Do you think IIT Guwahati certified course can help you in your career?
Introduction
In this blog, we will discuss the Connectors. But before discussing Connectors, we should first look at Big Data. Further, we will discuss Big Data types, and Integrating data types into a big data environment. This will develop a good understanding of Connectors, so let’s dive straight into the blog.
Big Data
Big data refers to more diverse data that arrives in higher amounts and moves faster. The three V's is another name for this. Big data refers to larger, more complicated data sets, particularly those derived from new sources. These data sets are large, and general data processing technologies can't handle them. Large amounts of data can be leveraged to solve business challenges you previously couldn't solve. Although businesses have been gathering massive amounts of data for decades, the term "Big Data" only became popular in the early to mid-2000s. Corporations acknowledged the vast amount of daily data and the need to utilize it successfully.
Data connectors are processes that pull data from a source site and write it to a destination place regularly. A data connector's objective is to gather data from many sources and load it into a destination on a regular basis. Data connectors are becoming an important aspect of data engineering and help organizations' fantastic data analytics teams. You want to have some connectors to pull data in from various big data sources. Maybe you want a Twitter connector or a Facebook one. Perhaps you need to integrate from your data warehouse with a big data source that's off your premises to analyze both of these sources of data together.
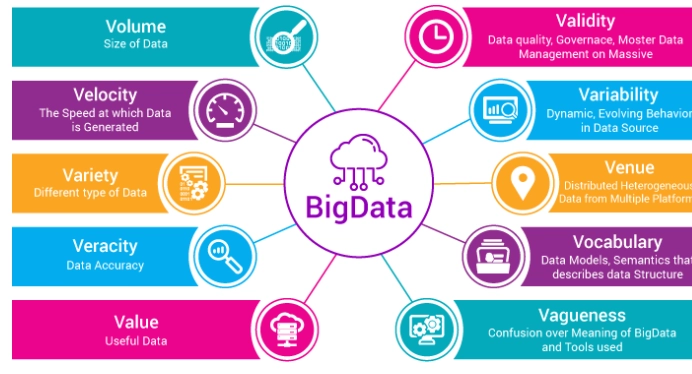
Before you can start planning for big data integration and use connectors, you need to figure out what kind of data you're dealing with. Many businesses realize that much internally generated data hasn't been fully utilized in the past. Big data is a massive set collection of data sets that can't be analyzed, processed, or stored with conventional technologies. Messages, videos, photographs, and other data types are included in this data. Volume, Velocity, and Variety are the three "Vs" of big data. Big data makes way for virtually any understanding a company requires, whether predictive, diagnostic, descriptive, or prescriptive analytics. Data analysis and harvesting have been recognized for a long time, if not hundreds of years, and the domain of big data analytics is built on the shoulders of monsters.
Categorizing Big Data
Structured Data
Structured data is data that can be processed, accessed, and stored in a fixed format. Over time, software engineering expertise has made significant progress in developing strategies for working with this type of data and inferring its benefit. Nonetheless, we are predicting challenges in the future when the size of such data grows to enormous proportions, with average quantities approaching zettabytes.
Unstructured Data
Unstructured data is one of the types of big data that incorporates the data format of a large number of unstructured files, such as image files, audio files, log files, and video files. Unstructured data refers to data that has an unfamiliar structure or model. Because of its magnitude, unstructured data in big data presents unique challenges in preparation for evaluating a value.
Semi-structured Data
Semi-structured data is one of the types of big data that includes both unstructured and structured data formats. To be more explicit, it alludes to data with crucial tags or information that isolate single components within the data, although it has not been sorted under a specific database. Along these lines, we've reached the end of enormous data kinds.
Subtypes of Data
Even though not formally classified as big data, there are subtypes of data relevant to analytics. These frequently refer to the beginning of the data, such as social media, machine learning, geospatial, or event-triggered data. These subtypes can also refer to different levels: linked, lost/dark, and open.
Integrating data types into a big data environment
Data integration is a set of techniques for acquiring and merging data from several sources in order to create new information. A broad data integration solution provides reliable data from a range of sources. In traditional data integration methodologies, the ETL (extract, transform, and load) procedure was used to ingest and clean data before loading it into a data warehouse.
Dimensions of Data Integration
Volume: This is the primary characteristic of big data. The number of connected devices and people is higher than ever before, which has had a significant impact on the number of data sources and the amount of data available globally. Velocity: The rate of data generation increased dramatically as the number of data sources expanded, notably following the introduction of social media and the use of IoT. Variety: We have a more comprehensive range of data storage formats with more data sources. We have high-level structured and unstructured data. There are many different forms for each type: text, photos, audio, XML, documents, spatial data, etc. Veracity: When of the features described above, we have varying data quality, and we can come across ambiguous or imprecise data, mainly because social media and blogs allow people to distribute this type of information.
Big Data Integration
In comparison to a traditional relational database, the pieces of the big data platform manage data in novel ways. Big Data Integration maintains both organized and unstructured data and also helps in scalability and increasing performance. From Hadoop to NoSQL databases, each component of the big data ecosystem has its method for extracting, manipulating, and loading data.
The data must be trusted and understood at all levels of the organization to make appropriate business decisions based on big data analysis. It must be supplied to the business in a trusted, controllable, consistent, and flexible way throughout the organization.
Techniques for Data Integration
Schema Mapping
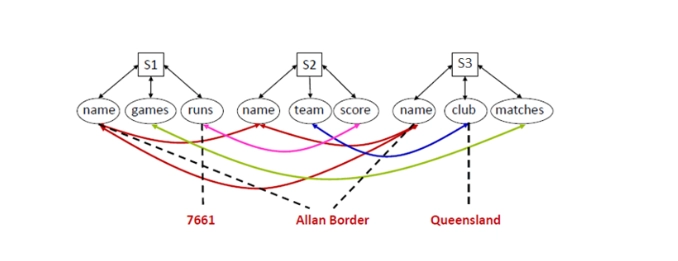
Schema Mapping can be thought of as a two-phase procedure. To determine which (sets of) characteristics contain the same information, create a mediated (global) schema, then identify the mappings between the local schema of the data sources and mediated schema.
The picture below depicts mapping between schema on querying attributes.
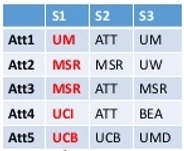
It would be great if you were convinced that the outcomes of combining unstructured and big data sources with structured operational data would be relevant. Data fusion is a set of approaches aimed at resolving conflicts from various sources and determining the truth that reflects reality. It's a new field that's only lately emerged. Its motive is data integrity: the Internet has made it exceedingly easy to publish and propagate erroneous information across various sources, making separating the wheat from the chaff vital for presenting high-quality data. Three types of Data Fusion are Copy detection, Voting, and Source quality. The picture below depicts the importance of common attributes by highlighting and giving them more weight.
Record linkage is a task that involves identifying records that refer to the same logical entity across several data sources, especially when standard identifiers are not shared (like the SSN for persons). Traditional data integration focuses solely on the connection of structured data. Data sources are heterogeneous in their structures and are collected from various sources (social media, sensor logs, etc.) that give unstructured text data. Data sources are dynamic and constantly growing in Big data integration.
Techniques used in Record Linkage
Pairwise Matching: This method examines if two records belong to the same logical entity by comparing them.
Clustering: This technique ensures that each partition belongs to a separate entity by arriving at a globally consistent conclusion on the relevant records partitioning.
Blocking: This method divides the input records into numerous blocks, allowing only pairwise matching between entries in the same block.
FAQs
What is Big Data?
Big data refers to collections that are too massive or complicated for typical data-processing application software to handle. Data with more fields have more statistical power; however, data with more lots have a higher false discovery rate.
What is distributed computing?
The subject of computer science known as distributed computing explores dispersed systems. A distributed system is one in which the components are spread across multiple networked computers and communicate and coordinate their actions by transferring the messages from one system to another.
What are Connectors in Big Data?
A data connector's objective is to gather data from many sources and load it into a destination on a regular basis. Data connectors are becoming an important aspect of data engineering and help organizations' fantastic data analytics teams.
Conclusion
This article briefly discussed big data, Connectors, Examining Big Data Types and integrating data types into a big data environment.
I hope you have gained some insight into this topic of connectors, and by now, you must have developed a clear understanding of them. You can learn more about such topics on our platform Coding Ninjas Studio.
You can refer to our guided paths on Coding Ninjas Studio to learn more about DSA, Competitive Programming, JavaScript, System Design, SQL problems, etc. Enroll in our courses and refer to the mock test and problemsavailable, interview puzzles, look at the interview experiences, and interview bundles for placement preparations.
Thank you for reading.
Live masterclass
Zomato Data Analysis Case Study: Ace 25L+ Roles in FoodTech
by Abhishek Soni
16 Mar, 2026
01:30 PM
Data Analysis for 20L+ CTC@Flipkart: End-Season Sales dataset
by Sumit Shukla
15 Mar, 2026
06:30 AM
Beginner to GenAI Engineer Roadmap for 30L+ CTC at Amazon
by Shantanu Shubham
15 Mar, 2026
08:30 AM
Multi-Agent AI Systems: Live Workshop for 25L+ CTC at Google
by Saurav Prateek
16 Mar, 2026
03:00 PM
Zomato Data Analysis Case Study: Ace 25L+ Roles in FoodTech
by Abhishek Soni
16 Mar, 2026
01:30 PM
Data Analysis for 20L+ CTC@Flipkart: End-Season Sales dataset





























 40+ registered
40+ registered 

