Do you think IIT Guwahati certified course can help you in your career?
Introduction
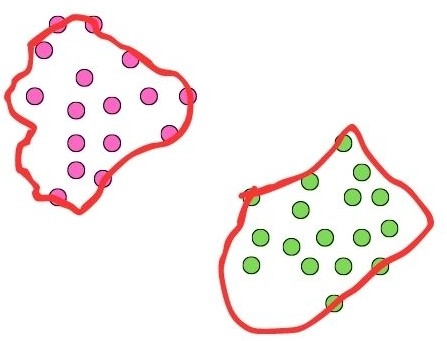
Clustering in machine learning involves grouping similar data points together to discover inherent patterns or structures within unlabeled datasets. It aims to partition data into subsets, or clusters, where data points in the same cluster are more similar to each other than those in other clusters. This unsupervised learning technique is widely used in various domains such as customer segmentation, image segmentation, and anomaly detection.
There are two machine learning approaches, i.e., supervised and unsupervised. When we don’t have a labelled dataset, we use unsupervised learning. It identifies any hidden patterns in the dataset that can be meaningful for future purposes. Clustering is one such method for the given purpose.
When we get an unlabelled dataset, we apply clustering algorithms and group the data points into clusters based on their given features. This means data points of the same group will have more similarities than those of different groups.
As the dataset is unlabelled, we cannot obtain any result about a data point except for the similarities in the features.
Example
Imagine you have a dataset containing information about customers based on their purchasing behaviors. This dataset includes features like age, income, and spending habits. Using clustering algorithms, such as K-means clustering, you can group similar customers together into clusters. For instance, one cluster might include young customers with high incomes who spend on luxury items, while another might include older customers with moderate incomes who prefer practical purchases.
By clustering the data, you can uncover segments of customers with similar characteristics, which can then be used for targeted marketing strategies, personalized recommendations, or understanding customer preferences better. This approach helps businesses make data-driven decisions and improve customer satisfaction by tailoring products and services to specific customer segments identified through clustering.
Types of Clustering Methods
There are five different types of clustering methods. They are broadly divided into two groups: hard and soft clustering methods (if the process uses fuzzy logic, it is a soft clustering method).
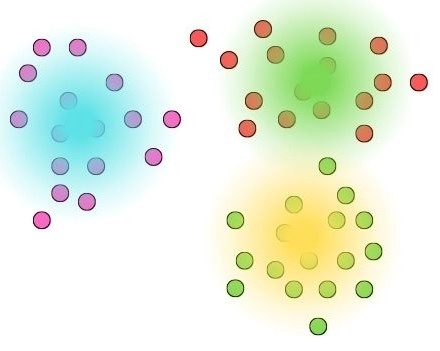
Density Based Clustering
Density-based clustering algorithms connect regions of high data points (high density) to form clusters. In this clustering, arbitrary-shaped distributions exist as long as dense areas can be connected, so regions with different densities are isolated. This clustering is unsuitable when dealing with data exhibiting varying densities and high-dimensional spaces.
Additionally, it is essential to note that these algorithms are not designed to assign outliers to specific clusters. OPTICS and DBSCAN are the most common examples of the given clustering.
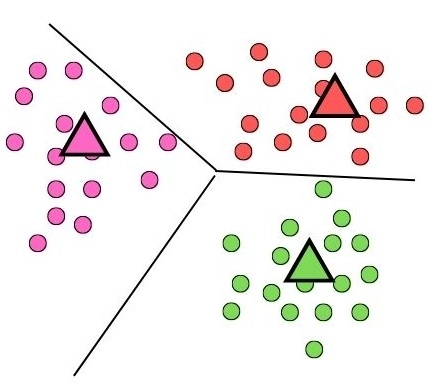
Centroid Based Clustering
Centroid-based clustering algorithms group data into k clusters by choosing k centroid data points. Among centroid-based algorithms, k-means is the most commonly used algorithm.
These algorithms are efficient regarding computational complexity but can be sensitive to initial conditions and outliers. It is also known as partitioning clustering.
Distribution Based Clustering
This clustering method is used when the data follows a specific distribution, such as the Gaussian distribution. As the distance from the centre of a distribution increases, the probability of the data point belonging to that distribution decreases.
If the distribution type in the data is unknown, it is recommended to apply a different algorithm. Mean Shift and Expectation maximisation algorithms are the most common examples of the given clustering.
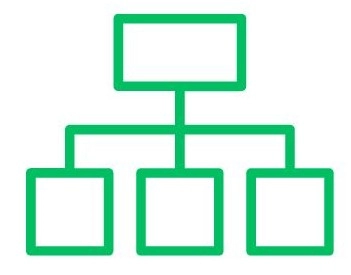
Hierarchical Clustering
It is an alternative to centroid-based clustering methods. It eliminates the need to specify the number of clusters in advance. This technique divides the dataset into groups, creating a tree-like structure known as a dendrogram. One can select the desired number of clusters or individual observations by pruning the tree at an appropriate level.
The Agglomerative Hierarchical algorithm is a widely used example of this approach. It provides flexibility in cluster selection and allows for a comprehensive exploration of the data's inherent structure.
Fuzzy Clustering
Fuzzy clustering is a soft clustering approach where data objects can belong to multiple clusters simultaneously. Unlike traditional hard clustering methods, fuzzy clustering assigns membership coefficients to each data point, indicating each cluster's membership degree. The membership coefficients reflect the likelihood or probability of a data point belonging to a specific group. The fuzzy c-means algorithm is a famous example of fuzzy clustering.
What is Clustering Algorithms?
Clustering algorithms are techniques used in machine learning to partition a dataset into groups, or clusters, of similar data points. These algorithms aim to find natural groupings in data based on similarity metrics, such as distance or density. Popular clustering algorithms include K-means, hierarchical clustering, DBSCAN, and Gaussian mixture models. They are widely used for tasks like customer segmentation, image segmentation, and anomaly detection in various fields.
Popular Clustering Algorithms
There are several clustering algorithms. They are used according to the problem statement and suitable dataset.
K-means Clustering
The k-means algorithm is widely recognised as one of the most popular clustering algorithms. It partitions a dataset into distinct clusters of roughly equal variances. One crucial requirement for using this algorithm is specifying the desired number of groups in advance. One of the critical advantages of k-means is its computational efficiency, as it requires relatively few computations. Its time complexity is linear, specifically O(n), making it efficient for handling large datasets.
DBSCAN Clustering
DBSCAN, or Density-Based Spatial Clustering of Applications with Noise, is a density-based clustering algorithm that shares similarities with mean shift but offers several notable advantages. DBSCAN divides the data into regions of high density, which are separated by regions of low density. This unique characteristic allows DBSCAN to identify clusters of arbitrary shapes, as it does not rely on predefined cluster shapes. Additionally, DBSCAN can handle noise points and does not force every data point to be assigned to a cluster.
Mean Shift Clustering
The mean-shift algorithm is a centroid-based model that aims to identify dense regions within the distribution of data points. It operates by iteratively updating the candidate centroids to the centre of the points within a defined region. By gradually shifting the centroids towards the areas of the highest data density, mean-shift effectively locates the modes or peaks of the underlying data distribution. This algorithm is particularly useful for clustering data with complex and irregular density patterns.
Applications of Clustering
There are several applications of clustering; Let's discuss them.
Customer Segmentation
Clustering is widely used in marketing to segment customers based on their behaviour, preferences, and purchasing patterns. By clustering customers into groups, businesses can create more effective marketing strategies.
Image Processing
Clustering algorithms are employed in image and document analysis to automatically categorize and organize large volumes of unstructured data. They make searching tasks easier.
Sports Analysis
It is used to group players with the same abilities to identify a team’s strengths and weaknesses. It can help in deducing effective strategies for a game.
Cybersecurity
Clustering algorithms can help detect and prevent cyber threats by detecting the threatening behaviour of potential attackers, as they are different from normal behaviour patterns.
Bioinformatics
Clustering techniques are extensively used in genetics and bioinformatics to analyze genomic data and identify genetic patterns or similarities. They are primarily used to identify proteins or other biological samples.
Frequently Asked Questions
What is clustering and its types?
Clustering in data analysis is the grouping of similar data points into clusters or categories. Types include:
K-Means Clustering: Divides data into K clusters based on distance.
Hierarchical Clustering: Forms a hierarchy of clusters through merging or splitting.
DBSCAN: Identifies dense areas and outliers.
Agglomerative Clustering: Starts with individual data points and merges them.
Mean Shift Clustering: Adapts cluster shapes based on data density.
What are the applications of clustering in machine learning?
Some of the applications of clustering in machine learning are:
Customer Segmentation for marketing.
Document grouping in natural language processing.
Anomaly detection in cybersecurity.
Image segmentation for object recognition.
What is clustering best used for?
Clustering is best used for grouping similar data points together, uncovering patterns or structures within data, and identifying natural divisions in a dataset. It's valuable for tasks like customer segmentation, anomaly detection, and pattern recognition in various domains.
What is the purpose of clustering?
Clustering aims to identify natural groupings in data based on similarity, helping to uncover patterns, segment data, and understand relationships between data points.
What is the main advantage of clustering?
The main advantage of clustering is its ability to reveal hidden patterns and structures in data without needing prior labels, enabling insights for decision-making, segmentation, and understanding complex relationships.
What are the three types of clusters?
The three types of clusters are:
Exclusive Clustering: Each data point belongs to exactly one cluster.
Overlapping Clustering: Data points can belong to multiple clusters.
Hierarchical Clustering: Clusters are organized in a tree-like structure based on similarity levels.
Conclusion
In this article, we discussed clustering in machine learning. We also saw different methods of clustering and some popular clustering algorithms. No hard and fast rules tell us which algorithm will work best on which problem. The best algorithms are always selected after training and comparing results from different algorithms.
For more knowledge about machine learning, read our other related articles:































 9+ registered
9+ registered 

