Do you think IIT Guwahati certified course can help you in your career?
Introduction
Pandas is an open-source Python library that provides powerful data manipulation and analysis tools commonly used in machine learning. It provides various data structures, such as Series and Dataframes, and methods for manipulating them.
In this article, you will learn how to concatenate and reshape data frames in Pandas.
Let’s get started.
What is a Data Frame?
A Dataframe is one of the core data structures provided by Pandas. It is a two-dimensional tabular data structure where data is organized into rows and columns. Each column can contain different data types, such as integers, floats, strings, etc.
Before moving forward, let's quickly see how you can install Pandas.
Installing Pandas
Run the following command in your terminal.
Bash
Bash
pip install pandas
Output
Now, let’s see an example of creating a dataframe in Pandas.
Python
Python
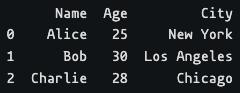
import pandas as pd
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 28],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
print(df)
You can also try this code with Online Python Compiler
Here we used the DataFrame() method to create a dataframe using a dictionary and printed it using the print() function.
Now, you will learn about the concatenate function in Pandas.
How to Concatenate DataFrames in Pandas?
Pandas provides the concat() function that allows you to combine multiple dataframes either vertically (along rows) or horizontally (along columns).
Let’s look at both ways of combining dataframes using the concat() function.
Vertical Concatenation
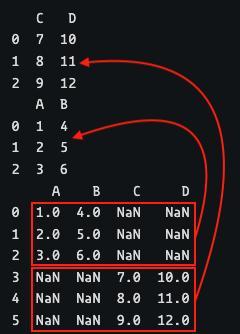
The concat() function performs vertical concatenation by default. You just have to pass an array containing the dataframes, and the function will return the resulting dataframe.
No missing values exist, as the dataframes have the same number of rows.
In the next section, you will learn about the various functions used for reshaping dataframes in Pandas.
How to Reshape DataFrames in Pandas?
Reshaping dataframes in Pandas involves transforming the layout of your data to make it compatible with your analysis needs.
Let’s look at the various ways of reshaping dataframes in Pandas.
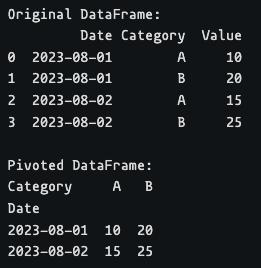
Pivoting
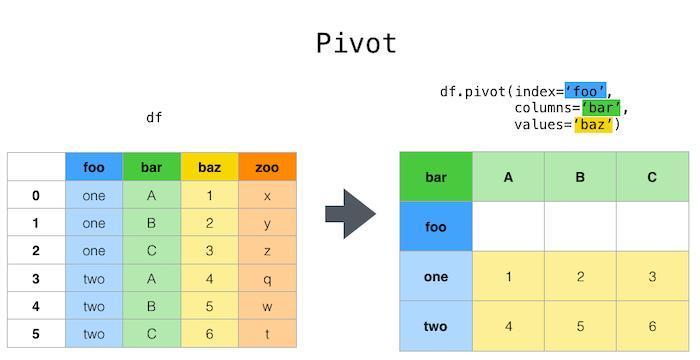
Pivoting is the process of transforming data from a long format to a wide format. The unique values in one column become the new columns, and the values under a different column populate the cells under these new columns.
Credit: pandas.pydata.org
Pandas provides the pivot() function for performing pivoting. It expects the following parameters:-
index: This parameter specifies the column whose unique values are used as the pivoted dataframe's row index.
columns: This parameter specifies the columns whose unique values are used for creating new columns in the pivoted dataframe.
values: This parameter specifies the columns whose values are used for filling the cells of the pivoted dataframe.
Here we used the Category for creating new columns and the Date columns for creating row indices.
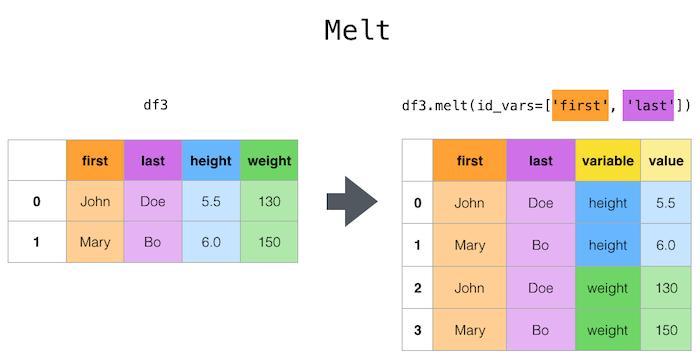
Melting
Melting is the process of transforming data from a wide format to a long format. It is also known as unpivoting. In this process, multiple columns are converted into a single column with the help of an additional column that captures the original column labels.
Credit: pandas.pydata.org
Pandas provides the melt() function for performing melting. It expects the following parameters:-
id_vars: This parameter specifies the columns that won't be melted. It can be a single column or multiple columns in an array.
var_name: This parameter specifies the name of the new column that will capture the original column labels. It defaults to “variable”.
value_name: This parameter specifies the name of the new column containing the values from the melted columns. It defaults to “value”.
Let’s see an example.
Python
Python
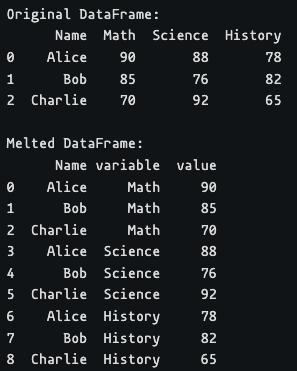
import pandas as pd
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Math': [90, 85, 70],
'Science': [88, 76, 92],
'History': [78, 82, 65]
}
df = pd.DataFrame(data)
print("Original DataFrame:")
print(df)
melted_df = df.melt(id_vars=['Name'])
print("\nMelted DataFrame:")
print(melted_df)
You can also try this code with Online Python Compiler
Here all columns except Name are melted. The variable column captures the name of the original column, and the value column stores the values from these melted columns.
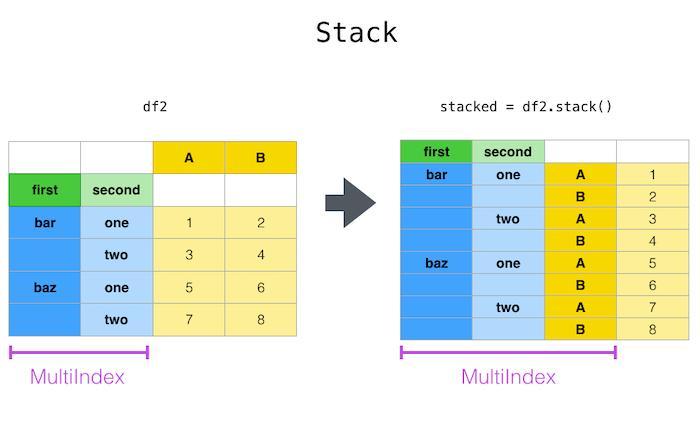
Stacking
Stacking is the process of pivoting a level of the column labels. It is commonly used in dataframes containing a multi-level column index.
Credit: pandas.pydata.org
Pandas provides the stack() function for performing stacking. It expects a single parameter that denotes the index of the nested column that you want to pivot. By default, this function pivots the innermost level.
Let’s see an example.
Python
Python
import pandas as pd
data = {
('Electronics', 'Q1'): [1000, 1500],
('Electronics', 'Q2'): [1200, 1800],
('Clothing', 'Q1'): [500, 800],
('Clothing', 'Q2'): [600, 950]
}
df = pd.DataFrame(data)
df.index = ['Region 1', 'Region 2']
df.columns.names = ['Category', 'Quarter']
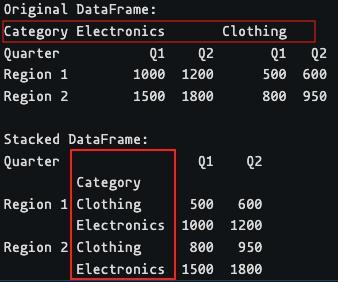
print("Original DataFrame:")
print(df)
stacked_df = df.stack(0)
print("\nStacked DataFrame:")
print(stacked_df)
You can also try this code with Online Python Compiler
There are two levels of column labels in the input dataframe. The topmost level has an index of 0, and we specified 0 while calling the stack() function, so it pivoted the topmost level of column labels.
Frequently Asked Questions
What is Series in Pandas?
A series is a one-dimensional labeled data structure that can hold data types such as numeric, string, boolean, etc. Each element in a series has a corresponding label called an index which may or may not be a numeric value.
What is NaN in Python?
In Python, NaN stands for “Not a Number, " a special floating point value used to represent undefined or unrepresentable numerical values. In Pandas, NaN represents missing values that arise from concatenation operations performed on dataframes.
What is a multi-level column index in Pandas?
It is a way to represent data in a dataframe using multiple levels of column labels, meaning each column has sub-columns. Using Pandas, you can perform various operations on dataframes containing multi-level column indices, such as slicing, stacking, aggregation, etc.
Conclusion
In this article, you learned how to install Pandas and concatenate and reshape dataframes in Pandas with the help of examples. We discussed vertical and horizontal concatenation along with 3 ways of reshaping dataframes - Pivoting, Melting, and Stacking.
Go through the following articles to learn more about Pandas:-

































 9+ registered
9+ registered 

