Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Generally, a checkpoint is an obstacle or a barrier required to perform various security checks. In DBMS, a checkpoint's meaning differs from a usual checkpoint. The Checkpoint in DBMS is an exemplary process of compressing the transaction log file. It moves the current transaction into permanent storage(disk storage).
In this article, we will learn about a checkpoint in DBMS
What is a Checkpoint in DBMS?
A Database management system (DBMS) checkpoint is a vital process that swiftly saves the database's current state to disk, enabling efficient recovery after system failures or crashes.
It removes the previous transaction records from the system by permanently saving them on the disk. When a transaction hits a checkpoint at that point, there will be an update operation in the database.
The most crucial feature of DBMS is the ACID property which is an acronym for Atomicity, Consistency, Integrity, and Durability. The checkpoint in DBMS helps maintain the ‘C’ part of the database, Consistency.
The syntax of a checkpoint in DBMS is as follows:
checkpoint [ interval_for_checkpoints ];
Why do we need Checkpoints?
A checkpoint in DBMS ensures consistency in the database. They guarantee consistency in the instance of hardware breakdowns or crashes. When the large size of the log databases makes it difficult to handle, Checkpoints come into action and compress the size of the log files.
The compression method involves transferring log files to permanent memory, generally disk storage. A checkpoint in dbms is an essential component for the recovery system of a database.
For example, the checkpoints are very important in the transactions process. If the transaction of a person fails at some point the process of rollback takes place with the help of checkoints. The checkpoint keeps track of the process starting from the begnig of the transaction to the commit or abort of the process.
Steps to Use Checkpoints in the Database
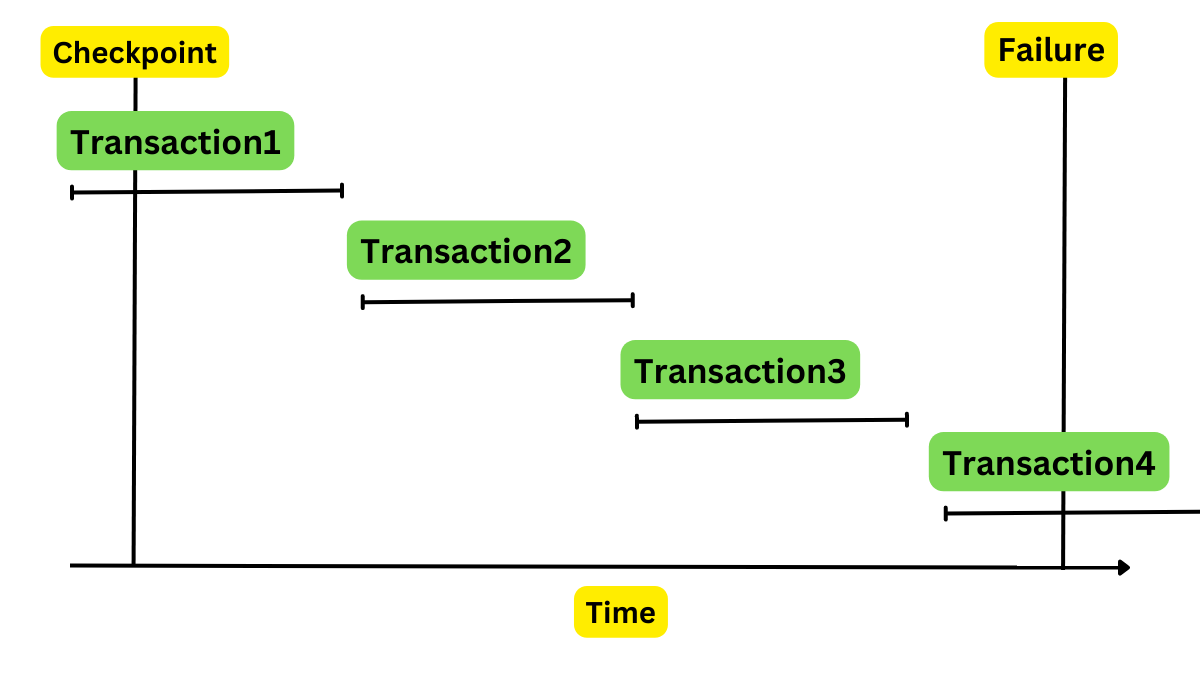
Let’s understand how a checkpoint in DBMS works using the following diagram:
The recovery manager system of the server uses the checkpoints to recover system crashes and data loss of failed transactions.
Here, four transactions are shown. Let’s consider T1, T2, T3 and T4. The recovery system in this checkpoint will read all the transactions from T1 to T4 to create a log from start to end.
There will be two lists: the REDO list and UNDO list. The recovery mechanism keeps separate lists for redoing and undoing.
In log files, all the transactions will have <T, start> and <T, commit>.
If the recovery system discovers all log files and the transactions with <T N, commit> or <T N, start> and <T N, commit>, they are stored in the redo list and deleted after saving log files.
As we can see in the example, the log files of the different transactions will have the following operations:
Transaction 1: <T, start>
Transaction 2: <T, start> and <T, end>
Transaction 3: <T, start> and <T, end>
Transaction 4: <T, end>
So, the system stores T1, T2, and T3 in the REDO list. As you can see, there is no commit operation for the transaction T4 in the checkpoint interval. So, the system stores T4 in UNDO list.
Types of Checkpoints in DBMS
There are basically two main types of Checkpoints:
Automatic Checkpoint
Manual Checkpoint
1. Automatic Checkpoint
As the name suggests, automatic checkpoints are created by database servers automatically for each database. Automatic checkpoint doesn’t require any user-defined target recovery time. When there is about 70% or more content in the log, the recovery approach of the system generates an automatic checkpoint. These are useful for large databases.
The checkpoint is automatic if:
If(Number of log records == Number of DB engine estimation)
{
return (Automatic checkpoint = True);
}
The code, as mentioned earlier, is just for the sake of understanding. It is generally representing the state of an automatic checkpoint. It means an automatic checkpoint occurs when the number of database engine estimations and log records is the same.
The number of checkpoints: The recovery interval advanced server setup option can determine the number of automatic checkpoints for a particular system.
Time interval: The interval time of an automatic checkpoint can vary for different transactions.
The sp_configurre T-SQL command to configure the recovery interval value is as follows:
USE [master]
GO
EXEC sp_configure 'show advanced options', 1;
GO
RECONFIGURE
GO
EXEC sp_configure 'recovery interval', 0
GO
RECONFIGURE
GO
2. Manual Checkpoint
It is an optional checkpoint in DBMS. Using the checkpoint T-SQL command, one can explicitly use it to input internal time.
The number of checkpoints: An user can decide the number using some SQL queries.
Time interval: The interval time for a manual checkpoint depends on the following:
The user input determines the interval when the user provides it.
If the users do not specify the interval time for a manual checkpoint, it depends on how many dirty pages the operation writes.
The following T-SQL command will form a manual checkpoint in DBMS for a maximum of 20 seconds.
CHECKPOINT 20
Recovery using Checkpoint in DBMS
In Database Management Systems (DBMS), a checkpoint is a mechanism used to ensure database consistency and facilitate recovery in case of system failures. During normal database operations, changes are made to the database's buffers in memory. These changes are eventually written to the disk, but until they are, they exist only in memory and are vulnerable to loss in case of a system crash or failure.
Checkpoint Process: Periodically, the DBMS initiates a checkpoint process where it flushes all modified data from the buffer pool to the disk. This ensures that the changes made to the database are permanently stored on disk, reducing the risk of data loss in the event of a failure.
Transaction Log: Before performing a checkpoint, the DBMS writes a record of all transactions that have been committed but not yet flushed to disk, known as the transaction log. This log allows the system to recover the database to a consistent state by replaying the transactions recorded in the log since the last checkpoint in case of a failure.
Database Recovery: In the event of a system crash or failure, the DBMS can use the transaction log to recover the database to a consistent state. It starts by applying the transactions recorded in the log since the last checkpoint, bringing the database up to the state it was in before the failure occurred. This ensures data integrity and consistency.
Performance Impact: While checkpoints are essential for ensuring data durability and recovery, they can also have a performance impact. Performing frequent checkpoints may cause overhead and slow down database operations. Therefore, the frequency of checkpoints is typically determined based on factors such as system reliability requirements and performance considerations.
Tuning Parameters: DBAs can tune checkpoint parameters such as the interval between checkpoints and the size of the transaction log to optimize performance and recovery capabilities based on the specific requirements of the application and system environment.
Real-time applications of Checkpoint in DBMS
Some real-time application of Checkpoint in DBMS are:-
Lock system of Databases: Checkpoints are used in the Shared or Exclusive lock systems of the databases.
Backup and recovery system: A checkpoint in dbms is also used for the backup of databases and recovery of the databases from crashes.
Banking- Systems: A checkpoint captures the information in the transaction log and helps to maintain the integrity of the log databases.
Optimized Performance of Storage: Checkpoints can also be used to enhance performance by minimizing the quantity of time and storage required during recovery.
Advantages of Checkpoints
The advantages of a checkpoint in DBMS are as follows:
Faster System: Using a checkpoint in the Database results in the faster processing of many transactions at once.
Recovery: A checkpoint in DBMS can help us recover our data or transaction data when a sudden system shutdown occurs.
Simple: The recovery system of the checkpoints is simpler and easy to implement in the recovery system servers.
Prevents unnecessary operations: Checkpoints in log files stop unnecessary redo actions resulting in a minimised execution time.
Decrease I/O cost: By minimising the input-output operations of the data, a checkpoint in the database minimises the overall cost of the system.
Disadvantages of Checkpoints
While checkpoints play a crucial role in system recovery, they also have some disadvantages that should be considered. Here are some of the drawbacks of using checkpoints:
Increased overhead: Checkpoints require additional resources, such as disk space and processing power, to create and maintain backup copies of data or transaction logs.
Longer recovery time: The process of restoring data from checkpoints can be time-consuming, especially if the system has a large amount of data or complex recovery requirements.
Data loss potential: In case of a failure occurring between checkpoints, there is a possibility of losing some data that was not yet backed up in the latest checkpoint.
Impact on system performance: Creating checkpoints and managing recovery processes can impact the performance of the system, especially during peak usage periods.
Limited granularity: Depending on the frequency of checkpoints, there may be a limit to the granularity of recovery.
Frequently Asked Questions
What is the use of checkpoints?
Checkpoints in DBMS ensure data durability by flushing modified data from memory to disk periodically. They facilitate recovery in case of system failures by providing a consistent state of the database.
What is checkpoint vs savepoint in DBMS?
A checkpoint in DBMS flushes modified data from memory to disk to ensure data durability and facilitate recovery in case of failures. A savepoint is a point within a transaction where you can roll back to if necessary. It allows you to partially commit transactions and handle errors gracefully.
What do you mean by checkpointing?
Checkpointing refers to the process of periodically flushing modified data from memory to disk in a Database Management System (DBMS). It ensures data durability and facilitates recovery in case of system failures by providing a consistent state of the database.
What is an example of a checkpoint?
An example of a checkpoint in DBMS is a periodic process where the system flushes modified data from memory to disk, ensuring data durability and facilitating recovery in case of system failures. For instance, a DBMS might perform a checkpoint every 10 minutes to ensure data consistency.
Conclusion
In this article, we extensively discussed checkpoints in DBMS. Checkpoints play a crucial role in ensuring data durability and facilitating recovery in DBMS. By periodically flushing modified data from memory to disk, they help maintain data consistency and integrity.






























 6+ registered
6+ registered 

