Do you think IIT Guwahati certified course can help you in your career?
Introduction
The data that can be divided into groups is called categorical data. The example of categorical is age group, sex, race, etc. Analysis of categorical data is generally done using data tables.
A two-way table presents categorical data by counting the number of observations that fall into each group for two variables, divided into rows and divided into columns.
Difference between categorical and numerical data
Categorical data can be referred to as a data type that can be stored and identified based on the name or the label given to them, whereas numerical data is stored in the form of numbers. Categorical data is qualitative data, and numerical data is quantitative data. There are two types of numerical data, i.e., discrete and continuous data. Categorical data is divided into ordinal and nominal data. Categorical data is visualized only through bar graphs and pie charts, but numerical data can be visualized through bar graphs, pie charts, scatter plots, etc.
Types of categorical data
Categorical data is divided into two types:
Ordinal Data: The ordering of the data matter. Classes have an inherent order.
Nominal Data: The ordering of the data doesn’t matter. Classes do not have an inherent order.
Operations on Categorical data
I will be using the pandas library for performing operations on categorical data.
Data Creation and Basic Functions
● Let us create Categorical data using pd.Series() by specifying “dtype=category”.
data = pd.Series(["A", "B", "C", "D"]*3, dtype="category")
data
0 A 1 B 2 C 3 D 4 A 5 B 6 C 7 D 8 A 9 B 10 C 11 D dtype: category Categories (4, object): ['A', 'B', 'C', 'D']
● Getting the count of every category from the dataset.
pd.value_counts(data)
A 3 B 3 C 3 D 3 dtype: int64
● Creating categorical data using pandas DataFrame where each column is of category type.
data = pd.DataFrame({"A": list("wzxyz"), "B": list("ppsqr"), "C":list("15354")}, dtype="category")
data
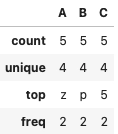
● Using describe function to get details of each column in the dataset.
data.describe()
● Getting information of datatypes of each column from the dataset.
data.dtypes
A category B category C category dtype: object
Working with categories
● Renaming the categories from the dataset.
data["A"].cat.categories = ["Class %s" % g for g in data["A"].cat.categories] data["B"].cat.categories = ["Section %s" % g for g in data["B"].cat.categories] data
● Adding and removing categories to the dataset.
data = pd.Series(["one", "two", "three", "four"], dtype="category") data
0 one 1 two 2 three 3 four dtype: category Categories (4, object): ['four', 'one', 'three', 'two']
Adding the “five” category to the dataset.
data = data.cat.add_categories(["five"]) data
0 one 1 two 2 three 3 four dtype: category Categories (5, object): ['four', 'one', 'three', 'two', 'five']
Removing the “three” category from the dataset.
data = data.cat.remove_categories(["three"]) data
0 one 1 two 2 NaN 3 four dtype: category Categories (4, object): ['four', 'one', 'two', 'five']
Sorting and Ordering
If the categorical data is ordered, then the data has a specific meaning and various operations can be performed. If the data is unordered then .min()/ .max() operations cannot be performed, it will give type error.
● Unordered data
data = pd.Series(pd.Categorical(["A", "B", "C", "D", "A"], ordered=False)) data
0 A 1 B 2 C 3 D 4 A dtype: category Categories (4, object): ['A', 'B', 'C', 'D']
Sorting the unordered data.
data.sort_values(inplace = True) data
0 A 4 A 1 B 2 C 3 D dtype: category Categories (4, object): ['A', 'B', 'C', 'D']
● Ordered data
data = pd.Series(pd.Categorical(["A", "B", "C", "D", "A"], ordered=True)) data
0 A 1 B 2 C 3 D 4 A dtype: category Categories (4, object): ['A' < 'B' < 'C' < 'D']
Sorting the ordered data
data.sort_values(inplace = True) data
0 A 4 A 1 B 2 C 3 D dtype: category Categories (4, object): ['A' < 'B' < 'C' < 'D']
Performing the .min() and .max() operation on ordered data.
data.min(), data.max()
('A', 'D')
● Reordered data
Reordering the categories is done by using the Categorical.reorder_categories() and the Categorical.set_categories() methods.
No new categories are allowed for using the Categorical.reorder_categories() method, and old categories must be included in the new categories. This will make the sort order the same as the categories order.
The below code will sort the categorical data in the “B” < “C” < “A” < “D” order.
data = data.cat.reorder_categories(["B", "C", "A", "D"], ordered=True)
data.sort_values(inplace = True)
data
1 B 2 C 0 A 4 A 3 D dtype: category Categories (4, object): ['B' < 'C' < 'A' < 'D']
● Multi-Column Sorting
Consider a dataset having two categorical columns sorting the data according to both the columns.
● Comparing categorical data with another categorical data and a scalar of the same categories and ordering.
data1 > data2
0False 1False 2True dtype: bool
data2 > 2
0True 1False 2False dtype: bool
● Equality comparisons
data1 == data2
0False 1True 2False dtype: bool
data3 == 2
0True 1True 2True dtype: bool
Missing data
In pandas we use np.nan to represent the missing values.
When working with categorical codes missing values will have value -1.
Nan values are not counted in categorical’s category.
data = pd.Series(["a", np.nan, "d", np.nan, "e"], dtype="category") data
0 a 1 NaN 2 d 3 NaN 4 e dtype: category Categories (3, object): ['a', 'd', 'e']
data.cat.codes
00 1-1 21 3-1 42 dtype: int8
Methods to work with categorical data.
isna(): returns false if the data is not null and true if data is null
fillna(“a”): Fills all the nan values in the categorical data with “a”(here a can be any categorical data).
dropna(): Drops all the nan values from the dataset.
FAQs
How do you identify categorical data? Calculate the difference between the number of unique values in the data set and the total number of values in the data set. Calculate the difference as a percentage of the total number of values in the data set. If the percentage difference is 90% or more, then the data set is composed of categorical values.
What is “categoricals” in pandas? “Categoricals” are a pandas data type corresponding to categorical variables in statistics.
What is hot encoding in python? A one-hot encoding is a representation of categorical variables as binary vectors.
What type of data is categorical? Categorical data is a type of data that can be stored into groups or categories with the aid of names or labels. This grouping is usually made according to the data characteristics and similarities of these characteristics through a method known as matching.
What are the two types of categorical data? There are two types of categorical variables, nominal and ordinal. A nominal variable has no intrinsic ordering to its categories. For example, gender is a categorical variable having two categories (male and female) with no intrinsic ordering to the categories. An ordinal variable has a clear ordering.
Key Takeaways
In this article, we have discussed the following topics:
Categorical data and its type
Difference between categorical and numerical data
Operation on categorical data
Hello readers, here's a perfect course that will guide you to dive deep into Machine learning.
































 8+ registered
8+ registered 

