Intuition
We need to solve this problem in two parts, the first part for the first type of query and the second part for the second type of query.
- In the first type of query, we can change the node’s value in a constant operation.
- In the second type of query, we must implement a separate function for the dfs traversal on the tree, where dfs traversal is required to find the path between two nodes. After finding the nodes on the path from the first to the second node, we can check for the gcd and count the nodes having gcd as 1.
Algorithm
- In the main function itself, the first query can be handled, whereas, for the second query, we will require a second function.
- For the second query, function countNodes() will count the number of nodes whose values satisfy the given condition in the query.
- We will also need a void function dfs() to obtain the path between two nodes. After the function dfs() returns the path, we will check for the node values having gcd with the given number as 1.
Below is the implementation of the above algorithm.
Implementation
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// Variables and vectors to store the provided data.
int N, Q, x, y, a, b, c;
vector<int> val, vis, tmp;
vector<vector<int>> grph;
// The dfs function used to find the path between two nodes.
void dfs(int node, int par, int final)
{
vis[node] = 1;
// If reached the final node.
if(node==final)
{
// Storing the path.
for(int i=1;i<=N;i++)
{
if(vis[i])
tmp.push_back(val[i]);
}
return;
}
// Finding the path with other nodes.
for(auto t: grph[node])
{
if(t==par)
continue;
dfs(t, node, final);
}
vis[node] = 0;
}
// Function to count the number of nodes satisfying the condition.
int countNodes(int a, int b, int c)
{
// Preparing the vectors to store the path between node a and b.
tmp.clear();
vis = vector<int>(N+1,0);
// Running the DFS.
dfs(a, -1, b);
// Finally counting the number of nodes.
int cnt=0;
for(int i=0;i<tmp.size();i++)
{
int d = tmp[i];
if(__gcd(c,d)==1)
cnt++;
}
return cnt;
}
// Main function.
int main()
{
// Input of variables.
cin>>N>>Q;
// Resizing the vectors.
val = vector<int>(N+1);
grph = vector<vector<int>>(N+1, vector<int>(0));
// Input of node values.
for(int i=1;i<=N;i++)
cin>>val[i];
// Input of tree edges.
for(int i=0;i<N-1;i++)
{
cin>>x>>y;
grph[x].push_back(y);
grph[y].push_back(x);
}
// Finally solving the queries.
for(int i=0;i<Q;i++)
{
cin>>y;
if(y==1)
{
cin>>a>>b>>c;
cout<<countNodes(a, b, c)<<endl;
}
else
{
// If the first type of query.
cin>>a>>x;
val[a] = x;
}
}
return 0;
}

You can also try this code with Online C++ Compiler
Input
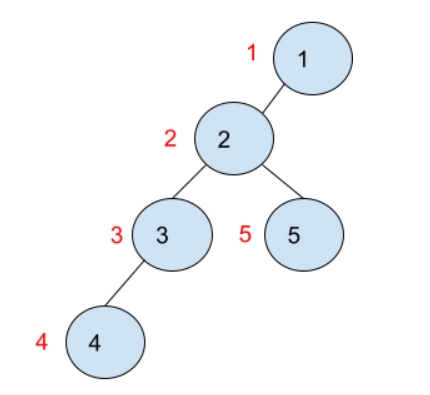
6 4
2 3 1 6 8 10
1 2
1 3
3 4
2 5
1 6
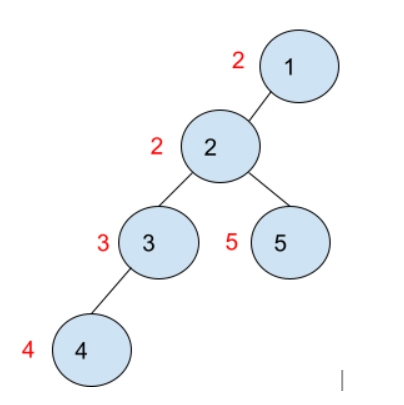
1 1 3 2
0 3 4
1 1 3 2
1 1 4 2
Output
1
1
1
Complexity Analysis
Time complexity
O(N * Q), where ‘N’ is the number of nodes, and ‘Q’ are the number of queries.
Explanation: As we understood that solving the first query is done at a constant time whereas, for the second query, a dfs run is required whose worst complexity is O(N), where ‘N’ is the number of nodes. And for ‘Q’ such queries, the time complexity sums up to O(N * Q).
Space complexity
O(N), where ‘N’ is the number of nodes.
Explanation: On running the dfs, vectors ‘vis’ and ‘tmp’ are required whose size is not going to exceed ‘N’, thus its O(N).
FAQs
-
What is a tree?
A collection of nodes connected by means of “edges,” which are either directed or undirected, is called the tree. “Root node” is one of the specific nodes, and the remaining nodes are called the child nodes or the leaf nodes of the root node.
-
What is DFS?
DFS stands for Depth-first search. This algorithm was designed for traversing or searching tree or graph data structures. It starts at the root node and explores as far as possible along each branch before backtracking in a very time-efficient manner.
-
Why is DFS used in the above algorithm?
We needed an algorithm to find out the path between two nodes, so we used the DFS algorithm as it is very time and space-efficient.
-
What will be the time complexity of the above algorithm if the second query is removed?
The auxiliary time complexity will be O(1), as we are just changing the node’s value, which can be done in a constant time.
-
What is the time complexity to run a DFS algorithm on a tree?
DFS algorithm takes O(N) time, where ‘N’ is the number of nodes in the tree. That is why DFS is considered one of the most efficient traversal algorithms.
Key Takeaways
The above problem is an interesting competitive programming problem involving trees and DFS Algorithm. Solving these types of problems is the key to boosting your problem-solving skills.
Recommended Problems:
Find more such interesting questions on our practice platform Coding Ninjas Studio if you want to learn more before jumping into practising, head over to our library section for many such interesting blogs. Keep learning.
Happy Coding!






























 9+ registered
9+ registered 

