Approach #1
✨ There can be different approaches to solve the above problem. The most simple and basic approach is to traverse one of the trees and while traversing search the node in another BST
Pseudocode
PRINT_COMMON_NODES(TREE1, TREE2){
IF TREE2 is Null:
return;
PRINT_COMMON_NODES(TREE1, TREE2->left);
if TREE2->data is present in TREE1:
print TREE2->Data;
PRINT_COMMON_NODES(TREE1, TREE2->right);
}
Implementation in C++
#include <bits/stdc++.h>
using namespace std;
// Node
class Node
{
public:
int data;
Node *left, *right;
Node(int val)
{
data = val;
left = right = nullptr;
}
};
// function to search the node in bst
bool isPresent(Node* root, int val){
if(!root) return false;
if(root->data == val) return true;
if(root->data > val) return isPresent(root->left, val);
else return isPresent(root->right, val);
}
// function to print common nodes
void printCommonNodes(Node* tree1, Node* tree2){
if(!tree2) return;
// if the current node is present is tree1
// print that node and continue
printCommonNodes(tree1, tree2->left);
if(isPresent(tree1, tree2->data)) cout << tree2->data << ' ';
printCommonNodes(tree1, tree2->right);
}
// main function
int main()
{
// tree1
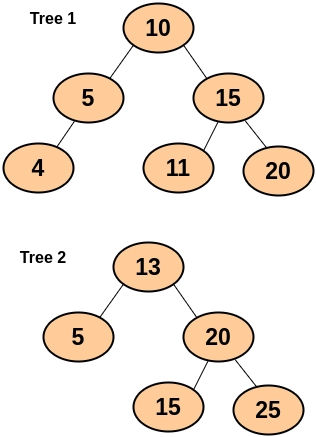
Node *tree1 = new Node(10);
tree1->left = new Node(5);
tree1->left->left = new Node(4);
tree1->right = new Node(15);
tree1->right->left = new Node(11);
tree1->right->right = new Node(20);
// tree 2
Node *tree2 = new Node(13);
tree2->left = new Node(5);
tree2->right = new Node(20);
tree2->right->left = new Node(15);
tree2->right->right = new Node(25);
// printing the result
cout << "Common Nodes: ";
printCommonNodes(tree1, tree2);
cout << endl;
return 0;
}

You can also try this code with Online C++ Compiler
Output
Common Nodes: 5 15 20
Time Complexity
⏱️ Searching in BST takes O(h) time, where h is the height of the tree. In the above approach, we are traversing the tree and while traversing we are searching the node in another BST. So, the time complexity of the above algorithm is O(N * h), Where N is the number of nodes in the second tree and h is the height of the first BST.
Space Complexity
💻 The space complexity of our algorithm is O(H1 + H2), Where H1 is the height of the first BST and H2 is the height of the second BST.
Approach #2
💫 In this approach, we will be using two different arrays As we know inorder traversal of a binary search tree is always in sorted order. So, we can save inorder traversal of both the binary search trees in two different arrays as these arrays would be sorted so we can easily find the common elements by finding the intersecting elements in both of the arrays.
Algorithm
-
Get the inorder traversal of both the BSTs and store it in two different arrays.
-
Find the intersecting elements between two different arrays.
-
Initialize an intersecting elements array that will store the intersecting elements.
-
Initialize two variables i, j with 0 value.
-
If the value of arr1[i] is equal to the value of arr2[j], then increment both i, and j by 1 and also push the current element into intersecting elements array.
-
If the value of arr1[i] is smaller than the value of arr2[j], then increment i by 1.
-
Else increment j by 1
-
Print the intersecting elements.
Implementation in C++
#include <bits/stdc++.h>
using namespace std;
// Node
class Node {
public:
int data;
Node *left, *right;
Node(int val) {
data = val;
left = right = nullptr;
}
};
// function for saving inorder traversal
// into an array
void saveInorder(Node* root, vector<int> &arr){
if(!root) return;
saveInorder(root->left, arr);
arr.push_back(root->data);
saveInorder(root->right, arr);
}
// function to find the insercting elements
// between two arrays
vector<int> findIntersection(vector<int> arr1, vector<int> arr2){
vector<int> commonNodes; // total number of intersecting elements
// finding intersecting elements
int i = 0, j = 0;
while(i < arr1.size() && j < arr2.size()){
if(arr1[i] == arr2[j]){
commonNodes.push_back(arr1[i]);
i++;
j++;
}
else if(arr1[i] < arr2[j]) i++;
else j++;
}
// returning total intersecting elements
return commonNodes;
}
// main function
int main(){
// tree1
Node *tree1 = new Node(10);
tree1->left = new Node(5);
tree1->left->left = new Node(4);
tree1->right = new Node(15);
tree1->right->left = new Node(11);
tree1->right->right = new Node(20);
// tree 2
Node* tree2 = new Node(13);
tree2->left = new Node(5);
tree2->right = new Node(20);
tree2->right->left = new Node(15);
tree2->right->right = new Node(25);
// storing inorder elements of tree1
vector<int> arr1;
saveInorder(tree1, arr1);
// storing inorder elements of tree2
vector<int> arr2;
saveInorder(tree2, arr2);
// getting intersecting elements
vector<int> commonNodes = findIntersection(arr1, arr2);
// printing the result
cout << "Common Nodes: ";
for(int i : commonNodes){
cout << i << " ";
}
cout << endl;
return 0;
}
You can also try this code with Online C++ Compiler
Output
Common Nodes: 5 15 20
Time Complexity
⏱️ As we need to traverse both of the trees so the time complexity of the above program is O(N+M). Where N is the number of nodes in the first BST and M is the number of nodes in the second BST.
Space Complexity
💻 We are using two different arrays to store the inorder traversal of both the BSTs. So the space complexity of the above approach is O(N + M), Where N is the number of nodes in the first BST and M is the number of nodes in the second BST.
Approach #3
The above approach is working fine but the problem is we are using two different arrays to store the inorder traversal of both the trees however it is not necessary to store the inorder traversal.
🌟 We can use iterative inorder traversal and while traversing we can keep track of a certain branch of the tree and then begin comparing.
⭐ We can use two different stacks to store the inorder traversal but the condition here is at any point in time the max number of nodes in our stack should be equal to or smaller than the height of the tree. After that, we start comparing the elements of both stacks one by one.
Pseudocode
PRINT_COMMON_NODES(Node1, Node2)
{
STACK1, STACK2;
while true:
IF Node1 is not Empty:
s1.push(Node1);
Node1 = Node1->left;
ELSE IF Node2 is not Empty:
s2.push(Node2);
Node2 = Node2->left;
ELSE IF Stack1 and Stack2 are not empty:
Node1 = s1.top();
Node2 = s2.top();
IF Node1 is equal to Node2
print Node
Stack1.pop();
Stack2.pop()
Node1 = Node1->right;
Node2 = Node2->right;
ELSE IF Node1 is smaller than Node2
Stack1.pop()
Node1 = Node1->right;
Node2 = NULL;
ELSE IF Node1 is greater than Node2
s2.pop();
Node2 = Node2->right;
Node1 = NULL;
ELSE break;
}
Implementation in C++
#include <bits/stdc++.h>
using namespace std;
// Node
class Node
{
public:
int data;
Node *left, *right;
Node(int val)
{
data = val;
left = right = nullptr;
}
};
// function to print common nodes
void printCommonNodes(Node *tree1, Node *tree2)
{
// Create two stacks for two inorder traversals
stack<Node*> s1, s2;
while (true)
{
// pushing the Nodes of first tree in stack1
if (tree1)
{
s1.push(tree1);
tree1 = tree1->left;
}
// pushing the Nodes of second tree in stack2
else if (tree2)
{
s2.push(tree2);
tree2 = tree2->left;
}
// checking the stack
else if (!s1.empty() && !s2.empty())
{
tree1 = s1.top();
tree2 = s2.top();
// If current node in two trees are same
if (tree1->data == tree2->data)
{
cout << tree1->data << " ";
s1.pop();
s2.pop();
// move to the inorder successor
tree1 = tree1->right;
tree2 = tree2->right;
}
else if (tree1->data < tree2->data)
{
// If Node of first tree is smaller, then there's a chance that tree1 can have same value
// as that of the second tree Node. Thus, we pop from s1
s1.pop();
tree1 = tree1->right;
// as we need new node of tree1 so setting the tree2 as null
tree2 = NULL;
}
else if (tree1->data > tree2->data)
{
s2.pop();
tree2 = tree2->right;
tree1 = NULL;
}
}
// successfully traversed the whole tree
else break;
}
}
// main function
int main()
{
// tree1
Node *tree1 = new Node(10);
tree1->left = new Node(5);
tree1->left->left = new Node(4);
tree1->right = new Node(15);
tree1->right->left = new Node(11);
tree1->right->right = new Node(20);
// tree 2
Node *tree2 = new Node(13);
tree2->left = new Node(5);
tree2->right = new Node(20);
tree2->right->left = new Node(15);
tree2->right->right = new Node(25);
// printing the result
cout << "Common Nodes: ";
printCommonNodes(tree1, tree2);
cout << endl;
return 0;
}
You can also try this code with Online C++ Compiler
Output
Common Nodes: 5 15 20
Time Complexity
⏱️ As we are traversing both the BSTs. So the time complexity of the above approach is O(N+M). Where N is the number of nodes in the first BST and M is the number of nodes in the second BST.
Space Complexity
💻 We are using two different stacks to store the branches of both the BSTs. So the space complexity of the above approach is O(H1 + H2), Where H1 is the height of the first BST and H2 is the height of the second BST.
Check out this problem - Connect Nodes At Same Level
Frequently Asked Questions
What is a binary search tree?
A Binary search tree is a special kind of binary tree in which all the nodes having lesser values than the root node are kept on the left subtree, and similarly, the values greater than the root node are kept on the right subtree.
What is the difference between a graph and a tree data structure?
Both tree and graph are Hierarchical data structures. The difference is that in the graph data structure it is allowed to have cycles or self-nodes. However, we cannot have a cycle in the tree data structure.
Describe the time complexity of making insertions in a binary search tree.
In general, the time complexity of making insertions in a binary search is O(h), where h is the height of the BST. In case the tree is not balanced then the time complexity of insertion would be O(N), Where N is the number of nodes.
Conclusion
In this article, we have extensively discussed a coding problem in which we have to find and print the common nodes between two different BSTs. We have seen different approaches for solving the above problem.
If you think this blog has helped you enhance your knowledge about the above question, and if you would like to learn more, check out our articles
Recommended problems -
Visit our website to read more such blogs. Make sure that you enroll in the courses provided by us, take mock tests and solve problems and interview puzzles available. Also, you can pay attention to interview stuff- interview experiences and an interview bundle for placement preparations.
Please upvote our blog to help other ninjas grow.
Happy Learning!































 9+ registered
9+ registered 

