Do you think IIT Guwahati certified course can help you in your career?
Introduction
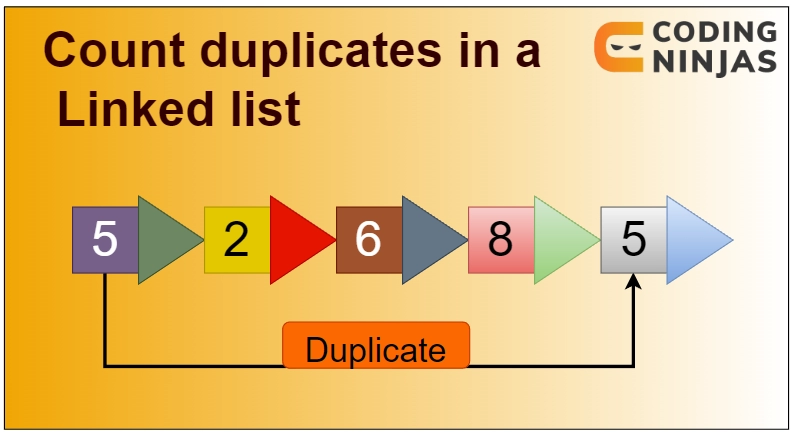
In this blog, we will take up a problem based on Linked lists. Linked lists are popularly asked data structures in coding assessments and interviews. There are various standard problems based on Linked lists, for example, reverse a Linked list, check if a linked list contains a cycle, etc. This blog will discuss a similar problem - counting the number of duplicated nodes in a linked list.
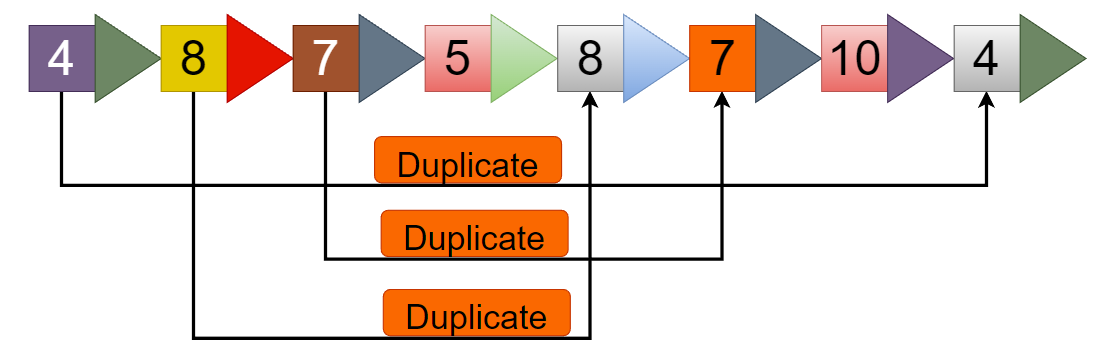
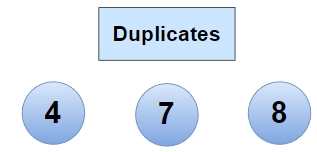
In the given linked list, the values of the 5th, 6th, and 8th nodes are already present in the linked list before. Hence the output is 3.
Approach 1 Brute Force
A straightforward approach would be to individually consider each node of the linked list. Start from each node and move ahead in the linked list. If you encounter a node with the same value as the node in consideration, it would mean that the current node is duplicated. In such a case, increase the count by one and break.
Algorithm
Create a function countDuplicates which takes the head of a linked list as an argument.
The simple nested loop that iterates over each node in the linked list and, for each node, iterates over all the nodes that follow it. Each pair of nodes with the same value increments a counter to count the number of duplicates.
Return the count.
Dry Run
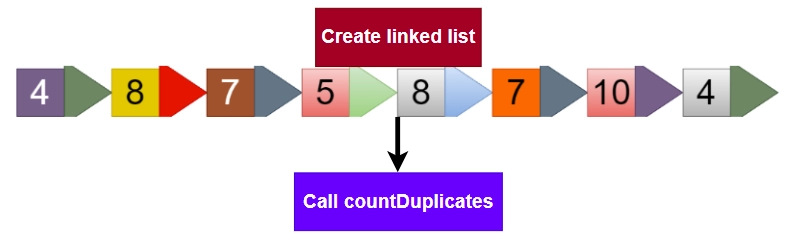
For the given input, the linked list will be created with the following nodes:
4 -> 8 -> 7 -> 5 -> 8 -> 7 -> 10 -> 4 -> NULL
Call the countDuplicateNodes() function with the head pointer of the linked list as an argument.
The function will iterate through the linked list and count duplicate nodes (nodes with the same value as another node).
The function will return the count of duplicate nodes, which in this case is 3.
Print the returned count to the console.
C++ Implementation
#include <iostream>
using namespace std;
struct Node {
int value;
Node* next;
};
Node* createNode(int value) {
Node* newNode = new Node();
newNode->value = value;
newNode->next = NULL;
// Return a pointer to the new node
return newNode;
}
// insert a new node
void insertNodeAtEnd(Node** head, int item, Node** rear) {
// Create a new node with the given item
Node* temp = createNode(item);
if (*head == NULL) {
// If linked list is empty, set both head and rear pointers to the new node
*head = temp;
*rear = temp;
return;
}
// Otherwise, append the new node to the end of the linked list
(*rear)->next = temp;
*rear = (*rear)->next;
}
int countDuplicateNodes(Node* head) {
int count = 0;
Node* current = head;
// Iterate through each node in the linked list
for (; current != NULL; current = current->next) {
Node* runner = current;
// Compare the current node with all the nodes that follow it
for (; runner->next != NULL; runner = runner->next) {
if (runner->next->value == current->value) {
// If a duplicate is found, increment the count
count++;
}
}
}
// Return the count of duplicate nodes
return count;
}
int main() {
// Initialize the head and rear pointers to NULL
Node* head = NULL, *rear = NULL;
// Insert some nodes at the end of the linked list
insertNodeAtEnd(&head, 4, &rear);
insertNodeAtEnd(&head, 8, &rear);
insertNodeAtEnd(&head, 7, &rear);
insertNodeAtEnd(&head, 5, &rear);
insertNodeAtEnd(&head, 8, &rear);
insertNodeAtEnd(&head, 7, &rear);
insertNodeAtEnd(&head, 10, &rear);
insertNodeAtEnd(&head, 4, &rear);
// Count and print the number of duplicate nodes in the linked list
cout << countDuplicateNodes(head) << endl;
// Return zero to indicate success
return 0;
}
You can also try this code with Online C++ Compiler
In the above implementation it defines a linked list with a struct Node that has an integer value and a pointer to the next node. The code inserts some values into the linked list using the insertNode() function and then counts the number of duplicate nodes using the countDuplicates() function.
For example, the linked list created by this code is as follows:
4 -> 8 -> 7 -> 5 -> 8 -> 7 -> 10 -> 4 -> NULL.
The countDuplicates() function will then traverse the linked list and count the number of nodes with duplicate values. In this case, there are 3 duplicate nodes with the value of 8 and 7 and 4 so the function will return 3.
Complexity
Time Complexity
The time complexity of the above approach is O(n^2), as the program uses two nested for loops to count the number of duplicates.
Space Complexity
The space complexity of the above approach is O(1), as we are using constant memory during runtime.
Approach 2
This approach uses hashing to achieve the task in O(n) time. We can use unordered_set to track the values we have encountered so far. We can traverse the linked list from its beginning to end. When we visit a node, we will check if the node's value has been encountered before. If yes, increase the count by one. Otherwise, insert the value into the unordered_set.
Algorithm
Create a function countDuplicates which takes the head of a linked list as an argument.
Create an unordered_set alreadyEncountered to store the elements as we traverse the linked list.
Insert the value of the head node into alreadyEncountered. Update head as head->next.
Start traversal of the linked list from the newly updated head node and check the following condition.
If the value of the current node is present in alreadyEncountered, increase the count by one. Otherwise, insert the value into alreadyEncountered.
Return count.
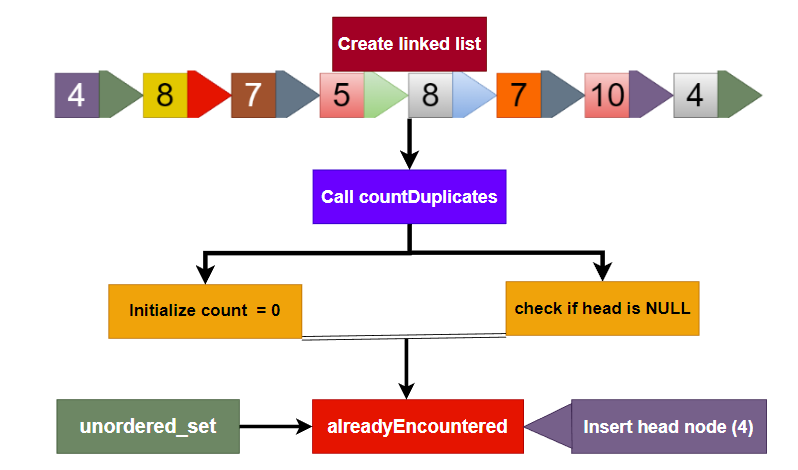
Dry Run
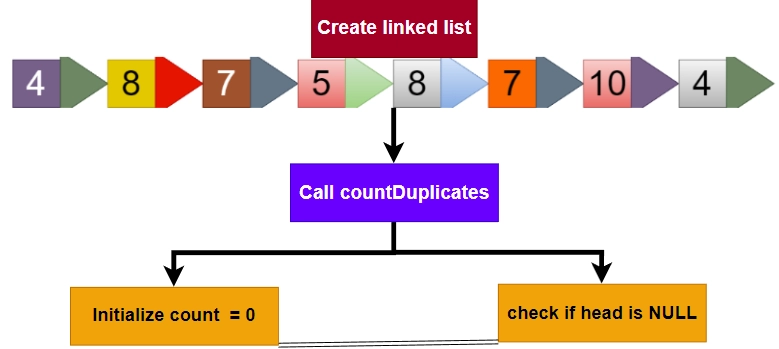
In the first step we will create a linked list with the following values: 4, 8, 7, 5, 8, 7, 10, 4.
In second step we call the countDuplicates function with the head of the linked list as the argument.
In third step Initialize the count variable to 0 and check if the head node is NULL.
In the fourth step create an unordered_set called alreadyEncountered.
Here, in the fifth step, Insert the value of the head node into the alreadyEncountered set.
In the sixth step, move to the next node by setting head equal to head->next.
In the seventh step, Loop through the rest of the linked list until head is NULL.
In the eighth step for each node, check if its value is already in the alreadyEncountered set.
Then if the value is already in the set, check if it has already been counted as a duplicate. If not, increment the count variable and remove the value from the set.
Here If the value is not already in the set, insert it into the set.
Now return the count of duplicate nodes. In this case, 4, 8 and 7 are duplicates.
Finally, print the result of the countDuplicates function, which is 3 in the above case.
C++ Implementation
#include<iostream>
#include<unordered_set>
using namespace std;
struct Node{
int val;
Node* next;
};
// Here we are creating a new linked list node with the given value.
Node* createNewNode(int val) {
Node* newNode = new Node();
newNode->val = val;
newNode->next = NULL;
return newNode;
}
// Inserting a new node with the given value at the end of the linked list.
void insertNodeAtEnd(Node** head, int val, Node** tail)
{
// Create the new node.
Node* temp = createNewNode(val);
// If the linked list is empty, set both head and tail to the new node.
if(*head == NULL){
*head = temp;
*tail = temp;
return;
}
(*tail)->next = temp;
// Update the tail pointer.
*tail = (*tail)->next;
}
//Duplicate function.
int countDuplicateNodes(Node* head)
{
// Use an unordered set to keep track of unique values seen so far.
unordered_set<int> uniqueValues;
int count = 0;
while (head != NULL){
// If the current node's value has already been seen, increment the count of duplicate nodes.
if (uniqueValues.find(head->val) != uniqueValues.end()) {
count++;
} else {
// Otherwise, add the current node's value to the set of unique values.
uniqueValues.insert(head->val);
}
head = head->next;
}
// Return the count of duplicate nodes.
return count;
}
int main()
{
//linked list.
Node* head = NULL, *tail = NULL;
// Insert nodes
insertNodeAtEnd(&head,4,&tail);
insertNodeAtEnd(&head,8,&tail);
insertNodeAtEnd(&head,7,&tail);
insertNodeAtEnd(&head,5,&tail);
insertNodeAtEnd(&head,8,&tail);
insertNodeAtEnd(&head,7,&tail);
insertNodeAtEnd(&head,10,&tail);
insertNodeAtEnd(&head,4,&tail);
cout <<countDuplicateNodes(head)<< endl;
return 0;
}
You can also try this code with Online C++ Compiler
The program then defines a function createnode which takes an integer value as input and returns a new node with the specified value and a NULL next pointer.
The insertNode function is used to insert a new node with the given value at the end of the linked list. It takes the head and rear pointers of the linked list as input and updates them accordingly. The head and rear pointers are set to the new node if the linked list is empty.
The countDuplicates function counts the number of duplicate nodes in the linked list using an unordered set. It starts by initialising a counter variable to zero and checking if the head pointer is NULL. If it is, the function returns zero. Otherwise, it initialises an unordered set to store the values of the nodes that have been encountered so far. It then inserts the value of the head node into the set and moves to the next node. For each subsequent node, it checks if the value is already present in the set. If it is, it checks if the value has been counted as a duplicate before. If it hasn't, it increments the counter and removes the value from the set. If the value is not present in the set, it inserts it. Finally, the function returns the counter variable.
Complexity
Time Complexity
The time complexity of the above approach is O(n), as the program uses the find function of unordered_set (defined in C++ STL), which has O(1) time complexity. Since we make n such calls, the total time complexity is O(n).
Space Complexity,
The space complexity of the above approach is O(n), as the size of the unordered_set can grow to the order of n when all the nodes have unique values.
Frequently Asked Questions
How do you traverse a linked list?
To traverse a linked list, you start at the head node and follow the next pointers until you reach the end of the list.
What is a duplicate node in a linked list?
A duplicate node in a linked list is a node that has the same value as another node in the list.
How do you count the number of duplicate nodes in a linked list?
To count the number of duplicate nodes in a linked list, you can traverse the list and compare the value of each node with the values of the nodes that come after it.
How does the nested loop approach for counting duplicate nodes work?
The nested loop approach compares each node in the linked list with all the nodes after it.
Explain hashing and working for counting duplicate nodes?
The hashing technique used to map data of arbitrary size to fixed size data. To count duplicate nodes using hashing, we use an unordered_set to store the values of the nodes we have already encountered. If we meet a node whose value is already in the set, we know it is a duplicate.
Conclusion
In this blog, we discussed a problem based on Linked lists. We saw two different approaches to count the number of duplicate nodes in a linked list. The first approach had a time complexity of O(n^2), while the second approach used hashing to achieve an O(n) time complexity. We also saw the corresponding code implementations of both approaches in C++. Overall, understanding and solving Linked list problems are crucial in coding assessments and interviews, and these two approaches can serve as a good starting point for beginners to practice and improve their coding skills.
Yet learning never stops, and there is a lot more to learn.
To study more about Linked Lists, refer to Applications Of Linked Lists. So head over to our practice platform Coding Ninjas Studio to practice top problems, attempt mock tests, read interview experiences, and much more. Till then, Happy Coding!




































 8+ registered
8+ registered 

