Do you think IIT Guwahati certified course can help you in your career?
Introduction
This blog will discuss a problem based on the Depth-First Search. Depth-First Search is a widely asked topic in programming contests and technical interviews. We will solve a problem related to depth-first search in cycle detection and backtracking.
Problem Statement
You have been given an undirected graph and two nodes S & T. Your task is to check whether there is a cycle between S & T, such that no nodes appear more than once except S & T.
Print NO if no such cycle exists, otherwise print YES.
Input
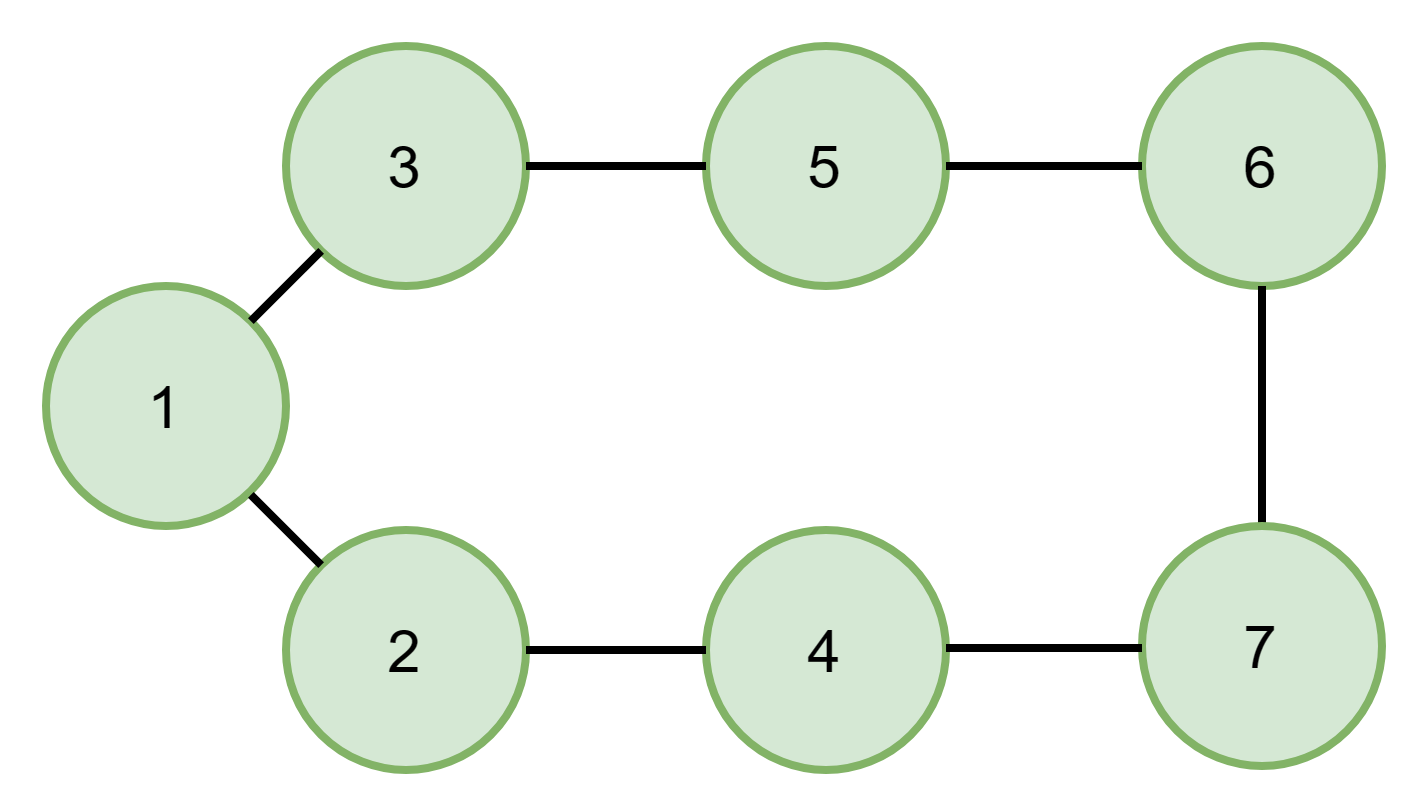
S=1, T=7
Output
Yes
Explanation
There is one cycle between 1 and 7 and it is valid no node appears twice in that cycle. The cycle is 1->3->5->6->7->4->2->1.
Input
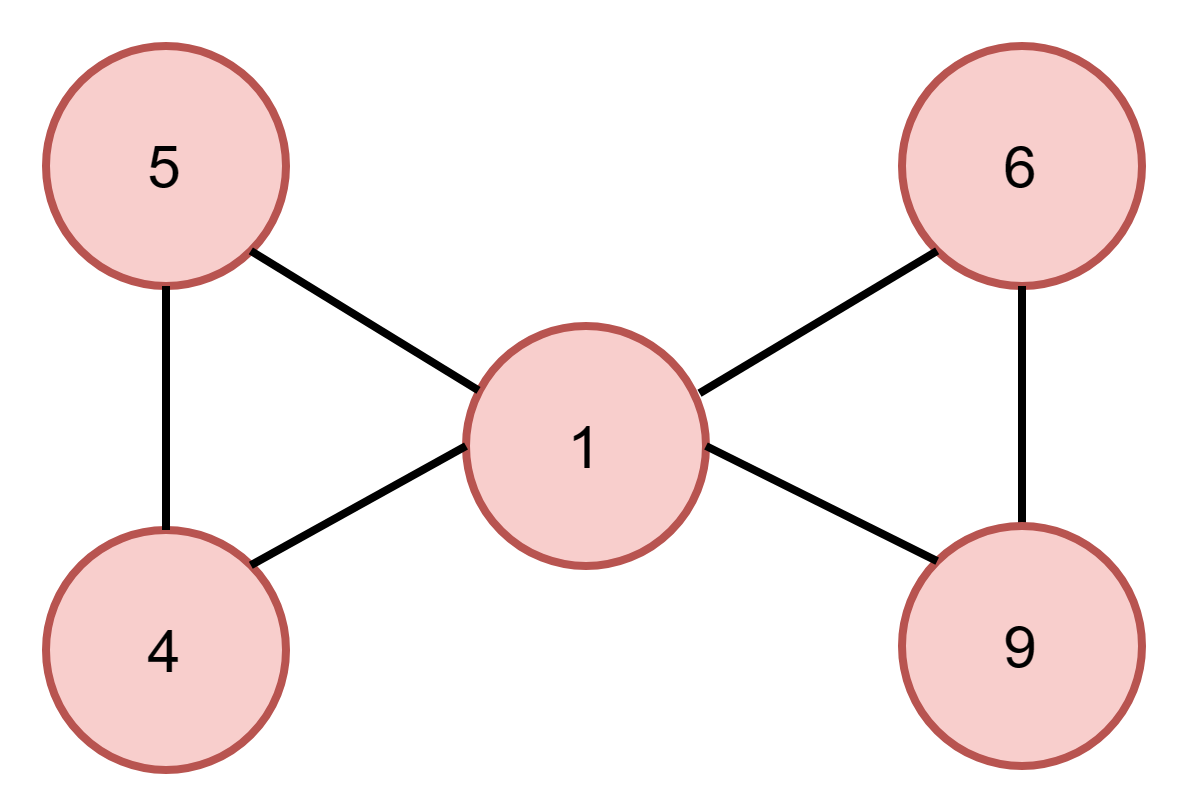
S=5, T=9
Output
No
Explanation
There are multiple cycles between 5 and 9 but none of them is valid because node 1 will appear twice in that cycle. One of them is 5->1->6->9->1->4->5.
Approach
We can use Depth-First Search with backtracking to solve this problem. A simple cycle is present between S & T if two different paths exist, one from S to T and the other from T to S, such that no vertices except S & T are repeated in them. We will run a DFS from S. When we reach node T, we will change the dest node to S. Since DFS only visits node unvisited, we will get a path with no repeated vertices. After visiting the subtree of a node, we will set it as unvisited (backtracking) to explore all possible paths.
Algorithm
Create a boolean array of size N to keep track of the visited node. (Initialize the array with a false value, which means that no node has been visited yet)
Run a DFS from S, with T as the destination node.
If we cannot reach T from S (i.e., there is no path from S to T), then it is impossible to have a simple cycle between S & T.
If we reach T, we change the destination to S and continue DFS. From here, nodes already visited (in the path from S to T) will not be revisited.
Finally, if S is reached, we print Yes, otherwise No.
Dry Run
Let us consider the undirected graph given in the sample example,
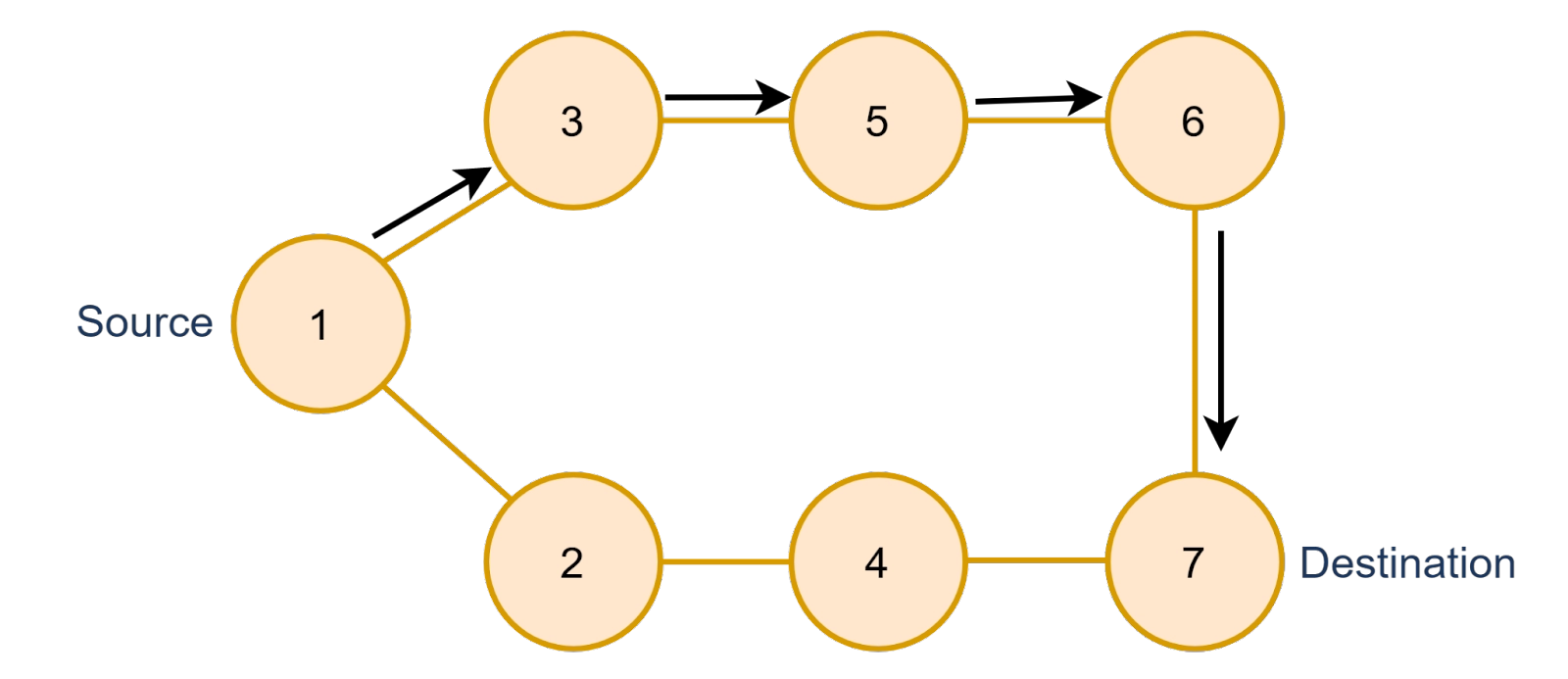
Step 1
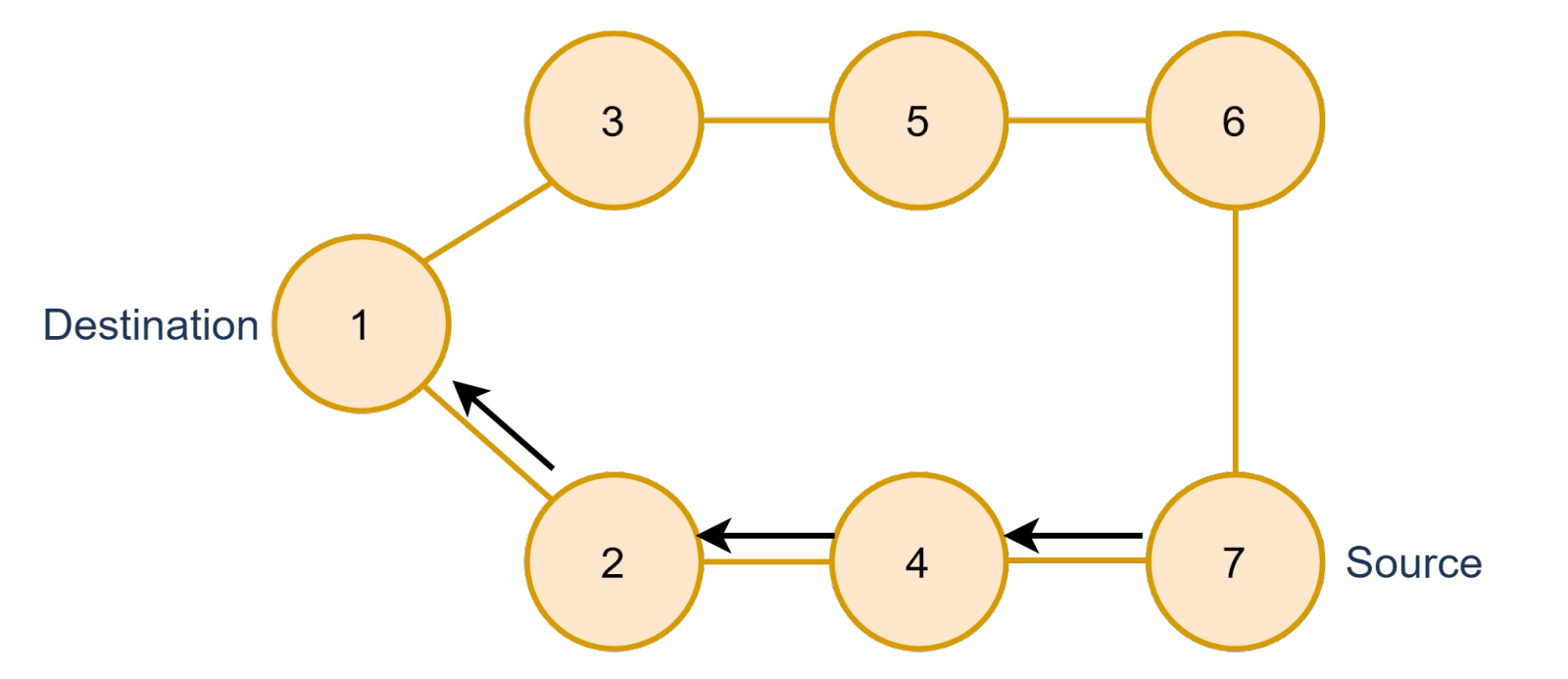
The first half of the cycle from Source(1) to Destination(7) would be like this, we will cover the path from source to destination using DFS Algorithm.
Step 2
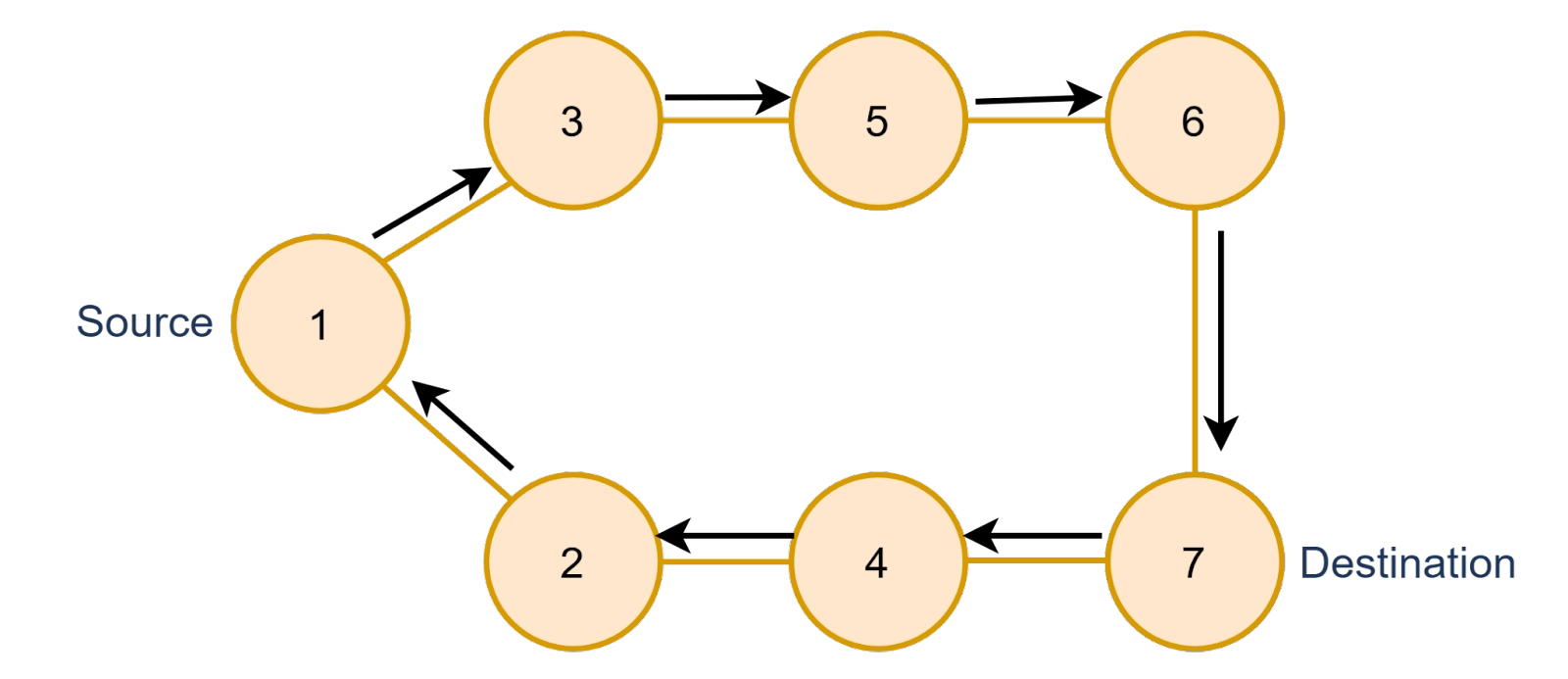
In the second half of the cycle, we will change the source and destination, now we will swap the value of the previous source and destination, and the new source will be 7 and the new destination will be 1. This time we will have to make sure that the path from the new source to the destination should not contain any nodes which have been visited previously.
Now, the cycle is complete and we have not discovered any node which already had been visited, the cycle would look like this,
Implementation in C++
#include <bits/stdc++.h>
using namespace std;
// to check if a node is visited or not
bool visited[1001];
// function to check if a cycle exists or not
bool dfs(int node, int source, int destination, bool flag, vector<int> *adj)
{
// When reaching destination, change the destination node to source
if (!flag && node == destination)
{
destination = source;
flag = true;
}
// If source is reached from destination, without
// visiting any node twice except themselves, then return True
if (flag and node == destination)
return true;
bool found = false;
visited[node] = true;
for (auto v : adj[node])
{
// Visit a node only if it hasn't been visited
// OR if it is S or T
if (!visited[v] || v == destination)
{
found = found | dfs(v, source, destination, flag, adj);
}
}
// Mark current node as unvisited so that all the
// paths can be traversed (BackTracking)
visited[node] = false;
return found;
}
// function to add an edge in the undirected graph
void add(int u, int v, vector<int> adj[])
{
adj[u].push_back(v);
adj[v].push_back(u);
}
int main()
{
// Number of nodes and edges
int N = 7, E = 7;
// cout << N << endl;
// vector to make adjacency list
vector<int> adj[N + 1];
add(1, 2, adj);
add(1, 3, adj);
add(3, 5, adj);
add(2, 4, adj);
add(5, 6, adj);
add(4, 7, adj);
add(6, 7, adj);
// Source and Destination
int S = 1, T = 7;
bool flag = false;
// If there exists a simple cycle between Source and Destination
if (dfs(S, S, T, flag, adj))
{
cout << "Yes there is a cycle";
}
// If no cycle exists between Source and Destination
else
{
cout << "No there is no cycle!!";
}
}
You can also try this code with Online C++ Compiler
O(N!) is the time complexity, where N is the number of nodes in the graph. Because in the worst case, all paths are traversed using back-tracking.
Space Complexity
The space complexity of the above approach is O(N^2), where N is the number of nodes in the graph.
Frequently Asked Questions
How does DFS handle cycles in a graph?
DFS uses a visited array to keep track of the nodes it has visited. If a node is visited again, it means that there is a cycle in graph and DFS terminates.
What are the different forms to represent a graph?
A graph can be represented as an array of edges or using an adjacency list or in the form of a V x V matrix where (i, j) is non-zero if i and j are connected in the graph. This form is also called adjacency matrix representation.
What are the different applications of DFS?
We can use DFS to detect graph cycles. It helps determine a path between two vertices. It's useful for determining topological sort. We can also use it to determine whether or not a graph is bipartite.
What is the time complexity of DFS search with adjacency matrix representation?
The time complexity of DFS with adjacency matrix representation is O(N^2), here N is the number of nodes in the graph.
What are the advantages of using DFS over BFS?
DFS can be more memory efficient than BFS as it does not need to store all the nodes at a given depth before visiting the next depth. DFS is also simpler to implement than BFS.
Conclusion
Cheers if you reached here!!
This article aimed to discuss an intriguing problem using graph DFS. We saw an exciting application of the DFS technique in this article. DFS-related coding problems are sometimes simple to implement, but finding an efficient approach based on certain observations remains difficult.






























 9+ registered
9+ registered 

