Do you think IIT Guwahati certified course can help you in your career?
Introduction
The confusion matrix is a fundamental concept in machine learning that helps evaluate classification models' performance. It is a table that summarizes the ratio of right and wrongly predicted outcomes of the model by comparing the predicted and actual labels in a dataset.
The confusion matrix provides valuable insights into the errors the model makes, which is used to adjust and improve the model's performance. Understanding the term "confusion matrix" and its significance in evaluating machine learning models is essential.
In a binary classification problem, the confusion matrix consists of four components: true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN).
True positives (TP)
True positives (TP) are the cases where the model correctly predicted the positive class (i.e., the actual class was positive, and the model predicted positive).
True negatives (TN)
True negatives (TN) are the cases where the model correctly predicted the negative class (i.e., the actual class was negative, and the model predicted negative).
False positives (FP)
False positives (FP) are the cases where the model predicted the positive class, but the actual class was negative.
False negatives (FN)
False negatives (FN) are the cases where the model predicted the negative class, but the actual class was positive.
We can perform various calculations for getting the performance of our model.
Accuracy measures how well a machine learning model can predict the correct answer. It calculates the number of right solutions divided by the number of answers given.
Accuracy measures how well the model predicts both the positive and negative classes. In the real world, accuracy is often used in scenarios where the classes are balanced and there are no significant differences in the cost of different types of errors.
Precision
Precision = (TP) / (TP+FP)
Imagine if you have a basket of apples and need to sort them into two groups: good apples and bad apples. You have a machine that helps you do this, but it could be better and sometimes makes mistakes.
Precision is like a measure of how good the machine is at sorting the good apples from the bad ones. If the machine says an apple is good, but it's bad, that's a mistake, and we don't want that to happen because we might eat a bad apple by accident.
So precision is a way to see how often the machine gets it right when it says an apple is good. The higher the precision, the more confident we can be that the machine is doing a good job of sorting the good apples from the bad ones.
Recall/Sensitivity/Hit-rate
Recall = (TP) / (TP+FN)
Imagine you have a bunch of toys in your room, and you need to find all the red toys. You search your room and find some red toys, but you might miss some or accidentally include some that need to be red.
The recall is like a measure of how good you are at finding all the red toys. If you find all the red toys, then your recall is 100%. But if you miss some red toys or accidentally include ones that aren't red, your recall will be lower.
So recall is a way to see how often you can find everything you want. The higher the recall, the more confident you can be that you're finding everything you need to find.
Specificity/Selectivity
Specificity = (TN) / (TN+FP)
Imagine playing a game of "guess who" with your friend, and you need to guess which character your friend picked.
Specificity measures how good you are at ruling out the characters your friend didn't pick. If you guess a character your friend didn't choose, that's good because you've ruled out one possibility.
So specificity is a way to determine how often you can correctly guess your friend didn't pick a certain character. The higher the specificity, the more confident you can be that you're ruling out the characters your friend didn't choose.
The F1 score is like a report card grade that measures how well you did on a test that has two important parts: answering questions correctly and not making too many mistakes.
Imagine you took a ten-question test and got 8 of them right. That's pretty good. But what if you also got four questions wrong? That's not so good.
The F1 score combines how many questions you got right (like precision) with how many mistakes you made (like recall) to give you an overall grade. If you got many questions right and didn't make many mistakes, your F1 score will be high, like an A on your report card. But if you got many questions right but made too many mistakes, your F1 score will be lower, like a B or C on your report card.
Why do we need different metrics?
Imagine you're playing a game with your friends and want to know the best player. You can measure who is the best player in different ways, depending on what you care about most.
For example, to measure who scores the most points, you might use a metric like "total points scored." But if you want to measure who is the most accurate shooter, you might use a metric like "percentage of shots made."
In the same way, when we're using machine learning to make predictions, there are different things we might care about, depending on what problem we're trying to solve. For example, suppose we're trying to predict whether a patient has a disease. In that case, we might care more about avoiding false positives (saying someone has the disease when they don't) than avoiding false negatives (saying someone doesn't have the disease when they do). So we might use a metric like precision, which measures how many of our positive predictions were correct.
Using different metrics, we can measure different aspects of our machine learning model's performance and choose the most important for the problem we're trying to solve.
CODE
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from sklearn.metrics import confusion_matrix,classification_report
# making a list of actual_values and predicted values
actual_values = [1, 1, 0, 1, 1, 0, 1, 1, 0]
pred_values = [1, 0, 0, 1, 1, 0, 1, 0, 0]
# using sklearn confusion matrix
conf_matrix = confusion_matrix(actual_values, pred_values, labels=[0, 1])
print('Confusion matrix : \n',conf_matrix)
# storing values of tp, tn, fp, fn
TP, FN, FP, FN = confusion_matrix(actual_values, pred_values,labels=[0,1]).reshape(-1)
print('Outcome values : \n', TP, FN, FP, FN)
# print the classification report
clf_rpt = classification_report(actual_values,pred_values,labels=[0,1])
print('Classification report : \n', clf_rpt)
You can also try this code with Online Python Compiler
This code demonstrates how to evaluate the performance of a binary classification model using the confusion matrix and classification report functions from the scikit-learn library.
In the first step, the code defines two lists: 'actual_values' contains the actual labels for a set of samples, and 'pred_values' contains the predicted labels for the same samples.
Then, the code uses the 'confusion_matrix' function to calculate the confusion matrix for the predicted and actual labels, and stores the resulting matrix in the 'conf_matrix' variable. The 'labels' parameter is set to [0,1] to specify the two classes.
Next, the code extracts the true positive, false negative, false positive, and true negative values from the confusion matrix using the 'reshape' function and stores them in separate variables. These values provide insights into the types of errors the model is making.
Finally, the code generates a classification report using the 'classification_report' function, which shows the precision, recall, f1-score, and support for each class. The 'labels' parameter is again set to [0,1] to specify the two classes.
Overall, this code shows how to use the confusion matrix and classification report to evaluate the performance of a binary classification model and obtain useful metrics for each class.
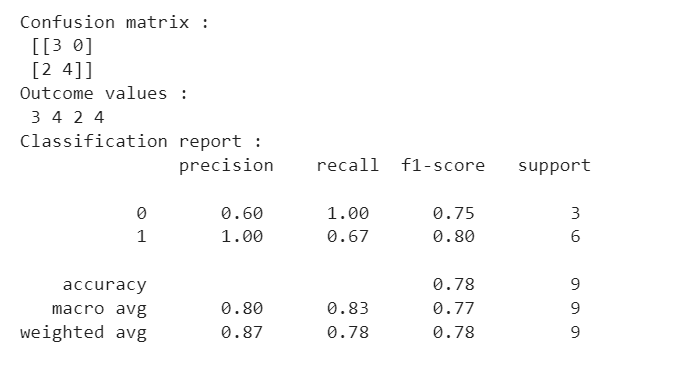
Output
The output of the code provides different metrics to evaluate the performance of a binary classification model.
The first metric is the confusion matrix, which shows the number of true positives, true negatives, false positives, and false negatives for the predicted and actual labels.
The second metric provided by the code is the classification report, which shows the precision, recall, f1-score, and support for each class. Check out this problem - First Missing Positive
Frequently Asked Questions
What can we decipher from a confusion matrix?
A confusion matrix can help us explain the predictions of positive and negative classes that help us decipher different performance metrics.
When should we use a confusion matrix?
A confusion matrix is very useful in the case of classification problems, etc.
Can we use a confusion matrix for regression models?
The confusion matrix is not generally used for regression models. We deal with discrete outcomes while using a confusion matrix.
Why is it called a confusion matrix?
The term "confusion matrix" refers to a table that compares the predicted and actual labels in a dataset, providing insights into the performance of a machine learning algorithm. The name comes from the fact that the matrix helps to quantify the confusion or mix-up of labels that the model is experiencing.
How can the confusion matrix be used to improve the performance of a machine learning model?
The confusion matrix can be used to identify the types of errors the model is making and to adjust the model's parameters or features accordingly. For example, if the model is producing too many false positives, the threshold for classification can be adjusted to reduce these errors.
Conclusion
In conclusion, confusion metrics provide valuable insights into the performance of a classification model. Different metrics may be more relevant depending on the scenario and the cost of different types of errors. By analyzing these metrics, we can identify the strengths and weaknesses of the model and adjust our approach to improve its performance in real-world applications.
We hope this blog has helped you enhance your knowledge of the confusion matrix and its use cases. If you want to enhance more, then check out our blogs.































 8+ registered
8+ registered 

