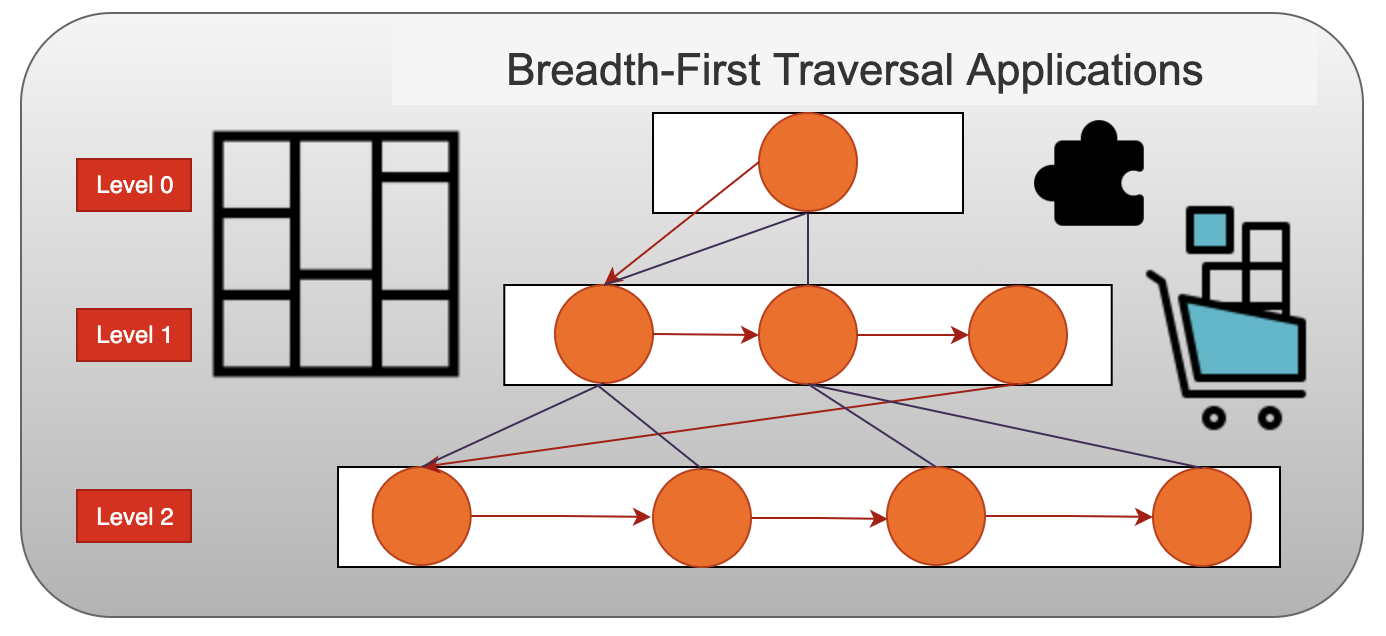
Applications for the Breath-First Search Algorithm
Let's look at real-world scenarios where a Breath-First Search algorithm implementation can be pretty successful.
1. Unweighted Graphs: Using the Breath-First Search algorithm, finding the shortest path and the least spanning tree is simple to accurately and quickly traverse the whole graph.
2. P2P Networks: Breath-First Search can be used to find every node that is close by or nearby in a peer-to-peer network. This will speed up the process of finding the needed information.
3. Web crawlers: By using Breath-First Search, search engines or web crawlers can quickly create many tiers of indexes. The web page serves as the starting point for Breath-First Search implementation, after which it visits each link on the page.
4. Navigational aids: Breath-First Search can assist in locating all nearby sites from the primary or source location.
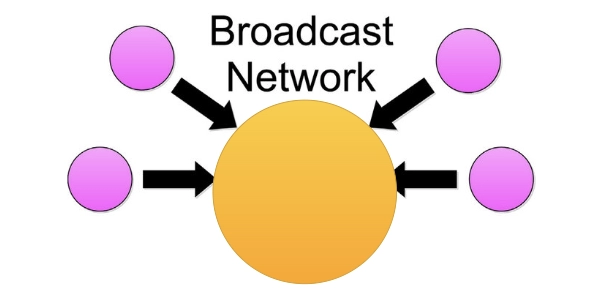
5. Network Broadcasting: The Breath-First Search algorithm helps a broadcasted packet locate and connect to every node it has an address for.
Frequently Asked Questions
Why FIFO is used for breadth-first search?
The frontier is implemented as a FIFO (first-in, first-out) queue in breadth-first search. As a result, the route chosen from the frontier is the one that was initially added. According to this method, the pathways leading from the start node are formed according to the number of arcs they contain.
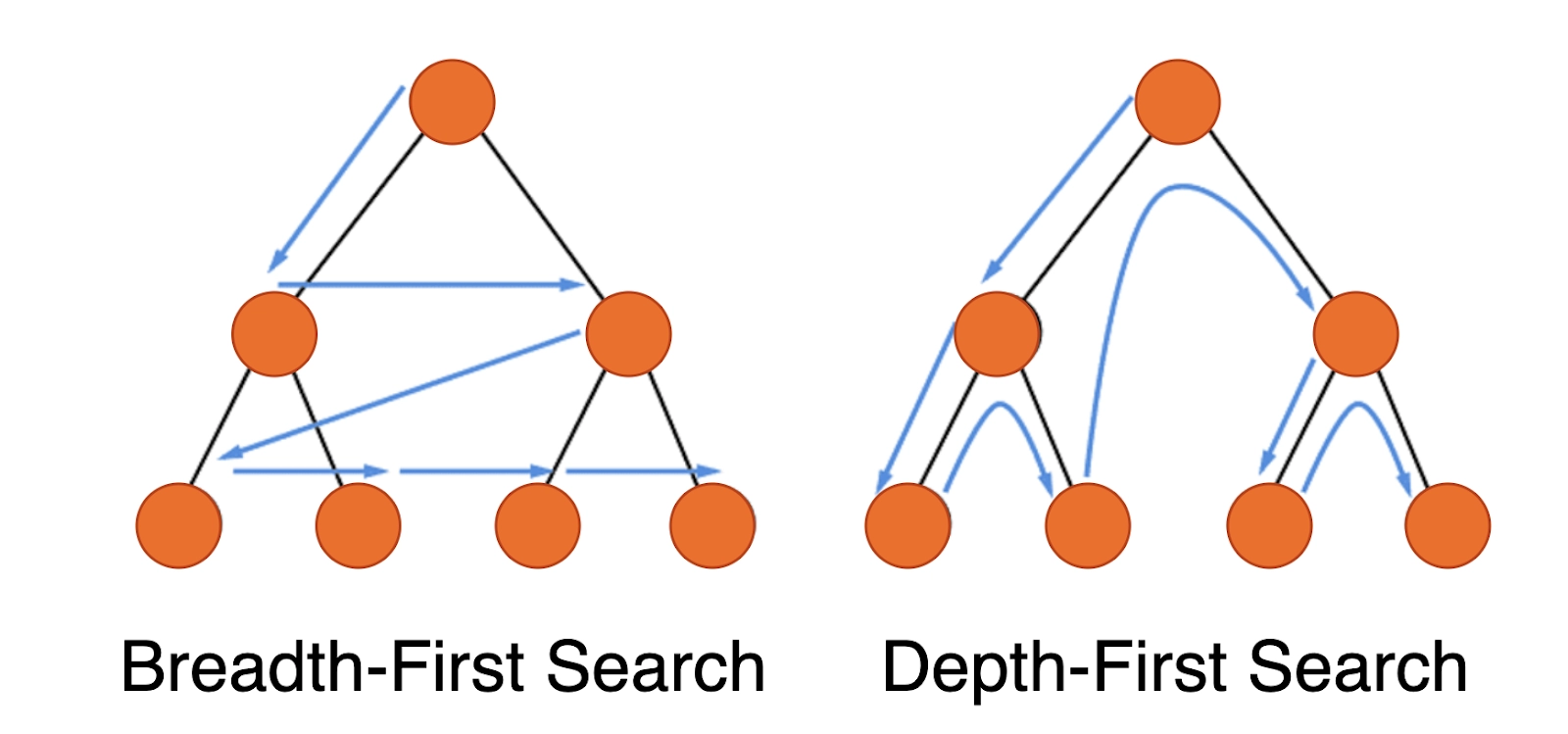
How come Breath-First Search is quicker than DFS?
Breath-First Search should usually be quicker if the searched element is typically higher in the search tree because it travels level by level and can be stopped when a matched element is discovered. If the searched element is usually rather deep and locating one among many is adequate, DFS might be faster.
When should we use BFS?
The shortest path between two nodes (original sources) may be determined using BFS if the edges have a unit weight. DFS, on the other hand, may be used to exhaust all options due to its in-depth nature, such as finding the longest path between any two nodes in an acyclic network.
Is Breath-First Search a greedy algorithm?
The phrase "greedy algorithm" describes programs that address optimization issues. It doesn't make sense (i.e., it's not even false) to state that Breath-First Search is a greedy algorithm unless you are using it for an optimization problem because Breath-First Search isn't designed explicitly to solve optimization problems.
Conclusion
In this article, you learned theBreath First Search technique (also known as the Breath-First Search algorithm) using examples, discovered how to use it in code, and observed several implementations of the Breath-First Search algorithm.
Please refer to our guided pathways on Code studio to learn more about DSA, Competitive Programming, JavaScript, System Design, etc. Enroll in ourcourses, and use the accessible sample examsandquestions as a guide. For placement preparations, look at the interview experiences andinterview package.
If you find any problems, please comment. We will love to answer your questions.































 9+ registered
9+ registered 
