Steps for Building a Classifier
The building of a classification model consists of two steps.
-
Learning Step (Training Phase):
The learning step is where you train the algorithms to produce the desired results. The input parameters are available during the learning phase. We have the model's settings and the input data. We are teaching the algorithm something new. The algorithm changes the training parameters during training. It also alters the input data before producing an output.
-
Classification Step (Testing Phase)
In this step, the model predicts class labels and evaluates the built model on test data to estimate the classification rules' accuracy.
Classifiers in Machine Learning
Classification is an important data mining technique. So, we have various classification methods in machine learning.
- Decision Trees
- Artificial Neural Networks
- K-Nearest Neighbour
- Bayesian Classifiers
- Support Vector Machines
- Logistic Regression
- Linear regression
Now, we will discuss all these classification models in more detail and understand how they are used to classify data.
Decision Trees
A decision tree is used to solve both classification and regression problems. But it is most commonly employed to solve classification issues.
- Internal nodes represent dataset attributes, branches represent decision rules, and each leaf node provides the conclusion in this tree-structured classifier.
-
A decision tree is based on the idea that it asks a question and divides the tree into subtrees based on the answer (Yes/No).
A decision tree's general structure is shown in the diagram below:
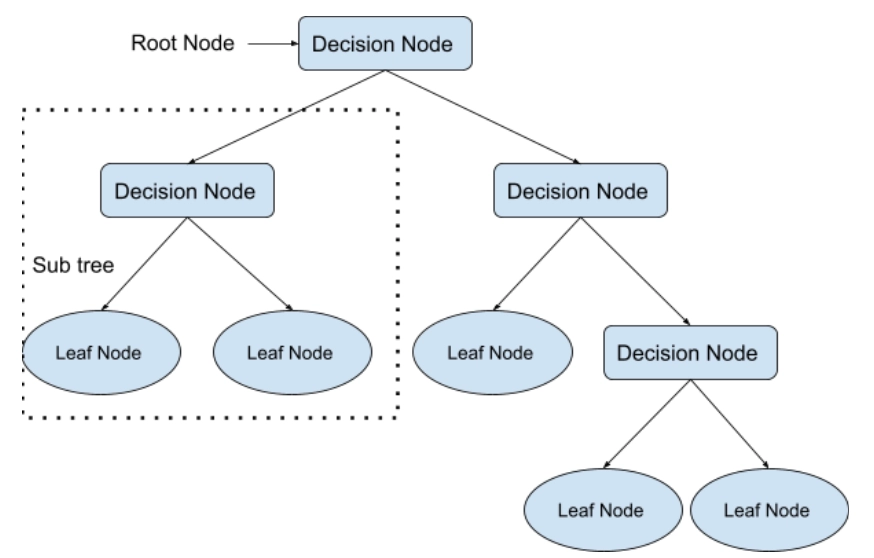
(Diagram representing a decision tree)
Artificial Neural Networks
Neural networks are models that mimic the operation of the human brain. The human brain is a neural network made up of many neurons, while the artificial neural network comprises many perceptrons.

(Diagram representing Artificial Neural Network)
The following are the three primary layers of a neural network:
-
The Input Layer
The input layer is responsible for accepting all of the programmer's inputs.
-
Hidden Layer
There are hidden layers on which computations are done, resulting in the output between the input and output layers.
-
Output Layer
After passing through the hidden layer, the input layer undergoes a series of modifications, resulting in an output shown by the output layer.
K-Nearest Neighbour
Nearest-neighbour classifiers work by comparing a given test tuple to training tuples similar to it or learning by analogy.
- There are n attributes that characterise the training tuples. Each tuple represents an n-dimensional point in space.
- All of the training tuples are stored in n-dimensional pattern space.
- A k-nearest-neighbour classifier explores the pattern space for the k training tuples closest to the unknown tuple when given an unknown tuple.
- These k training tuples are the unknown tuple's k closest neighbours.
- Closeness is measured using distance metrics such as Euclidean, Manhattan, Minkowski, Hamming, etc.

(Digram showing K-NN classifier)
Bayesian Classifier
The Bayes' Theorem is the foundation of Bayesian classification. Bayesian classifiers are statistical classifiers, i.e., they are based on statistical concepts such as probability. Bayesian classifiers can estimate class membership probabilities, such as the likelihood that a given tuple belongs to a specific class.
Baye’s Theorem
Bayes' Theorem is named after Thomas Bayes, who proposed the theorem. There are two kinds of probability:
- [P(H/X)] - Posterior Probability
- [P(H)] - Prior Probability
Here, X is a tuple of data and H is a hypothesis.
The Bayes' Theorem states that P(H/X)=P(X/H)P(H)/P(X)
Support Vector Machines
A support vector machine (SVM) is a supervised learning technique that is used to solve classification and regression problems. It is, however, mainly employed to solve classification problems. SVM is used to create a decision boundary or hyperplane that can be used to divide datasets into several classes. The data points that help define the hyperplane are called support vectors, and the method is called a support vector machine.
- If two labelled data sets a and b to exist, the data from class a should be in one of them.
- The longer the distance, the more the hyperplane's side and label b's side will be present on the opposite side or class.

(Diagram of Support Vector Machine)
Linear Regression
One of the most common and straightforward machine learning algorithms for predictive analysis is linear regression. We use linear regression to predict continuous numbers like salaries, age, etc.
- It shows the linear relationship between the dependent and independent variables and how the dependent variable (y) changes when the independent variable changes (x).
- It aims to determine the regression line, the best fit line between the dependent and independent variables.
Types of Linear Regression
There are two types of linear regression as follows:
-
Simple Linear Regression
In simple linear regression, we use a single independent variable to predict the value of the dependent variable.
-
Multiple Linear Regression
In multiple linear regression, we use multiple independent variables to predict the value of the dependent variable.
Logistic Regression
We use logistic regression to model the probability of a specific event or class. A logistic model is used to model a binary dependent variable. It calculates the chances of a single experiment. Although logistic regression assists you in understanding the impact of several independent variables on a single outcome variable, it was primarily created for classification.
- Logistic regression is analogous to linear regression, which is used to solve the classification problem and predict discrete values. In contrast, we use linear regression to solve the regression problem and predict continuous values.
- A categorical dependent variable's output is predicted using logistic regression. As a result, the result must be a discrete or categorical value. It can be Yes or No, 0 or 1, true or false, and so on, but instead of giving exact values like 0 and 1, it delivers probabilistic values somewhere between 0 and 1.
Real-Life Applications
So, in the previous section, we learned about classification techniques in data mining. But what can this machine learning algorithm help us accomplish with real-world data? Below, we discuss the real-life applications of classification analysis.
-
Classifying Spam Emails
Email spam classification is one of the most prevalent uses of the classification technique since it works continuously and requires no human interaction. It saves us from laborious deletion jobs and even costly phishing fraud.
-
Sentiment Analysis
Sentiment analysis is a machine learning text analysis technique that assigns sentiment (opinion, feeling, or emotion) to individual words or full texts on a positive, negative, or neutral polarity scale. It can read hundreds of pages in minutes or constantly monitor social media for updates about you.
-
Image Recognition
A given image is assigned to previously trained categories through image classification. These could be the image's subject, a numerical value, or a theme. Multi-label image classifiers, which work similarly to multi-label text classifiers, can be used to tag an image of a stream with different labels, such as "stream," "water," "outdoors," and so on.
-
Prediction of Customer Churn
A binary classification model can predict if a client will churn soon. The customer churn classification model is used in various business scenarios, including up-selling and cross-selling to existing customers, detecting at-risk accounts in a customer base, and so on. Telecommunications businesses are increasingly using machine learning classification models to anticipate attrition.
Also see, Data Warehouse
Frequently Asked Questions
Can you describe data classification with a real-life example?
Classification is the process of grouping data into homogeneous groups or classes based on some common qualities found in the data. Consider the following scenario: Letters are sorted according to cities and then placed according to streets during the sorting process at the post office.
What are some of the uses of data mining?
Applications for Data Mining include:
- Analysing Financial Data
- Industry of Telecommunications
- Analysing Biological Data
-
Other Scientific Uses
What is the difference between clustering and classification?
Although both procedures have certain similarities, the distinction is that classification assigns objects to predetermined classes. In contrast, clustering discovers similarities between objects and groups them according to common characteristics that distinguish them from others.
In data mining, what is an outlier?
An outlier is a data object that differs significantly from the rest of the data objects and behaves uniquely. An outlier is a unique object that stands out from the rest of the group.
Conclusion
This article extensively discussed classification analysis in data mining and various classification models such as decision trees, artificial neural networks, K-Nearest Neighbours, Bayesian Classifiers, Support Vector Machines, Logistic Regression, and Linear Regression. These basic classification analysis concepts can help you better understand Data Mining and enhance your interest in studying Machine Learning.
We hope that this blog has helped you enhance your knowledge regarding Classification analysis and if you would like to learn more, check out our articles on ‘Types of Data Mining Techniques,’ ‘Python in Data Mining,’ ‘Top 10 common data mining algorithms,’ ‘Data Mining vs Data Warehousing’ and ‘Data Mining Vs Data Analytics’. Do upvote our blog to help other ninjas grow.
Head over to our practice platform Coding Ninjas Studio to practice top problems, attempt mock tests, read interview experiences, interview bundle, follow guided paths for placement preparations and much more!
Happy Reading!





























 9+ registered
9+ registered 

