Do you think IIT Guwahati certified course can help you in your career?
Introduction
Machine learning is one of the most exciting fields of computer science. It uses various algorithms to learn from the data and make predictions accordingly. Multiple techniques are used to make the predictions more accurate. Let us look at one of these techniques known as CatBoost. Contrary to its name, CatBoost is not something that we boost from a cat. So what exactly is CatBoost? Let’s find out.
Boosting is a sequential ensemble machine learning technique. The main aim of boosting is to combine weak learners to make strong learners. It improves the overall performance, and hence, we get better results.
What is CatBoost?
CatBoost comes from two words, Categorical Boosting. Where Cat signifies Categorical, and Boost means Boosting. It is a famous ensemble machine learning algorithm based on gradient boosting. This algorithm overtakes many other Boosting algorithms like XGBoost, LightGBM, etc., in various aspects like performance, accuracy, implementation, hyper tuning parameters, and many more. Categorical Boosting goes well with categorical data, but it can also handle numerical and text data features.
One key advantage of CatBoost over other Boosting algorithms is that it uses symmetric trees and builds them level by level.
By symmetric trees, we mean that any parent node having either zero or two children will follow the same breakdown structure as shown above. Now, let us focus on the working of CatBoost.
Working of CatBoost
CatBoost provides various techniques such as one-hot encoding to handle categorical data. It also combines categorial features automatically. CatBoost can convert categories into numbers without any preprocessing.
Let us look at a simple example to understand how does it work. Below is a dataset containing 10 data points arranged with respect to time series.
Time
Datapoint
Classroom
12.00
x1
10
12.01
x2
12
12.02
x3
9
12.03
x4
4
12.04
x5
52
12.05
x6
22
12.06
x7
33
12.07
x8
34
12.08
x9
32
12.09
x10
12
Suppose we want to get the result of a particular data point. We have to calculate the result of all the previous data points. For example, if we want to calculate the residual of x5. We have to train and get the residuals of x1, x2, x3, and x4. This process is very costly, especially for large data points.
The main idea is that if we have trained our model up to ‘p’ data points, their residuals will be used to get the residuals of the following ‘p’ data points. For example, if we have trained our model up to x1, x2, x3, and x4. Their residuals will be used to calculate the residuals of x5, x6, x7, and x8. Thus, instead of training each data point separately, it will only train log(number_of_datapoints) data points.
This process is called ordered boosting, as the process occurs in order.
CatBoost prefers random permutations on the data set and applies ordered boosting on the random permutations. By default, CatBoost always prefers random permutations. This randomness helps to prevent the overfitting of the model and can be controlled by tuning parameters.
Features of CatBoost
CatBoost provides various techniques such as one-hot encoding to handle categorical data. It also combines categorial features automatically.
CatBoost works well with non-numeric factors due to which there is less need for pre-processing of the data, and it also improves the overall performance of the dataset.
CatBoost reduces the chances of over-fitting and constructs the model using a novel gradient boosting scheme.
CatBoost uses a fast and scalable GPU version. Models trained using GPU provide better performance and speed compatibility than CPU-trained models.
CatBoost vs. XGBoost vs. LightGBM
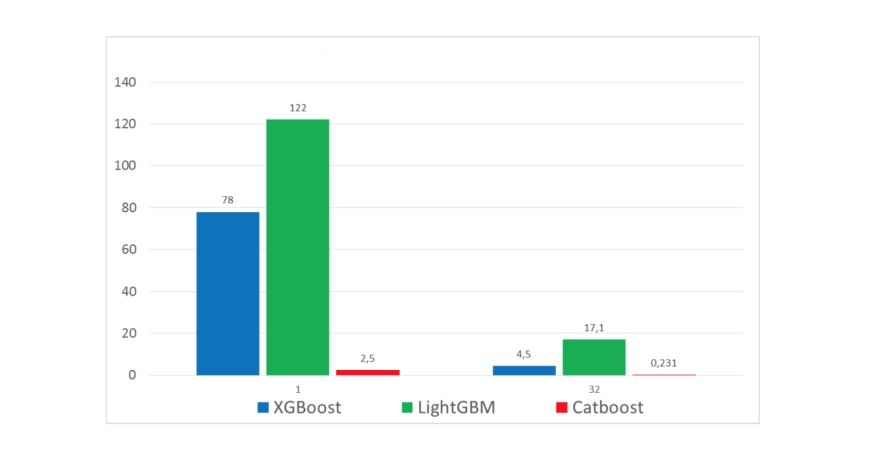
Let us look at the performance comparison of CatBoost, XGBoost, and LightGBM.
CatBoost is significantly faster than both XGBoost and LightBGM when trained on both CPU and GPU.
Places to use CatBoost
Robust data
CatBoost is mostly preferred for robust data where a short training time is required.
Categorical feature transformation
CatBoost treats categorical data in the best way compared to other Machine Learning algorithms.
Data splitting
Based on the starting parameters of CatBoost, quantization goes well for determining the numerical features while transforming the data into various buckets.
Note: If the tuning features of the model are required for optimizing the model, you should never prefer CatBoost.
Implementation of CatBoost
CatBoost can be easily implemented in our model using the catboost library.
To install catboost on python:
pip install catboost
To use catboost in our code, we have to import CatboostClassifier from catboost:
from catboost import CatBoostClassifier
To initialize CatBoostClassifier:
model = CatBoostClassifier(iterations=10, learning_rate=0.1, depth=2)
To train our model:
model.fit(train_data, train_labels)
train_data and train_labels are the x and y coordinates of our training data which we will provide.
To get the predictions:
prediction = model.predict(test_data)
To train a model on the GPU, we have to set the task_type as “GPU” while initializing our CatBoostClassifier. For example:
model = CatBoostClassifier(iterations=100, learning_rate=0.25,
task_type = “GPU”)
Advantages and Disadvantages of CatBoost
Advantages
Disadvantages
It gives us great results for categorical data
It performs only better than other algorithms only when we have categorical data
It can train our model on GPU that significantly increase the speed of learning
Can perform very bad if the variables are not properly tuned
Applications
Weather forecasting: CatBoost improves the accuracy of weather forecasting and also helps in discovering future meteorological elements. We mean temperature, wind, humidity, and many more by accurately forecasting meteorological factors. These features are very critical and are used in many fields.
Fraud detection: this includes a set of processes that helps to prevent unauthorized access in various business sectors. The sectors include banking, finance, Medicare, etc.
Sales forecasting: Nowadays, sales forecasting is one of the important technologies in the retail industry. It helps to predict the accuracy of sales of thousands of products and make optimum decisions based on them.
According to the CatBoost version 0.6, it can perform extraordinarily faster than XGBoost or lightGBM. Some of the training data of CatBoost can slow down the training process, but it is still quicker than XGBoost.
2. Define border count for CatBoost?
Border count refers to the number of splits for numerical features in CatBoost.
3. Can we plot a graph while training?
Yes, It is possible to plot a graph while training by setting the plot parameter to “True”. For example, model.fit(train_data, train_labels, plot = True)
Key takeaways
This article has covered a short overview of the CatBoost Algorithm. You should train your model using CatBoost, especially when you need the results to be much faster than XGBoost. Keeping the theoretical knowledge at our fingertips helps us get about half the work done. To achieve a thorough understanding of machine learning, you may refer to ourmachine learning course.





































 6+ registered
6+ registered 

