


























Introduction
A Convolutional neural network is an artificial neural network that takes input images and assigns weights to various objects in the embodiment to differentiate one appearance from the other.
An artificial neural network consists of three layers, an input layer, a hidden layer, and the output layer.
All the inputs are taken from the input layer. Processing is done inside the hidden layer, and the output is received through the output layer.
Source: researchgate.net
I will implement a Convolutional neural network using Keras with TensorFlow as the backend. I am using the MNIST handwritten digit dataset to build a digit classifier.
Also Read, Resnet 50 Architecture
Implementation
I import the libraries, sequential models from the Keras model. Also, we need to import dense, Dropout, Activation, and flatten from the Keras layer. For the convolutional layer, I am importing convolution2D, and for the max-pooling layer, I import MaxPooling2D.
To validate our model, we'll need a train test split, so I'll be using the one from sci-kit learn. We need to import pandas and NumPy as well.
from keras.models import sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
The data is available in CSV, and I will import it using pandas.
You can download the data set from here.
data = pd.read_csv('mnist.csv')
Let’s have a look at the first few rows of the data.
data.head()

We will have to modify it a bit to be able to feed it into our convnets. All the pixels are arranged in rows, and we need an image to be represented as a matrix to work on it. So let's reshape the array using the reshape function. I will reshape it to 28 x 28 x 1. 28 - height, 28- width, 1- channel.
data.iloc[3,1:].values.reshape(28,28).astype('unit8')
I create two lists; one is to store the images, and the other is to keep the labels.
# storing pixel array in form of length width and channel in df_x
df_x = data.iloc[:,1:].values.reshape(len(data),28,28,1)
# storing the labels in y
y = data.iloc[:,0].values
We need our labels to be categorical variables. Currently, they are represented as one, two, three, and so on. And this is the problem for us.
#converting labels to categorical features
df_y = kers.utils.to_categorical(y, num_classes=10)
Keras has two categorical functions, which take in our labels and the number of classes and transform them into categorical labels. And once we are done, let's convert everything to NumPy arrays and check the shape.
df_x = np.array(df_x)
df_y = np.array(df_y)
print(y)

print(df_y)

Keras has two categorical functions which takes in our labels and the number of classes and transforms it to categorical labels. And once we are done let’s convert everything to numpy arrays and check the shape.
df.x_shape

I will split the data set into test and train, and we are done with preprocessing the data for feeding it into CNN or Convolutional Neural Network.
x_train, x_test, y_train, y_test = train_test_split(df_x, df_y, test_size = 0.2, random_state = 1)
Let's start implementing our convolutional neural network model in Keras. We need a convolutional layer that will take 28 x 28 images as input and let the convolutional layer have 32 filters, each of size 3x3. Let's take activation as RELU so that we won't have to add a normalization layer separately. Let's add a max-pooling layer of size 2x2 and then flatten it up into a neural network and let the next layer of the neural network have 100 nodes, and the output layer of the neural network will have ten nodes.
model = Sequential()
model.add(Convolution(32,3,data_format = 'channels_last', activation = 'relu', input_shape(28, 28, 1)))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Flatten())
model.add(Dense(100))
model.add(Activation('softmax'))
model.add(Dropout(0.5))
model.add(Dense(10))
We compile it with Loss function categorical cross-entropy. The loss function will calculate the error in the prediction.
model.compile(loss = 'categorical_crossentropy', optimizer = 'adadelta', metrics = ['accuracy'])
Typing model summarizes the model, where we can confirm the input and output shapes.
model.summary()

Now, let's train the model. I used a fit function and passed the training data, and I passed test data for validation.
model.fit(x_train, y_train, validation_data = (x_test, y_test))
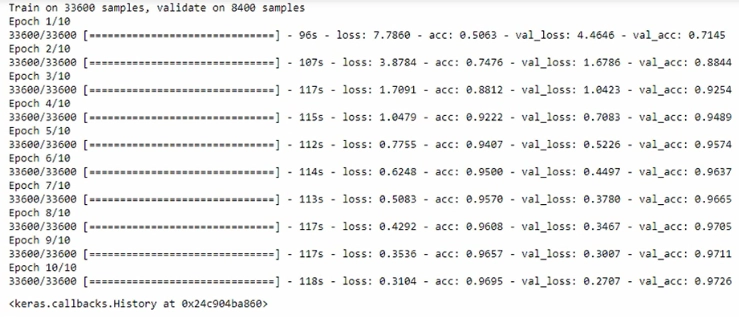
Loss continuously falls, and ideally, we need to run the model until the loss doesn't change any more. As the loss decreases, the accuracy keeps increasing.
We can use model.predict for prediction.
model.evaluate(x_test, y_test)

The accuracy of the model is 97%.
Check out this article - Padding In Convolutional Neural Network

 8+ registered
8+ registered 

